







1.原理
1.1 简述
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它用词向量的方式表征词的语义信息。
结构一般是简单三层网络,一个输入层、一个隐含层、一个输出层。
1.2 CBOW 连续词袋模型 continuous bag of words
用上下文预测当前词
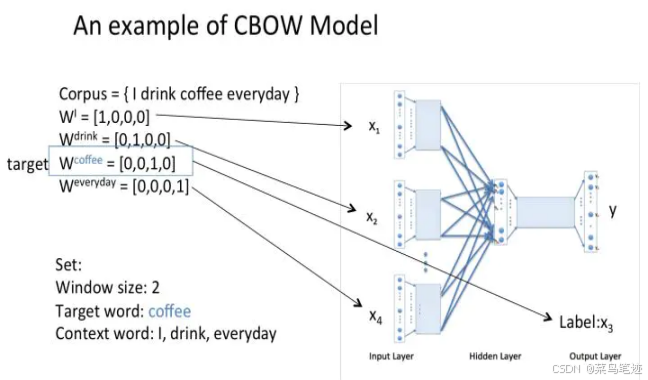
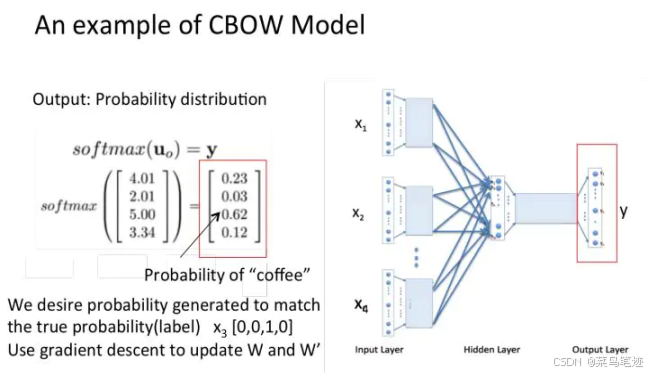
1.2.1 一个上下文
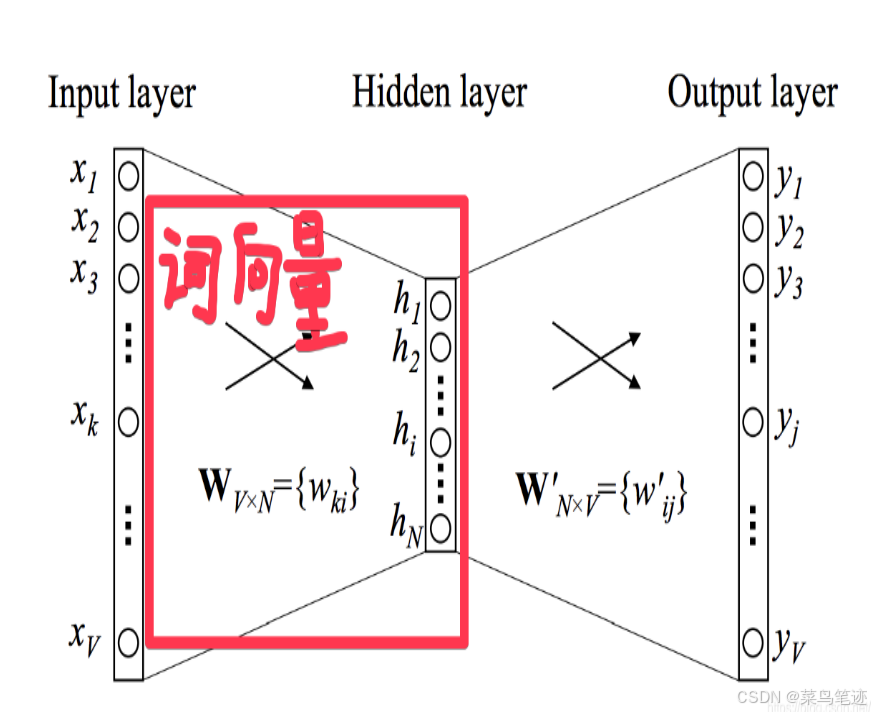
1.2.2.多个上下文
当多个上下文词的情况的时候,只需要将多个上下文词的向量求和或者平均作为输入就行
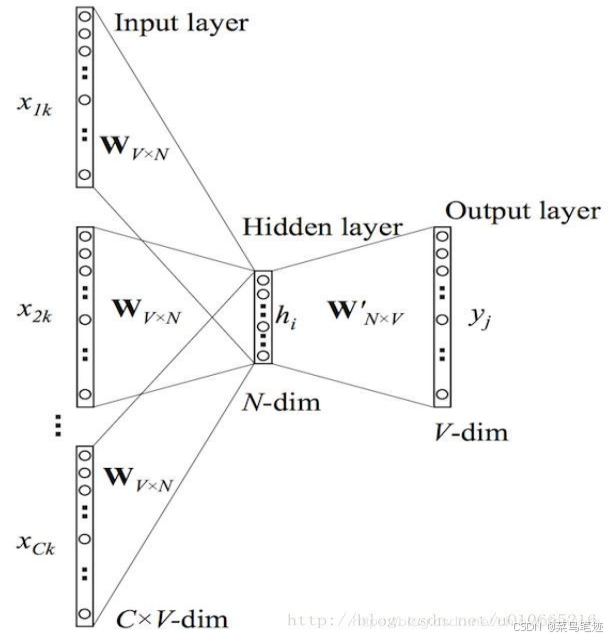
1.3 skip-gram 跳字模型
用当前词预测上下文

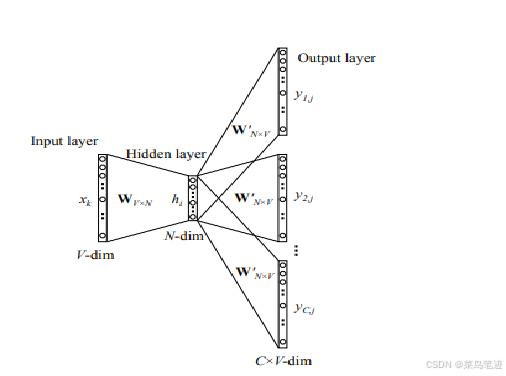
1.4 word2vec的优化方法
(1) 输入-隐层权重矩阵和隐层-输出层的权重矩阵 权重参数太多,计算量太大。 优化方法
将常见的单词组合(word pairs)或者词组作为单个“words”来处理,减少训练样本(反而增加了权重参数)
对高频次单词进行抽样来减少训练样本的个数,如(fox,the),(dog,the)…
(2)softmax计算量大的优化方法
hierarchical softmax (层次softmax) 计算复杂度由kN --> kln(N)
negative sampling:对负样本进行采样,这样训练一个样本只会更新一小部分的模型权重,从而降低计算负担
1.4.1.层次化softmax
和之前的神经网络语言模型相比,霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量(即隐含层词向量),而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"
DNN模型最大的问题在于从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。计算量很大,可以通过层次化softmax 降低计算量。出现概率越高的符号使用较短的编码(层次越浅),出现概率低的符号则使用较长的编码(层次越深)
采用层次化Softmax的word2vec 的网络结构为:输入层 --> 隐藏层 --> 层次化softmax
假设我们的词典有word [the, of ,respond, active, plutonium, ascetic, arbitrarily, chupacabra] 共8个单词。接下对hierarchical softmax训练做一个讲解,主要步骤如下:
- 预处理:构建haffman树
根据语料中的每个word的词频构建赫夫曼tree,词频越高,则离树根越近,路径越短。如下图所示,词典V 中的每个word都在叶子节点上,每个word需要计算两个信息:路径(经过的每个中间节点)以及赫夫曼编码,例如:“respond”的路径经过的节点是(6,4,3),编码label是(1,0,0)
