









Reinforcement Learning-based Hierarchical Seed Scheduling for Greybox Fuzzing
| 论文题目 | Reinforcement Learning-based Hierarchical Seed Scheduling for Greybox Fuzzing |
|---|---|
| 工具名称 | AFL-HIER AFL++-HIER |
| 论文来源 | NDSS 2021 |
| 一作 | Jianhan Wang (University of California, Riverside) |
| 文章链接 | https://www.ndss-symposium.org/ndss-paper/reinforcement-learning-based-hierarchical-seed-scheduling-for-greybox-fuzzing/ |
整体内容
灰盒模糊测试(Grey-box Fuzzing) 的流程可以描述为:模糊测试通过变异和交叉拼接生成新的测试用例,然后根据能体现适应度的机制去从新生成的输入中选出适应度高的放到种子池里,用于之后的变异。不同于自然的进化过程,种子池里的种子只有一部分会被选中去进行变异等操作生成新的测试用例。
AFL使用edge coverage来衡量种子的适应度,也就是种子是否覆盖新的branch,以覆盖更多的branch。适应度函数一个重要的性能就是保存中间节点的能力(its ability to preserve intermediate waypoint)。这里我理解的是:去探索未覆盖的路径的时候,要把已经覆盖的关键路径保留。论文中举的例子:假设有一个校验是 a = 0 x d e a d b e e f a = 0xdeadbeef a=0xdeadbeef,如果只考虑edge覆盖率,那么要想变异出这个a,概率是 2 3 2 2^32 232。但是,如果保留重要的waypoints,把32位拆成4个8位的数字,从 0 x e f , 0 x b e e f , 0 x a d b e e f , 0 x d e a d b e e f 0xef,0xbeef,0xadbeef,0xdeadbeef 0xef,0xbeef,0xadbeef,0xdeadbeef去变异,变异出正确的数值的可能性会更大。
“Be sensitive and collaborative: Analyzing impact of coverage metrics in greybox
fuzzing”这篇论文通过更加细粒度地衡量代码覆盖,来保留中间节点。这个方法能够保留更多有价值的种子,增加种子的数量,但是给fuzzing种子调度加大了负担。有些种子可能永远都不会被选中。因此,在这种情况下要提出更加合理的种子调度策略。
这篇论文中用一个分级调度策略(hierarchical scheduler)来解决种子爆炸问题。分为两个部分:
- 通过不同敏感度等级的代码覆盖指标把种子进行聚类。
- 通过UCB1算法设计种子选择策略。
把fuzzing视为多臂老虎机问题,然后平衡exploitation和exploration。observation是:当一个代码覆盖率衡量指标 c j c_j cj比 c i c_i ci更敏感,在使用 c j c_j cj来保存中间节点的同时,用 c i c_i ci把种子进行一个聚类,聚类到一个节点。节点用一个树形结构来组织,越接近叶子节点的种子,它的代码覆盖指标更加敏感。
种子调度会根据UCB1算法从根节点开始选,计算每个节点的分数。直到选中一个叶子节点,从这个节点中包含的众多种子中再选一个种子。每次fuzzing完,对树形结构中的值进行更新。
论文内容
- Waypoint的解释:一个测试用例如果触发了bug,我们把它视为一个链的末尾,而它对应的初始的种子视为起点。那么,初始种子经过变异生成的中间测试用例到最终生成能够触发bug的测试用例,这中间的所有的种子逐渐地降低bug的搜索空间,把这些种子叫做waypoint。
多级代码覆盖指标(用于种子聚类)
- 使用敏感度高的代码覆盖率指标能够提高fuzzing发现更多程序状态的能力。但是,种子的数量也因此增加了,fuzzing的种子调度的负荷也增加了。
- 种子之间的相似性和差异性影响着fuzzing的exploration和exploitation。
- 使用聚类的方法把相似的种子聚类。同一类的种子在代码覆盖粒度上是一样的。通过多级的代码覆盖指标把种子进行聚类。
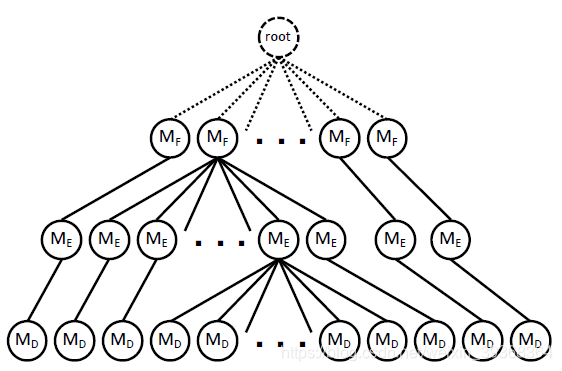
- 如上图所示,用多级的不同粒度的覆盖率指标把种子进行聚类。
- 当一个测试用例覆盖了新的函数、基本块或者边,它被保存下来作为一个种子。接下来进行聚类,从根节点开始,不同的敏感度的代码覆盖衡量指标判断子节点中是否覆盖和这个新的种子一样,如果一样就继续往下聚类。如果不一样就新建一个节点。
- 这里由三种衡量指标:函数、基本块和边。在树中深度约小的指标敏感度越低。
分层种子调度策略
- 挑选种子的过程就是从根节点开始搜索到一个叶子节点的过程。
