









大数据就是存储、计算、应用大数据的技术,如果没有数据,所谓大数据就是无源之水、无本之木,所有技术和应用也都无从谈起。可以说,数据在大数据的整个生态体系里面拥有核心的、最无可代替的地位。
技术是通用的,算法是公开的,只有数据需要自己去采集。因此数据采集是大数据平台的核心功能之一,也是大数据的来源。数据可能来自企业内部,也可能是来自企业外部,大数据平台的数据来源主要有数据库、日志、前端程序埋点、爬虫系统。
从数据库导入
虽然 Hive 这样的大数据产品可以提供和关系数据库一样的 SQL 操作,但是互联网应用产生的数据却还是只能记录在类似 MySQL 这样的关系数据库上。这是因为互联网应用需要实时响应用户操作,基本上都是在毫秒级完成用户的数据读写操作,通过前面的学习我们知道,大数据不是为这种毫秒级的访问设计的。
所以要用大数据对关系数据库上的数据进行分析处理,必须要将数据从关系数据库导入到大数据平台上。上一期我提到了,目前比较常用的数据库导入工具有 Sqoop 和 Canal。
Sqoop
Sqoop 是一个数据库批量导入导出工具,可以将关系数据库的数据批量导入到 Hadoop,也可以将 Hadoop 的数据导出到关系数据库。
Sqoop 数据导入命令示例如下。
$ sqoop import --connect jdbc:mysql://localhost/db --username foo --password --table TEST
你需要指定数据库 URL、用户名、密码、表名,就可以将数据表的数据导入到 Hadoop。
Sqoop 适合关系数据库数据的批量导入,如果想实时导入关系数据库的数据,可以选择 Canal。
Canal
Canal 是阿里巴巴开源的一个 MySQL binlog 获取工具,binlog 是 MySQL 的事务日志,可用于 MySQL 数据库主从复制,Canal 将自己伪装成 MySQL 从库,从 MySQL 获取 binlog。
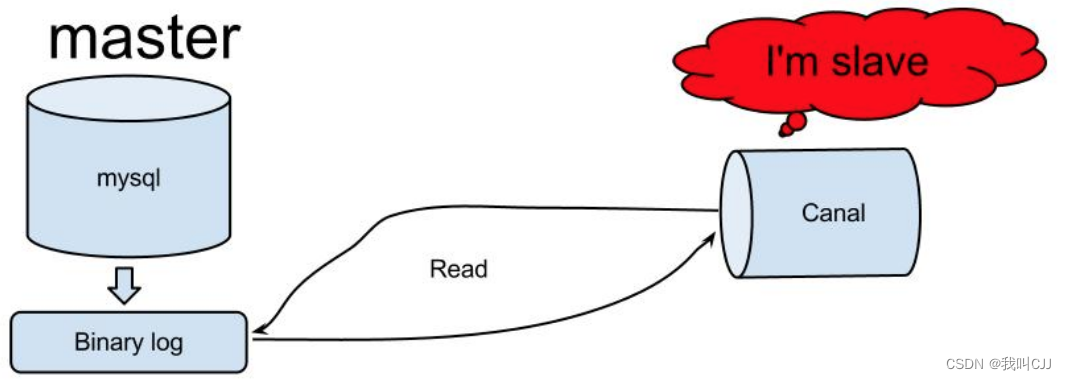
而我们只要开发一个 Canal 客户端程序就可以解析出来 MySQL 的写操作数据,将这些数据交给大数据流计算处理引擎,就可以实现对 MySQL 数据的实时处理了。
从日志文件导入