构建完赫夫曼tree后,每个叶子节点都有唯一的路径和编码,hierarchical softmax与softmax不同的是,在hierarchical softmax中,不对V中的word词进行向量学习,而是对中间节点进行向量学习,而每个叶子上的节点可以通过路径中经过的中间节点去表示。
-
模型的输入
输入部分,在cbow或者skip-gram模型,要么是上下文word对应的id词向量平均,要么是中心词对应的id向量,作为hidden层的输出向量 -
样本label
不同softmax的是,每个词word对应的是一个V大小的one-hot label,hierarchical softmax中每个叶子节点word,对应的label是赫夫曼编码,一般长度不超过 l o g 2 V ,,在训练的时候,每个叶子节点的label统一编码到一个固定的长度,不足的可以进行pad。
1.4.2 负采样 negative sampling
词典的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量
Negative Sampling是对于给定的词,并生成其负采样词集合的一种策略,已知有一个词,这个词可以看做一个正例,而它的上下文词集可以看做是负例,但是负例的样本太多,而在语料库中,各个词出现的频率是不一样的,所以在采样时可以要求高频词选中的概率较大,低频词选中的概率较小,这样就转化为一个带权采样问题,大幅度提高了模型的性能
当我们用训练样本 ( input word: “fox”,output word: “quick”) 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的词典大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
如果使用了负采样的方法我们仅仅去更新我们的positive word-“quick”的和我们选择的其他5个negative words的结点对应的权重,共计6个输出神经元,相当于每次只更新 300 x 6 = 1800 个权重。对于3百万的权重来说,相当于只计算了0.06%的权重,这样计算效率就大幅度提高
如何选择negative words
我们使用“一元模型分布(unigram distribution)”来选择“negative words”。个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。
每个单词被选为“negative words”的概率计算公式:

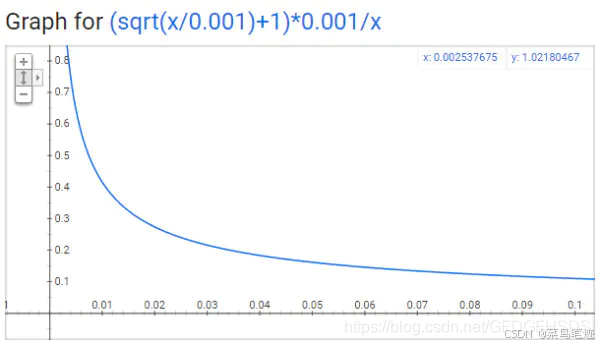
有一个参数叫“sample”,这个参数代表一个阈值,默认值为0.001(在gensim包中的Word2Vec类说明中,这个参数默认为0.001,文档中对这个参数的解释为“ threshold for configuring which higher-frequency words are randomly downsampled”)。这个值越小意味着这个单词被保留下来的概率越小(即有越大的概率被我们删除)
