









将多个csv文件中的一列,合成到一个csv
需求:搜索多个嵌套文件夹中的csv文件,将特定列,合并到一个csv
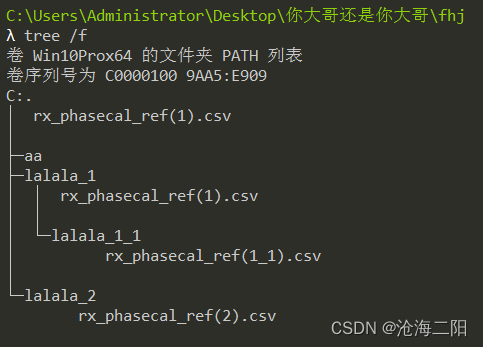
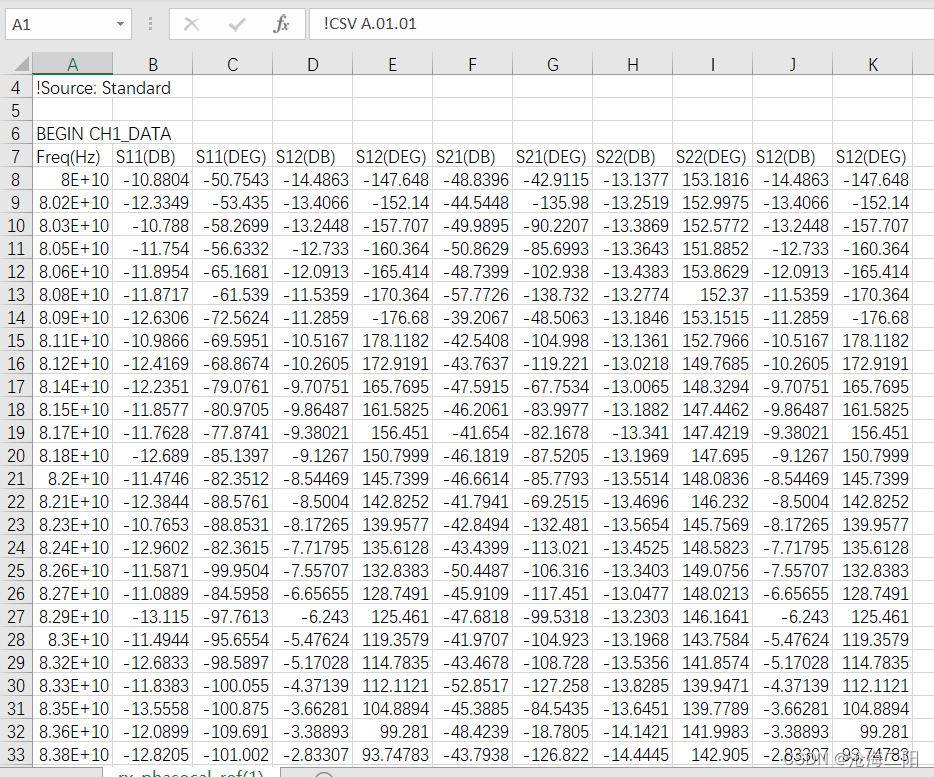
代码:
import csv
import os
import pandas as pd
root_path = os.path.join(os.path.dirname(os.path.abspath("__file__")), 'fhj')
df_S11 = pd.DataFrame()
df_S21 = pd.DataFrame()
def get_loss_S11S21(file_path):
with open(file_path) as f:
file_name = os.path.basename(file_path)
f_csv = csv.reader(f) # 获取可迭代对象
FreqS11 = [] # 存放S11频率值
S11 = [] # 存放S11数据
FreqS21 = [] # 存放S21频率值
S21 = [] # 存放S21数据
for raw in f_csv: # 遍历可迭代对象,获取数据
if len(raw) == 11:
FreqS11.append(raw[0])
s11 = raw[1] # 获取S11(DB)的值
S11.append(s11)
elif len(raw) == 5:
FreqS21.append(raw[0])
s21 = raw[1] # 获取S11(DB)的值
S21.append(s21)
return file_name, FreqS11, S11, FreqS21, S21
def press_data(file_path):
res = get_loss_S11S21(file_path)
header, FreqS11, S11, FreqS21, S21 = res[0], res[1], res[2], res[3], res[4]
df_S11[FreqS11[0]] = FreqS11[1:]
df_S11[header] = S11[1:]
df_S21[FreqS21[0]] = FreqS21[1:]
df_S21[header] = S21[1:]
def save_csv():
df_S11.to_csv("S11.csv", index=False)
df_S21.to_csv("S21.csv", index=False)
def recur_dir(path): # 递归文件
if os.path.isdir(path):
file_list = os.listdir(path)
for file in file_list:
path_new = os.path.join(path, file)
if os.path.isdir(path_new):
recur_dir(path_new)
else:
print("正在处理文件:%s" % path_new)
press_data(path_new)
else:
print("请正确防止文件夹!")
