






1.Text
2.CSV
3.Excel
4.Html
5.Mysql
6.Mongodb
1.启动jupyter notebook
2.创建一个新的notebook,并导入pandas

一:txt
1.read_table()读取文本格式的内容,当前目录有01.txt,内容为:
email
jack@example.com
mary@example.com
lily@example.com
tom@example.com
读取01.txt中的内容
pd.read_table("./01.txt")
运行效果图如下:
2.read_table()读取多列数据时,每列之间用tab键间隔,02.txt内容为:
name age email
jack 18 jack@example.com
mary 19 mary@example.com
lily 17 lily@example.com
tom 17 tom@example.com
joe 20 joe@example.com
读取02.txt中的内容:
pd.read_table("./02.txt")
运行效果图如下:

3.指定分隔符读取文本,且没有头,03.txt内容为:
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
读取03.txt的内容:
pd.read_table('./03.txt',sep=':',header=None)
运行效果图如下:

指定每一列的名字
pd.read_table('./03.txt',sep=':',names=['name','pwd','uid','gui','local','home','shell'])
运行效果图如下:

二:CSV
说明:逗号分隔值文件格式
1.在当前目录下,有04.csv,内容为:
书名,单价
时间简史,30.9
胡诗全集,45.9
钢铁是怎样炼成的,60
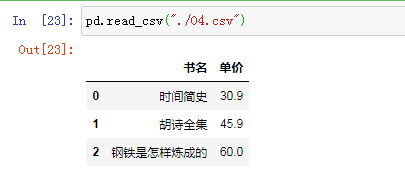
读取04.csv文件内容:
pd.read_csv("./04.csv")
运行效果图如下:
备注:若运行报错,可能是编码格式问题导致,可以先将文件编码格式转化为utf8,再运行
三:Excel
1.安装xlrd模块: pip install xlrd

2.当前文件夹下面,有05.xlsx内容为:
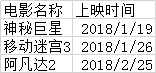
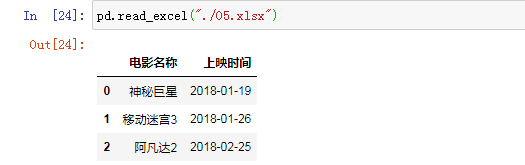
读取Excel表格中的内容:
pd.read_excel("./05.xlsx")
运行效果图如下:
四:HTML
1.安装lxml,pip install lxml

2.当前目录下有06.html,内容为:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>2017年中国个城市平均工资排行榜</title>
</head>
<body>
<h1>2017年中国个城市平均工资排行榜</h1>
<table class="mydata">
<tr>
<th>排名</th>
<th>城市</th>
<th>工资</th>
</tr>
<tr>
<th>1</th>
<th>北京</th>
<th>9240</th>
</tr>
<tr>
<th>2</th>
<th>上海</th>
<th>8962</th>
</tr>
<tr>
<th>3</th>
<th>深圳</th>
<th>8315</th>
</tr>
<tr>
<th>3</th>
<th>广州</th>
<th>7409</th>
</tr>
<tr>
<th>3</th>
<th>杭州</th>
<th>7330</th>
</tr>
</table>
<hr>
<table class="mydata2">
<tr>
<td>aa</td>
<td>bb</td>
<td>cc</td>
</tr>
<tr>
<td>11</td>
<td>22</td>
<td>33</td>
</tr>
<tr>
<td>44</td>
<td>55</td>
<td>66</td>
</tr>
</table>
</body>
</html>
页面效果图:

读取06.html的内容:
tables = pd.read_html("./06.html",header=0)
tables
运行效果图如下:

备注:如果lxml没有生效,可以点击Kernel -> restart and Run All 重新运行notebook
3.通过索引获取两个不同的table
#1.获取第一个table
tables[0]
#2.获取第二个table
tables[1]
运行效果图如下:

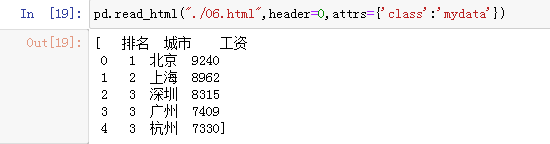
4.使用attr属性指定表格的类
pd.read_html("./06.html",header=0,attrs={'class':'mydata'})
运行效果图如下:
五:MySQL
1.安装pymysql
2.导入pymysql
import pymysql
3.创建连接,并读取mysql表中的内容
conn = pymysql.connect(host='localhost',user='root',password='123456',db='test',charset='utf8')
sql = 'select * from students'
data = pd.read_sql(sql,conn)
conn.close()
4.输出读取的内容
data
运行效果图如下:

六:Mongo
1.安装pymongo: pip install pymongo
2.导入import pymongo
import pymongo
3.创建连接,并查询Mongo中的数据
client = pymongo.MongoClient('localhost',27017)
db='weibo'
table='weibo'
cursor = client[db][table].find()
4.将数据保存在data中
data = pd.DataFrame(list(cursor))
5.输出数据
data
运行效果图如下:
















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