1.4.3.Word pairs and “phases”
一些单词组合(或者词组)的含义和拆开以后具有完全不同的意义。比如“Boston Globe”是一种报刊的名字,而单独的“Boston”和“Globe”这样单个的单词却表达不出这样的含义。因此,在文章中只要出现“Boston Globe”,我们就应该把它作为一个单独的词来生成其词向量,而不是将其拆开。同样的例子还有“New York”,“United Stated”等
1.4.4 对高频词进行下采样
对于“the”这种常用高频单词,这样的处理方式会存在下面两个问题:
当我们得到成对的单词训练样本时,(“fox”, “the”) 这样的训练样本并不会给我们提供关于“fox”更多的语义信息,因为“the”在每个单词的上下文中几乎都会出现
由于在文本中“the”这样的常用词出现概率很大,因此我们将会有大量的(”the“,…)这样的训练样本,而这些样本数量远远超过了我们学习“the”这个词向量所需的训练样本数
Word2Vec通过“抽样”模式来解决这种高频词问题。它的基本思想如下:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
ωi 是一个单词,Z(ωi) 是 ωi 这个单词在所有语料中出现的频次,例如:如果单词“peanut”在10亿规模大小的语料中出现了1000次,那么 Z(peanut) = 1000/1000000000 = 1e - 6。
P(ωi) 代表着保留某个单词的概率:
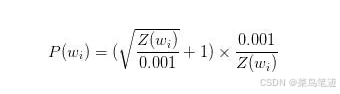
2.调参


3. 面试常见问题
介绍一下 word2vec:
Word2Vec 是以无监督的方式学习大量文本语料然后用词向量的方式表征词的语义信息,然后使得语义相似的单词在嵌入式多维空间中的距离相近。
word2vec 的两个模型分别是 CBOW 和 Skip-gram,假设一个训练样本是核心词 w和其上下文 context(w) 组成,那么 CBOW 就是用 context(w)上下文去预测 w当前单词;而 Skip-gram 则反过来,是用 w当前单词去预测上下文context(w)里的所有词。
两个加快训练的方法是层次化Softmax和负采样。(1) 层次化Softmax利用词频建立一棵哈夫曼树,将原来的softmax多分类,转化成预测从根节点到该词所在叶子节点的路径,也就是多个二分类问题;树的叶子节点表示词,高频词靠近根节点、低频词远离根节点,可以用更少的计算来处理高频词提高计算效率。(2) 负采样:在负采样中目标词汇是一个正例,而它的上下文词集可以看做是负例,但是负例的样本太多,而在语料库中,各个词出现的频率是不一样的,所以在采样时可以要求高频词选中的概率较大,低频词选中的概率较小(可以让频率高的词先学习,然后带动其他词的学习),这样就转化为一个带权采样问题,大幅度提高了模型的性能。
Word2vec的优缺点