- exploration vs Exploitation。一方面,新生成的还没怎么fuzzing过的种子可能带来新的代码覆盖率,另一方面带来新的代码覆盖率的被fuzzing过的种子被选中的几率更大。
- 这篇论文把种子调度视为一个多臂老虎机问题,用已有的MAB算法UCB1来平衡exploitation和exploration。从根节点开始,基于代码覆盖指标选择分数最高的种子,直到选中一个叶子节点。每轮fuzzing结束,沿着种子选择的路径上的所有节点都会加分数。
- 种子分数的计算,考虑三个方面
- 这个种子的稀有程度:
- 这个种子变异出新的有趣测试用例的难易程度
- 不确定性
一个特征 F ∈ τ l F \in \tau_l F∈τl 在level l l l的 h i t c o u n t hit count hitcount 表示覆盖那个特征的测试用例的数量。
P \mathcal P P 表示被测程序, I \mathcal I I是目前生成所有输入,则
n u m h i t s [ F ] = ∣ I ∈ I : F ∈ C l ( P , T ) ∣ num_hits[F] = |{I \in \mathcal I :F \in C_l(P,T)}| numhits[F]=∣I∈I:F∈Cl(P,T)∣
很多论文中都提到,越是稀有,越要提高选中的概率。因此,
r a r e n e s s [ F ] = 1 n e m _ h i t s [ F ] rareness[F] = \frac{1}{nem\_hits[F]} rareness[F]=nem_hits[F]1
假设,我们在第 t t t轮选中一个种子 s s s来进行fuzzing, I s , t \mathcal I_{s,t} Is,t是这一轮生成的所有测试用例,代码覆盖等级 C l , l ∈ 1 , . . . , n C_l,l \in {1,...,n} Cl,l∈1,...,n下, f c o v [ s , l , t ] = { F : F ∈ C ( P , I ) ∀ I s , t } fcov[s,l,t] = \{F:F \in C(P,I) \forall I_{s,t}\} fcov[s,l,t]={F:F∈C(P,I)∀Is,t}
接下来,如何计算一轮fuzzing之后seed的reward。如果只把新覆盖的features的数量作为reward,随着fuzzing的进行,覆盖新的特征的可能性逐渐降低,因此,种子的平均回报可能会迅速减少到零。当种子数量多且方差接近零时,UCB算法不能很好地对种子进行优先排序。因此,这个论文中在计算seedreward的时候,就按最稀有的那个特征的稀有值作为这个种子的reward。
说人话就是:比如这层是函数级别的代码覆盖指标,那就首先统计所有生成的种子覆盖的函数分别的覆盖次数,找出覆盖次数最少的次数,然后用1除以它就是$SeedReward(s,l,t) $。
S e e d R e w a r d ( s , l , t ) = m a x F ∈ f c o v [ s , l , t ] ( r a r e n e s s [ F ] ) SeedReward(s,l,t) = \underset{F\in fcov[s,l,t]}{max}(rareness[F]) SeedReward(s,l,t)=F∈fcov[s,l,t]max(rareness[F])
在反向传播的时候,不同层的节点的reward怎么算呢?每一层的节点d可以构成一个序列, < a 1 , . . . , a n , a n + 1 > <a^1,...,a^n,a^n+1> <a1,...,an,an+1>。在计算reward的时候,考虑到 a l a^l al会影响到之后的种子调度,并且它的feedback是由coverage level组成的,reward的计算方式如下:
R e w a r d ( a l , t ) = ∏ l ≤ k ≤ n S e e d R e w a r d ( s , k , t ) n − l + 1 Reward(a^l,t) = \sqrt[n-l+1]{\prod_{l \le k \le n}{SeedReward(s,k,t)}} Reward(al,t)=n−l+1l≤k≤n∏SeedReward(s,k,t)
reward是规定好从下到上分数怎么传递,接下来就是怎么从上到下怎么去选种子。论文基于UCB1计算fuzzing一个种子的performance期望:
F u z z P e r f ( a ) = Q ( a ) + U ( a ) FuzzPerf(a) = Q(a) + U(a) FuzzPerf(a)=Q(a)+U(a)
Q ( a ) Q(a) Q(a)是节点 a a a目前得到的reward平均值,$ U(a) $是上置信区间半径。
在计算Q的时候使用加权平均,也就是一个种子变异的次数越多,它的稀缺性越低。
