







目录
前言
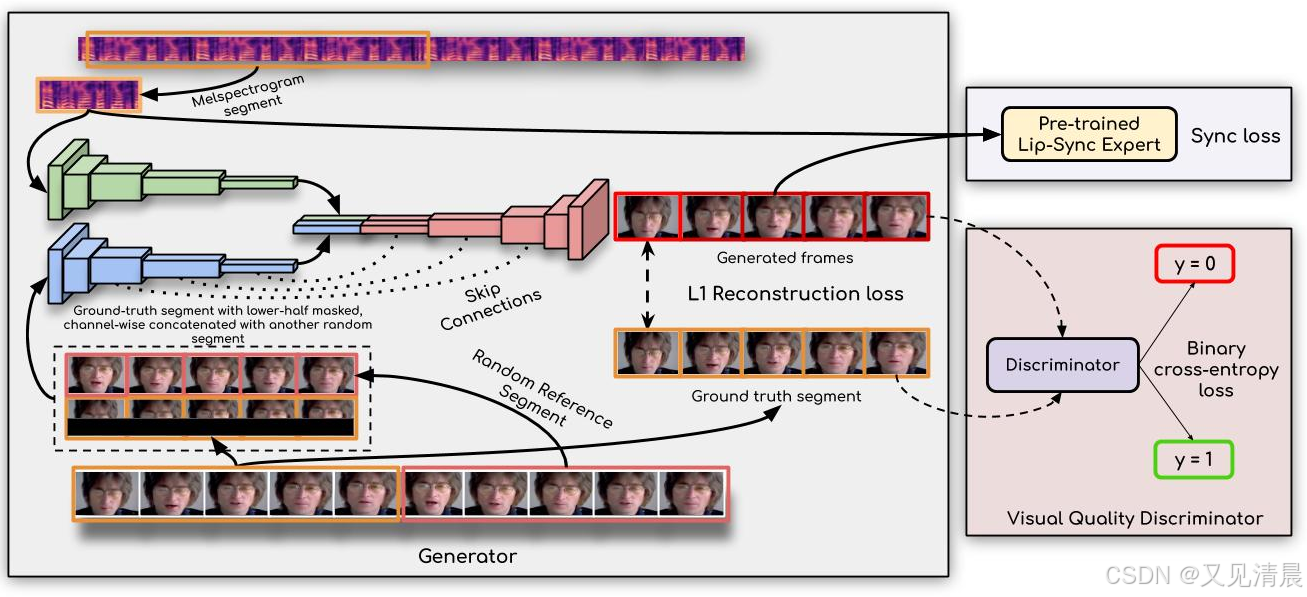
在这项工作中,我们研究的问题是嘴唇同步一个说话的人脸视频的任意身份,以匹配目标语音片段。目前的作品擅长在静态图像或训练阶段看到的特定人的视频上产生准确的嘴唇运动。然而,它们无法准确地变形动态、无约束的说话人脸视频中任意身份的嘴唇运动,导致视频的重要部分与新音频不同步。我们找出了与此相关的主要原因,并通过向强大的假唱鉴别器学习来解决这些问题。接下来,我们提出了新的、严格的评估基准和度量,以准确地测量无约束视频中的嘴唇同步。在我们具有挑战性的基准上进行的大量量化评估表明,由我们的Wav2Lip模型生成的视频的唇形同步准确性几乎与真实的同步视频一样好。
源代码下载
受外网限制,部分依赖库无法远程git,导致程序报错,我把整个项目代码以及关联模型全部拷贝到了百度网盘里,此版本为2023年3月14日发布,363.8M大小,请先下载:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