word2vec是静态表示的一个里程碑。但是静态表示有个根本上的缺陷就是无法表示一词多义。因为每个词对应的向量只有一个,训练完成就固定不变了,是静态变量。这引发了后面词动态表示的研究。ELMo,GPT以及BERT及其衍生的模型都可以认为是动态表示。
对比 CBOW(更效率)和Skip-gram(更准确)
①训练速度上 CBOW 会更快一点,因为每次会更新若干个上下文单词的词向量,而 Skip-gram 只更新一个目标词汇的词向量。cbow是基于周围词来预测这个单词本身 。而skip-gram是基于本身词去预测周围词。 那么,cbow只要 把窗口内的其他词相加一次作为输入来预测 一个单词。不管窗口多大,只需要一次运算。而skip-gram直接受窗口影响,窗口越大,需要预测的周围词越多。在训练中,通过调整窗口大小明显感觉到训练速度受到很大影响。
②低频词:Skip-gram 对低频词效果比 CBOW好,因为是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 在根据上下文单词预测当前词汇时更倾向于用高频词。所以Skip-gram 在大一点的数据集可以提取更多的信息,比 CBOW 要好一些。
对比 HS 和 负采样的区别:
负采样更快一些,特别是词表很大的时候。
训练完有两套词向量,为什么只用前一套?
① 对于层次化Softmax来说,哈夫曼树中的参数是不能拿来做词向量的,因为没办法和词典里的词对应。
② 负采样中的参数其实可以考虑做词向量,因为中间是和前一套词向量做内积,应该也是有意义的。但是考虑负样本采样是根据词频来的,可能有些词会采不到,也就学的不好。
Glove是基于全局统计信息构建共现关系矩阵,然后利用矩阵分解去拟合共现关系矩阵,不断优化损失函数,得到每个词的词向量。
fastText文本分类和word2vec的区别
相似处:
图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
不同处:
模型的输出层:
word2vec的输出层,对应的是每一个term,找出概率最大的单词;
而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
模型的输入层:word2vec的输入层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
两者本质的不同,体现在 h-softmax的使用:
Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax,也会生成一系列的向量,但最终都被抛弃,不会使用。
fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
Embedding的size 怎么确定?

Word2Vec作为一个简单易用的算法,其也包含了很多局限性:
Word2Vec只考虑到上下文信息,而忽略的全局信息;
Word2Vec只考虑了上下文的共现性,而忽略的了彼此之间的顺序性;
4. 模型评估方式
怎样评估word2vec训练的好坏?