Q ( a , t ) = R e w a r d ( a , t ) + w ⋅ Q ( a , t ′ ) ⋅ ∑ p = 0 N [ a , t ] − 1 w p 1 + w ⋅ ∑ p = 0 N [ a , t ] − 1 w p Q(a,t) = \frac{Reward(a,t)+w · Q(a,t') ·\displaystyle \sum ^{N[a,t]-1}_{p=0} w^p}{1+w·\displaystyle \sum ^{N[a,t]-1}_{p=0} w^p} Q(a,t)=1+w⋅p=0∑N[a,t]−1wpReward(a,t)+w⋅Q(a,t′)⋅p=0∑N[a,t]−1wp
N [ a , t ] N[a,t] N[a,t]表示t轮结束时这个种子被选中的次数,t’表示上一轮a被选中。w在后面实验部分有测试,取值为0.5。
U ( a ) U(a) U(a),一个节点中包含的种子数量越多,应该给更高的选中机会。
U ( a ) = C × Y [ a ] Y [ a ′ ] × l o g N [ a ′ ] N [ a ] U(a) = C \times \sqrt{\frac{Y[a]}{Y[a']}} \times \sqrt{\frac{logN[a']}{N[a]}} U(a)=C×Y[a′]Y[a]×N[a]logN[a′]
Y [ a ] Y[a] Y[a]就是节点中种子的数量。C是一个参数设置成1.4。(通常MCTS中都会把C设置成根号2,也就是1.4)
以上的公式只能够根据已有的数据来计算,对于没有被选中过的种子,它没有选中次数,也只有一个种子,我们就无法计算相应的值。因此对于这些种子,它也有覆盖的特征路径,根据它覆盖的特征,这么计算:
S e e d R a r e n e s s ( s , l ) = ∑ F ∈ C l ( p , s ) r a r e n e s s 2 [ F ] ∣ F : F ∈ C l ( p , s ) ∣ SeedRareness(s,l) = \sqrt{ \frac{\sum_{F\in C_l (p,s)} rareness^2[F]}{|{F:F \in C_l(p,s)}|} } SeedRareness(s,l)=∣F:F∈Cl(p,s)∣∑F∈Cl(p,s)rareness2[F]
这里用根号是为了让这个值更小,保留更多的差异性,那么节点的稀有性计算如下:
R a r e n e s s ( a l ) = S e e d R a r e n e s s ( s , l ) Rareness(a^l) = SeedRareness(s,l) Rareness(al)=SeedRareness(s,l)
也就是上一层的稀有性和它的子节点是一样的。每轮除了反向传播reward,也要反向传播稀有性。
结合上述所有公式,选中一个节点的分数计算方式如下:
S c o r e ( a ) = R a r e n e s s ( a ) × F u z z P e r f ( a ) Score(a) = Rareness(a) \times FuzzPerf(a) Score(a)=Rareness(a)×FuzzPerf(a)
实验
分别基于AFL和AFL++实现了两个原型:AFL-HEIR和AFL++-HEIR。
- 数据集:在180个CGC程序上,每个跑2小时,重复10次,初始测试用例设为“123\n456\n789\n”。 Google Fuzzbench。
- baseline:对于AFL-HEIR,选择AFL,AFLFast, AFL-Flat(使用AFLFast的能量调度然后配置了不同的代码覆盖衡量指标edge和distance)。所有都泡在qemu模式下。对于AFL++-HEIR选择AFL++和AFL++-FLAT。
- 衡量指标:
CGC: CGC中crash的程序的平均以及最低和最高数量、首先发现crash的时间。代码覆盖率:统计AFL-HEIR比其它跑的好的程序的数量。别的程序2小时达到的代码覆盖率AFL-HEIR的用时。AFL-HEIR用多长时间超过其它的fuzzer.
Fuzzbench:比较了AFL++-HEIR和AFL++和AFL++-FLAT。6个小时代码覆盖率平均值。unique edge数量。
这里对实验结果进行了讨论:
与CGC基准测试的结果相比,我们发现在大多数FuzzBench基准测试中,我们的性能并没有明显优于afl++。我们怀疑原因是我们在评估中使用的基于ucb1的调度程序和超参数更倾向于开发而不是探索。因此,当被测试的程序相对较小时(例如,CGC基准测试),我们的调度器可以发现更多的错误,而不会牺牲太多的整体覆盖。但是在FuzzBench程序中,打破一些独特的边缘(表II)可能会因为不探索其他更容易覆盖的边缘而被掩盖。
吞吐量: CGC上计算工具在种子调度上花费的时间。
分析多级种子调度策略的有效性:拿AFL-HEIR和AFL比较,AFL-Flat和AFLfast比较。统计每个fuzzer生成的种子数量,以及AFL++-HEIR在不同level的节点数量。
分析公式中参数的影响。
对其它覆盖率指标的支持性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









