






以前的文章讲了使用mutate_all(),mutate_at(),mutate_if()操作数据框的列,今天来讲讲使用filter_all(),filter_at(),filter_if()筛选数据框的行。使用过R,尤其是其中dplyr包的同学,对filter()这个函数不会陌生,filter_all(),filter_at(),filter_if()其实属于filter()更高级的用法,可以更有效地提高数据清洗的效率。这三者之间的区别和mutate_all(),mutate_at(),mutate_if()之间的区别相似。 filter_all() 作用于所有变量。filter_at()作用于按条件筛选后的变量。filter_if()作用于按条件筛选后的变量。
在这里我们以R的另一个数据集USArrests为例,这是美国50个州的犯罪指标,是一个50行4列的数据集,具体数值代表什么,我也不知道,只知道是American的数据就好了,不妨碍咱们对它做探索。
USArrests数据集长这样
我们先用filter_all()筛选出大于5的行,在使用filter_all()之前,我们要区分其中参数any_vars和all_vars的用法,简单地说,any_vars是用“或”(“|”)连接所用变量,而all_vars是用“且”(“&”)连接所有变量。
data_1=filter_all(USArrests,any_vars(.>5))得到的数据集长这样
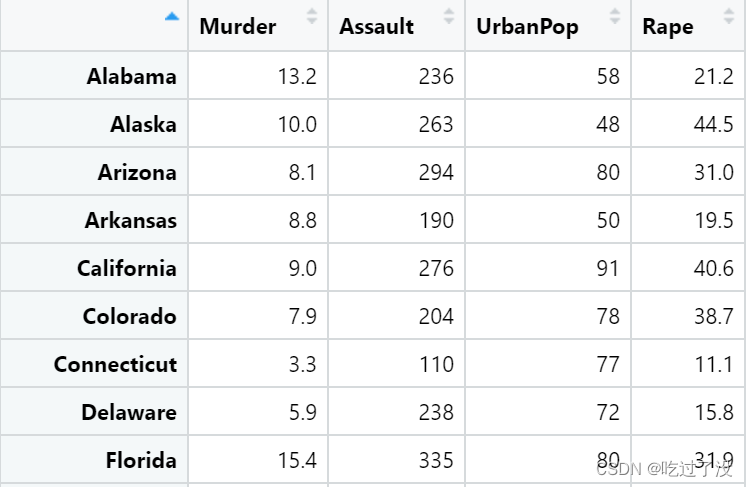
我们可以看到Connecticut那一行还是有小于5的值,这就是因为any_vars使用“或”连接,所以只要那一行有一个值大于5就会被保留下来。所以我们需要试一下all_vars。
data_2=filter_all(USArrests,all_vars(.>5))数据集长这样
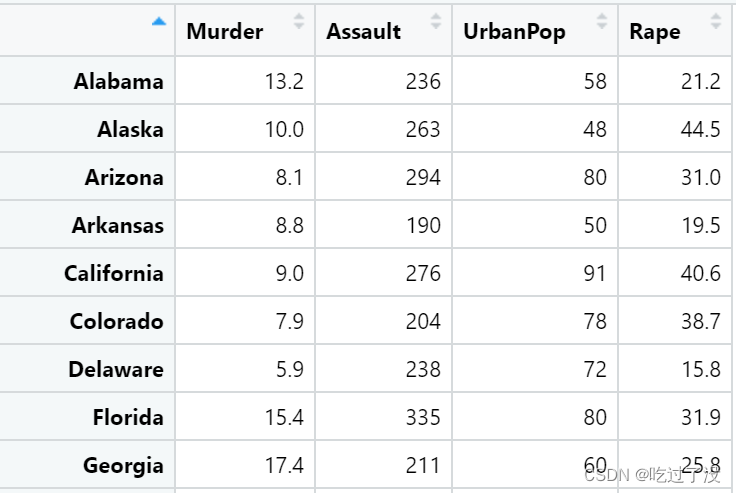
我们可以看到Connecticut这一行就被筛出去了,这就是因为all_vars使用“且”连接,需要所有列都大于5才会被保留下来。
接下来我们使用filter_at()做筛选,同样也要注意any_vars和all_vars的区分,这里我们用all_vars来筛选,选择UrbanPop和Rape都大于40的行
data_3=filter_at(USArrests,vars(UrbanPop,Rape),all_vars(. >=40))得到如下数据集
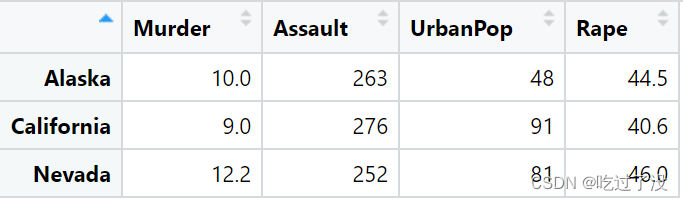
这里就选出了UrbanPop和Rape都大于40的行。
接下来再用filter_if(),同样注意any_vars和all_vars的区分。
data_4=filter_if(USArrests,is.numeric,any_vars(is.numeric(.)))数据集长这样
这里因为所有的数据都是numeric,所以is.numeric的结果都是TRUE,所以data_4的结果和原数据集是一样的。
到这里,我们就知道了filter_all(),filter_at(),filter_if()的使用方法,在实际使用时要注意any_vars() 和 all_vars()的区别。

















 2154
2154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