4.1 词聚类
可以采用 kmeans 聚类,看聚类簇的分布
4.2 词cos 相关性
查找cos相近的词
4.3 Analogy对比
a:b 与 c:d的cos距离 (man-king woman-queen )
4.4 使用tnse,pca等降维可视化展示
5. 实战–app序列分析

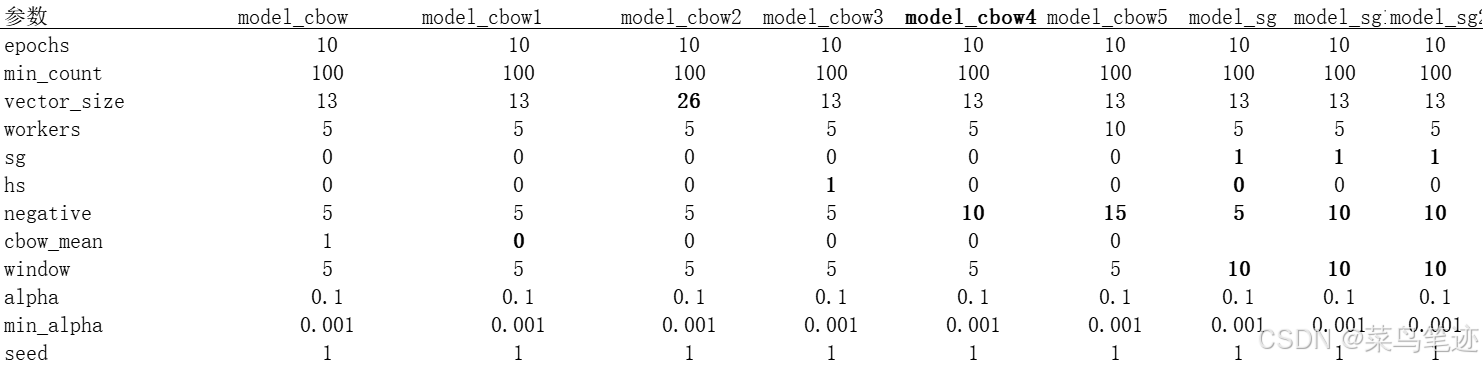
6. 实战–调参


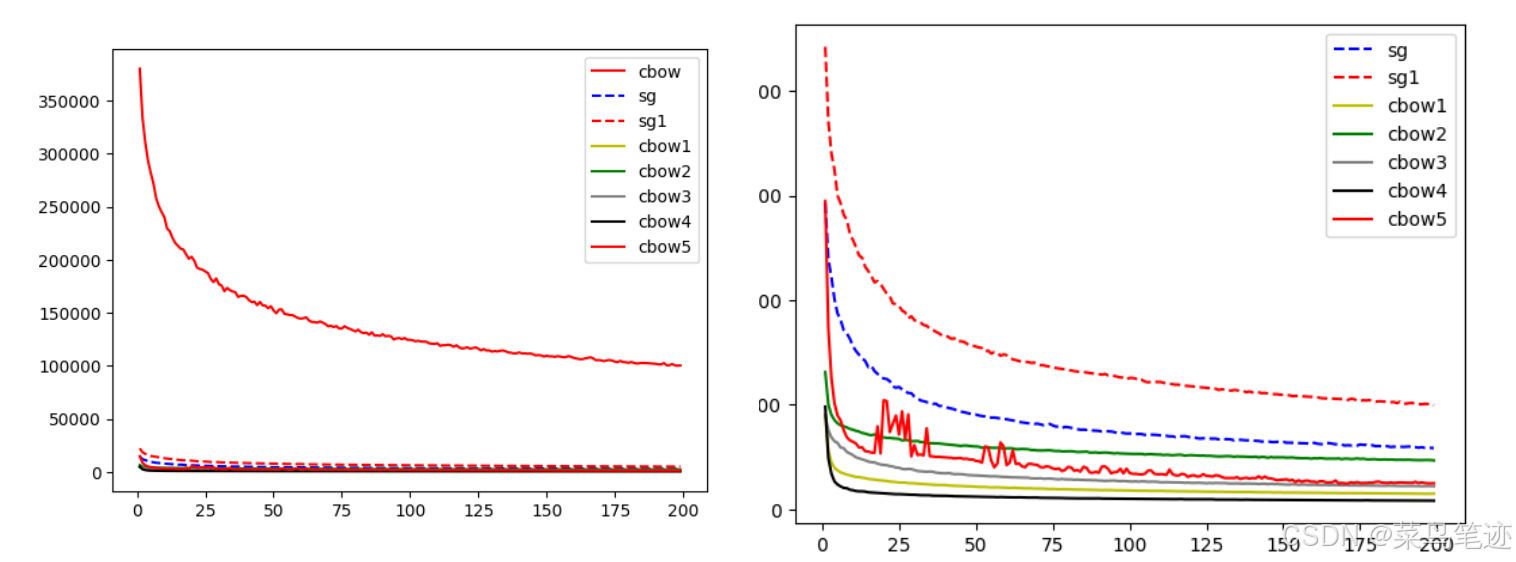
7. 实战–代码
# data deal drop user-- app num>180 or app num<3
df_stats = data['user_id'].value_counts().reset_index()
df_stats.columns = ['user_id', 'list_cnt']
print(data['user_id'].nunique())
remaining_users = df_stats[(df_stats['list_cnt']<=180)&(df_stats['list_cnt']>=4)]['user_id'].values
len(remaining_users)
# app embedding
df_app_cnt = data['app_company'].value_counts().reset_index().rename(columns={'index': 'app_name', 'app_company': 'app_cnt'})
df_app_cnt['app_ratio'] = df_app_cnt['app_cnt'] / data['user_id'].nunique()
# app name--ID mapping
app_mapping = {app:str(idx+1) for idx, app in enumerate(df_app_cnt[df_app_cnt['app_cnt']>=100]['app_name'].values.tolist())}
app_mapping['unknow'] = '0'
app_mapping_reverse = {v: k for k, v in app_mapping.items()}
len(df_app_cnt)
len(app_mapping)
df_app_cnt.loc[df_app_cnt['app_ratio']>=0.00007][['app_name','app_ratio']].to_csv('app_cover_rate.csv', index=None)
# save app mapping
with open('app_mapping_0902.pickle', 'wb') as handle:
pickle.dump(app_mapping, handle)
data['app_idx'] = data['app_company'].map(app_mapping)
data['app_idx'].fillna('0', inplace=True)
# build train data
# train data sort_values by install_payment_gap
df_grouped = data.groupby('user_id')
training_list = []
for cur_uid in tqdm(remaining_users):
df_train_sel = df_grouped.get_group(cur_uid)
app_to_train = df_train_sel[df_train_sel['install_payment_gap']<730].sort_values(by='install_payment_gap', ascending=False)['app_idx'].values.tolist()
