






总结:
1.head 前面5条数据
2.tial 后面5条数据
3.info 数据类型相关信息
4.describe 查看数据的详细信息
5.count 计算数据的个数
6.mean 平均值
7.sum 求和
8.cumsum 累计求和
9.std 标准差
10.var 极差
12.max 最大值
12.min 最小值
13.quantile 分位数
1.启动jupyter notebook
2.创建一个新的notebook,并导入pandas

3.创建一个DataFrame数据
data = [
[1,None],
[4,5],
[None,None],
[8,9],
[3,4]]
df = pd.DataFrame(data,columns=['a','b'])
df
运行效果图如下:

4.df.head()默认显示前5行数据,df.head(2)显示前2行数据

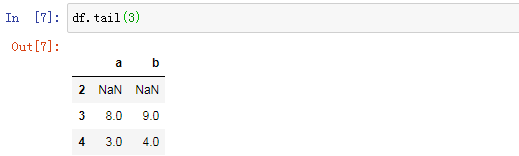
5.df.tail()默认显示最后5行数据,df.tail(3)显示后3行数据
6.df.info()显示变量数据类型相关的内容:

7.df.describe()查看数据详细信息

count:有效数据个数 mean:平均数 std:中位数 min:最小值 max:最大值 25%:四分位数 50%:中位数 所有参数都是将空值排除在外
8.df.count()获取数据有效值个数,比如:a列4个有效值,b列3个有效值

9.df.mean()获取平均值

10.df.sum()求和,默认求列的和

df.sum(axis = 1),横向求和

11.对Series对象(DataFrame的一列)进行求和,比如df.a.sum()

12.累加求和:df.cumsum(),1+4=5+8=13+3=16

13.df.std()获得标准差

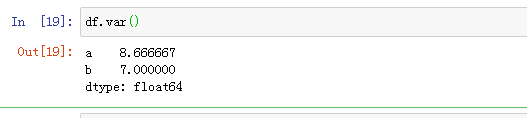
14.df.var()获得方差
15.df.max()获取最大值,df.min()获取最小值

16.四分位数df.quantile(0.25),下四分位数df.quantile(0.75),df.quantile(0.5)中位数
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