日志也是大数据处理与分析的重要数据来源之一,应用程序日志一方面记录了系统运行期的各种程序执行状况,一方面也记录了用户的业务处理轨迹。依据这些日志数据,可以分析程序执行状况,比如应用程序抛出的异常;也可以统计关键业务指标,比如每天的 PV、UV、浏览数 Top N 的商品等。
Flume
Flume 是大数据日志收集常用的工具。Flume 最早由 Cloudera 开发,后来捐赠给 Apache 基金会作为开源项目运营。Flume 架构如下。
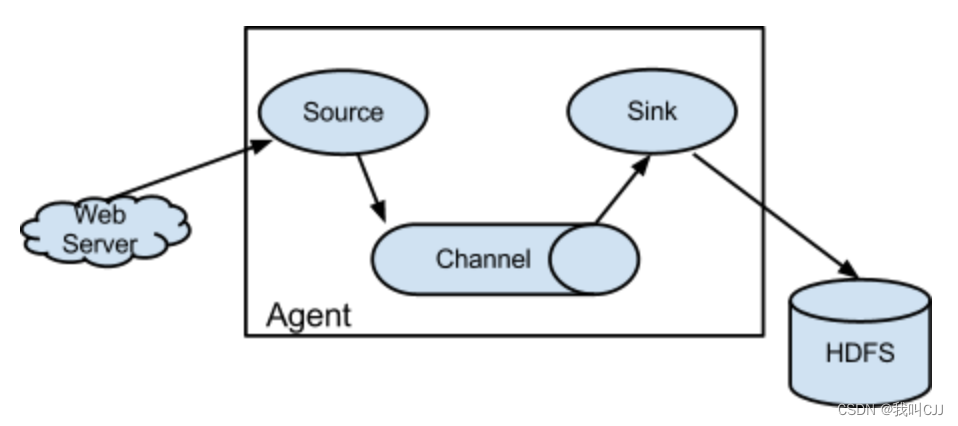
从图上看,Flume 收集日志的核心组件是 Flume Agent,负责将日志从数据源收集起来并保存到大数据存储设备。
Agent Source 负责收集日志数据,支持从 Kafka、本地日志文件、Socket 通信端口、Unix 标准输出、Thrift 等各种数据源获取日志数据。
Source 收集到数据后,将数据封装成 event 事件,发送给 Channel。
Channel 是一个队列,有内存、磁盘、数据库等几种实现方式,主要用来对 event 事件消息排队,然后发送给 Sink。
Sink 收到数据后,将数据输出保存到大数据存储设备,比如 HDFS、HBase 等。Sink 的输出可以作为 Source 的输入,这样 Agent 就可以级联起来,依据具体需求,组成各种处理结构,比如下图的结构。
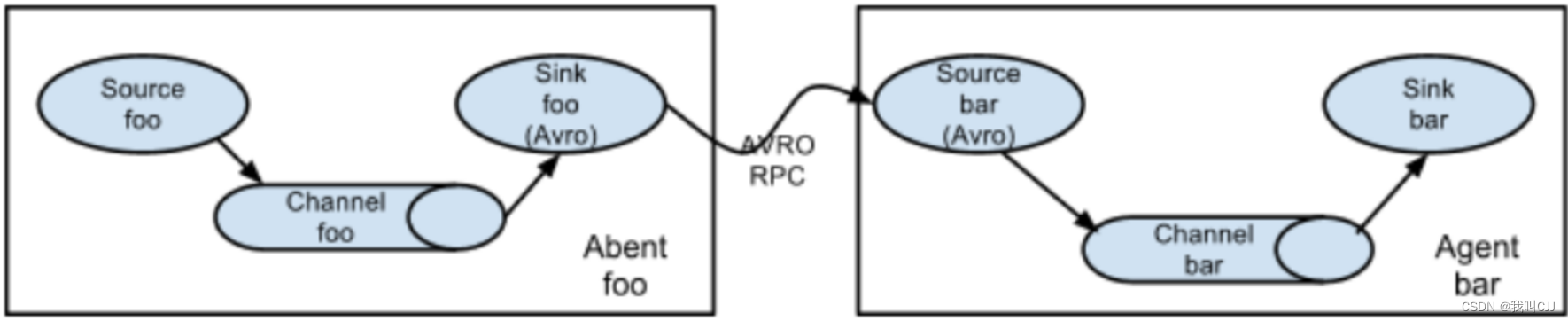
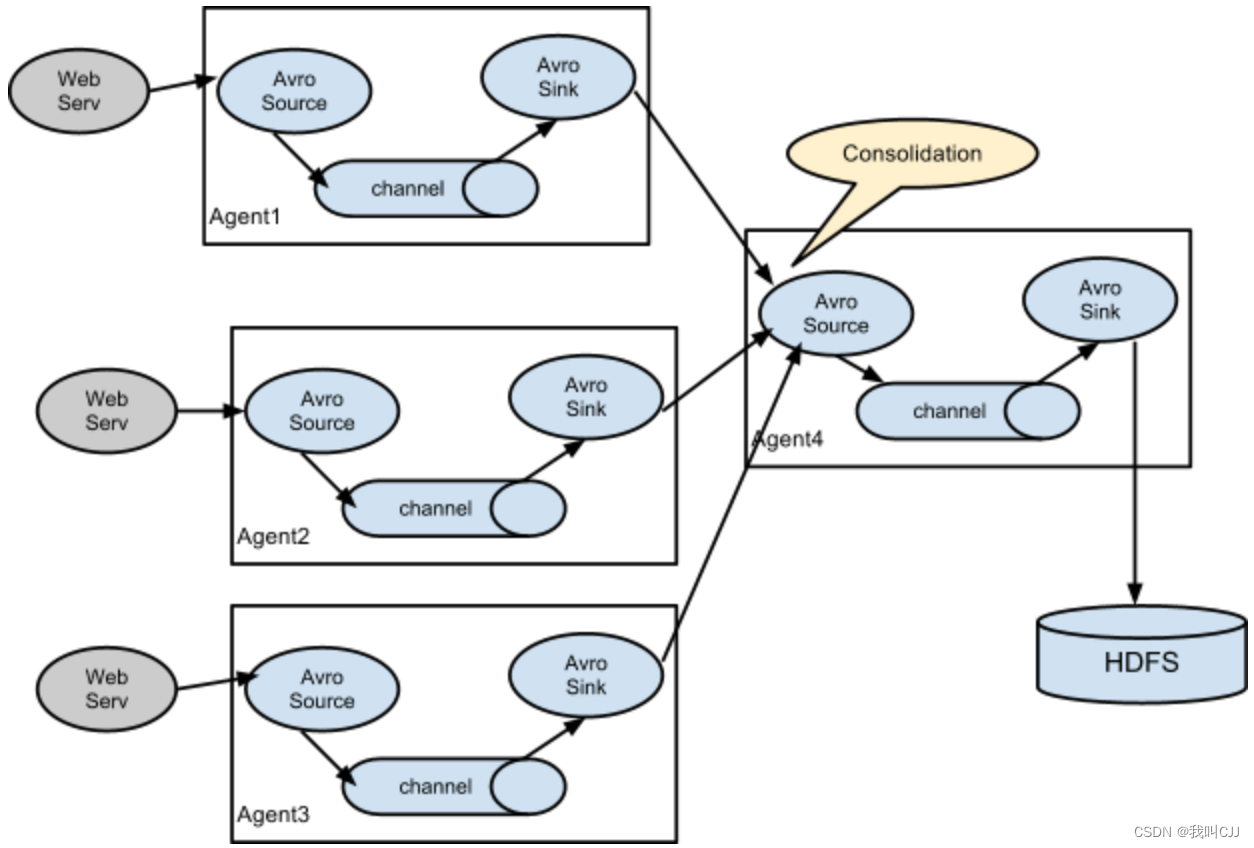
这是一个日志顺序处理的多级 Agent 结构,也可以将多个 Agent 输出汇聚到一个 Agent,还可以将一个 Agent 输出路由分发到多个 Agent,根据实际需求灵活组合。
前端埋点采集
前端埋点数据采集也是互联网应用大数据的重要来源之一,用户的某些前端行为并不会产生后端请求,比如用户在一个页面的停留时间、用户拖动页面的速度、用户选中一个复选框然后又取消了。这些信息对于大数据处理,对于分析用户行为,进行智能推荐都很有价值。但是这些数据必须通过前端埋点获得,所谓前端埋点,就是应用前端为了进行数据统计和分析而采集数据。
手工埋点
手工埋点就是前端开发者手动编程将需要采集的前端数据发送到后端的数据采集系统。通常公司会开发一些前端数据上报的 SDK,前端工程师在需要埋点的地方,调用 SDK,按照接口规范传入相关参数,比如 ID、名称、页面、控件等通用参数,还有业务逻辑数据等,SDK 将这些数据通过 HTTP 的方式发送到后端服务器。