training_list.append(app_to_train)
# save train data
with open(path+'/data/applist.pickle', 'wb') as handle:
pickle.dump(training_list, handle)
# word2vec
# CBOW
model_cbow = Word2Vec(sentences = training_list, # We will supply the pre-processed list of moive lists to this parameter
epochs = 10, # epoch
min_count = 100, # an item has to appear more than x times to be keeped
vector_size = 13, # size of the hidden layer
workers = 5, # specify the number of threads to be used for training
sg = 0, # Defines the training algorithm. We will use skip-gram so 1 is chosen.
hs = 0, # Set to 0, as we are applying negative sampling.
negative = 5, # If > 0, negative sampling will be used. We will use a value of 5.
cbow_mean=1,
window = 5,
alpha=0.1,
min_alpha=0.001,
seed=1)
# app embedding
app_list_tot = []
app_vector_tot = []
for app_name, app_idx in app_mapping.items():
try:
app_vector_tot.append(model_cbow.wv.get_vector(app_idx))
app_list_tot.append(app_name)
except:
pass
inertia_list = []
for i in tqdm(range(1,200)):
cur_km = MiniBatchKMeans(n_clusters=i, max_iter=100, batch_size=1000,random_state=1)
cur_km.fit(app_vector_tot)
inertia_list.append(cur_km.inertia_)
# gensim,
model_sg = Word2Vec(sentences = training_list, # We will supply the pre-processed list of moive lists to this parameter
epochs = 10, # epoch
min_count = 100, # an item has to appear more than x times to be keeped
vector_size = 13, # size of the hidden layer
workers = 5, # specify the number of threads to be used for training
sg = 1, # Defines the training algorithm. We will use skip-gram so 1 is chosen.
hs = 1, # Set to 0, as we are applying negative sampling.