if __name__ == "__main__":
recur_dir(root_path)
save_csv()
结果:
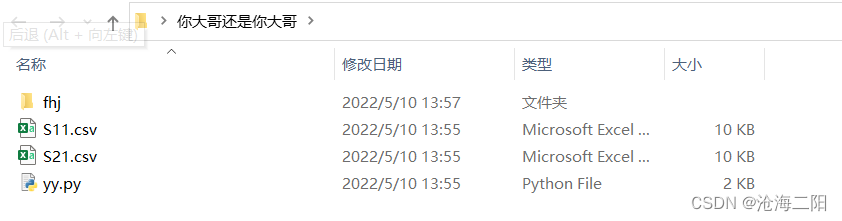
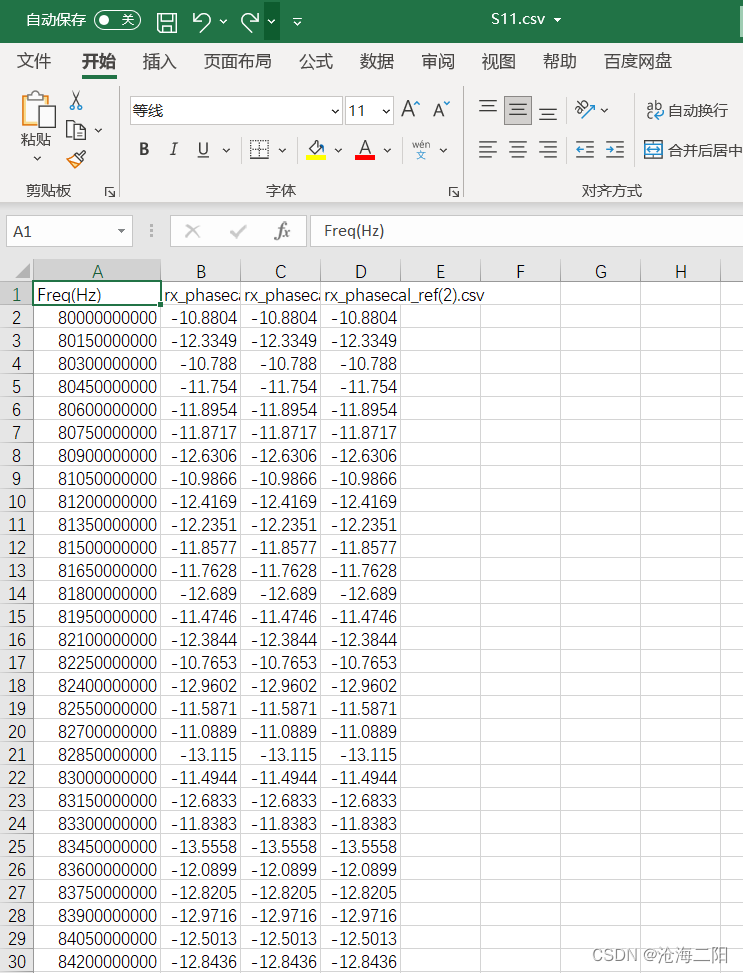















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