自动化埋点
自动化埋点则是通过一个前端程序 SDK,自动收集全部用户操作事件,然后全量上传到后端服务器。自动化埋点有时候也被称作无埋点,意思是无需埋点,实际上是全埋点,即全部用户操作都埋点采集。自动化埋点的好处是开发工作量小,数据规范统一。缺点是采集的数据量大,很多数据采集来也不知道有什么用,白白浪费了计算资源,特别是对于流量敏感的移动端用户而言,因为自动化埋点采集上传花费了大量的流量,可能因此成为卸载应用的理由,这样就得不偿失了。在实践中,有时候只是针对部分用户做自动埋点,抽样一部分数据做统计分析。
可视化埋点
介于手工埋点和自动化埋点之间的,还有一种方案是可视化埋点。通过可视化的方式配置哪些前端操作需要埋点,根据配置采集数据。可视化埋点实际上是可以人工干预的自动化埋点。
爬虫系统
通过网络爬虫获取外部数据也是公司大数据的重要来源之一。有些数据分析需要行业数据支撑,有些管理和决策需要竞争对手的数据做对比,这些数据都可以通过爬虫获取。
对于百度这样的公开搜索引擎,如果遇到网页声明是禁止爬虫爬取的,通常就会放弃。但是对于企业大数据平台的爬虫,常常被禁止爬取的数据才是真正需要的数据,比如竞争对手的数据。被禁止爬取的应用通常也会采用一些反爬虫技术,比如检查请求的 HTTP 头信息是不是爬虫,以及对参数进行加密等。遇到这种情况,需要多花一点技术手段才能爬到想要的数据。
小结
引用极客时间专栏李智慧老师的小结,这一段确实让我醍醐灌顶
各种形式的数据从各种数据源导入到大数据平台,进行数据处理计算后,又将数据导出到数据库,完成数据的价值实现。输入的数据格式繁杂、数据量大、冗余信息多,而输出的数据则结构性更好,用更少的数据包含了更多的信息,这在热力学上,被称作熵减。
熵是表征系统无序状态的一个物理学参量,系统越无序、越混乱,熵越大。我们这个宇宙的熵一刻不停地在增加,当宇宙的熵达到最大值的时候,就是宇宙寂灭之时。虽然宇宙的熵在不停增加,但是在局部,或者某些部分、某些子系统的熵却可以减少。
比如地球,似乎反而变得更加有序,熵正在减少,主要原因在于这些熵在减少的系统在吸收外部能量,地球在吸收太阳的能量,实现自己熵的减少。大数据平台想要实现数据的熵的减少,也必须要吸收外部的能量,这个能量来自于工程师和分析师的算法和计算程序。