# negative = 5, # If > 0, negative sampling will be used. We will use a value of 5.
window = 10,
alpha=0.1,
min_alpha=0.001,
seed=1)
model_sg.save('item2vec')
## final word2vec
# gensim,
# CBOW
model_cbow4 = Word2Vec(sentences = training_list, # We will supply the pre-processed list of moive lists to this parameter
epochs = 10, # epoch
min_count = 100, # an item has to appear more than x times to be keeped
vector_size = 13, # size of the hidden layer ##
workers = 10, # specify the number of threads to be used for training
sg = 0, # Defines the training algorithm. We will use skip-gram so 1 is chosen.
hs = 0, # Set to 0, as we are applying negative sampling.
negative = 10, # If > 0, negative sampling will be used. We will use a value of 5.
cbow_mean=0, ##
window = 5,
alpha=0.1,
min_alpha=0.001,
seed=1)
model_cbow4.save('item2vec')
# appembedding
app_list_tot = []
app_vector_tot_cbow4 = []
for app_name, app_idx in app_mapping.items():
try:
app_vector_tot_cbow4.append(model_cbow4.wv.get_vector(app_idx))
app_list_tot.append(app_name)
except:
pass
# ,cluster1100,
inertia_list_cbow4 = []
for i in tqdm(range(1,200)):
cur_km_cbow4 = MiniBatchKMeans(n_clusters=i, max_iter=100, batch_size=1000,random_state=1)
cur_km_cbow4.fit(app_vector_tot_cbow4)
inertia_list_cbow4.append(cur_km_cbow4.inertia_)
plt.plot(list(range(1,200)), inertia_list_cbow4,color='y' ,label="cbow1")
## final kmeans
#
clustering = KMeans(n_clusters=15, max_iter=200,random_state=1)
cluster_res = clustering.fit_predict(app_vector_tot_cbow4)
df_cluster = pd.DataFrame({'packageName': app_list_tot, 'cluster': cluster_res})
df_cluster.to_csv(path+'/data/df_cluster.csv',index=False)
# get feature name
cate_list=list(range(0,15))
cate_list
var_list=['fird','samirfst','samirlst','samirbtw']
timeflag=['fird','samirfst','samirlst','samirbtw']
timedays=[1,3,5,7,30,60,90,120,180,360]
timeslice_list=[]
for i in timeflag:
for j in timedays:
timeslice=i+str(j)
timeslice_list.append(timeslice)
groupfunction_list=['min','max','avg']
#
feature_list_num=[]
for cate in cate_list:
for groupfunction in ['_num_']:
for timeslice in timeslice_list:
feature_list_num.append('app_cluster'+str(cate)+groupfunction+timeslice)
feature_list_num.append('app_cluster'+str(cate)+groupfunction+'all')
feature_list_num.append('app_cluster'+str(cate)+groupfunction+'samirfstal')
feature_list_num.append('app_cluster'+str(cate)+groupfunction+'samirlstal')
feature_list_num.append('app_cluster'+str(cate)+groupfunction+'samirbtwal')
len(feature_list_num+feature_list_rate)
# feature_list_num
feature_list_rate=[var.replace('_num_','_num_rate_') for var in feature_list_num]
feature_list_num+feature_list_rate
#
feature_list_days=[]
for cate in cate_list:
for var in var_list:
for groupfunction in groupfunction_list:
for timeslice in timeslice_list:
feature_list_days.append('app_cluster'+str(cate)+'_'+ var+'_' +groupfunction+'_'+timeslice)
len(feature_list_days)
feature_list_days
参考文章
https://blog.csdn.net/qfikh/article/details/103665681
https://blog.csdn.net/weixin_44852067/article/details/130221655
https://baijiahao.baidu.com/s?id=1765289350112066790&wfr=spider&for=pc
https://blog.csdn.net/BGoodHabit/article/details/106163130
https://blog.csdn.net/GFDGFHSDS/article/details/105346055
https://arxiv.org/pdf/1411.2738

















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