如果算法和程序设计不合理,那么熵可能就不会下降多少,甚至可能增加。所以大数据技术人员在审视自己工作的时候,可以从熵的视角看看,是不是输出了更有价值、更结构化的数据,是不是用更少量的数据包含了更多的信息。
人作为一个系统,从青壮到垂老,熵也在不停增加。要想减缓熵增的速度,必须从外部吸收能量。物质上,合理饮食,锻炼身体;精神上,不断学习,参与有价值的工作。那些热爱生活、好好学习、积极工作的人是不是看起来更年轻,而整日浑浑噩噩的人则老得更快。
思考题
前面提到,爬虫在采集数据的时候,可能会遇到对方的反爬虫策略,反爬虫策略有哪些?如何应对这些反爬虫策略?
来自极客时间的精选留言
大神1
反爬虫策略:
网页时代,验证header&签名,动态加载,反selenium/phantomjs,ip封禁,有毒数据,动态爬虫阈值(过了阈值后依然允许爬一阵再封禁),各种验证码,云厂商反爬模式识别
app时代,ios和安卓的反逆向,比如安卓的加壳,代码混淆,强制登录token,账户管理,反抓包(ssl pin),包签名校验,反注入(监测),so,LLVM混淆,反Hook,异常账号识别,模式识别
应对这些反爬虫策略:
网页,从简单的header伪装,机器学习验证码,验证码打码平台,ip代理商,反动态抓取校验,阈值报警,多策略爬取校验
应对手机反爬:这个是逆向安全团队,加壳有脱壳,账号有养账号,短信打码平台,反抓包有xposed切面hook,反sslpinning,签名校验有调试关闭,so包有模拟环境调用,IDA调试。脚本精灵抓包。
当爬虫发现爬取收益小于爬取代价,又没法改变,无利可图的时候,就应该放弃。
大神2
通过这一节的学习,用煽减来看待大数据平台。
整个过程通过初始的数据获取,包括从数据库导入数据,有Sqoop,cancal的方式,日志系统导入数据,有Flume将数据库导入到HDFS中,SDK从前端埋点获取数据,及爬虫系统获取数据。
通过这些途径获取的数据经过大数据产品的数据处理返回给数据库处理过后的数据,这样得到的数据清洗有用的数据。
这就是一个大数据煽减的过程。
该笔记摘录自极客时间课程
《从0开始学大数据》















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









