








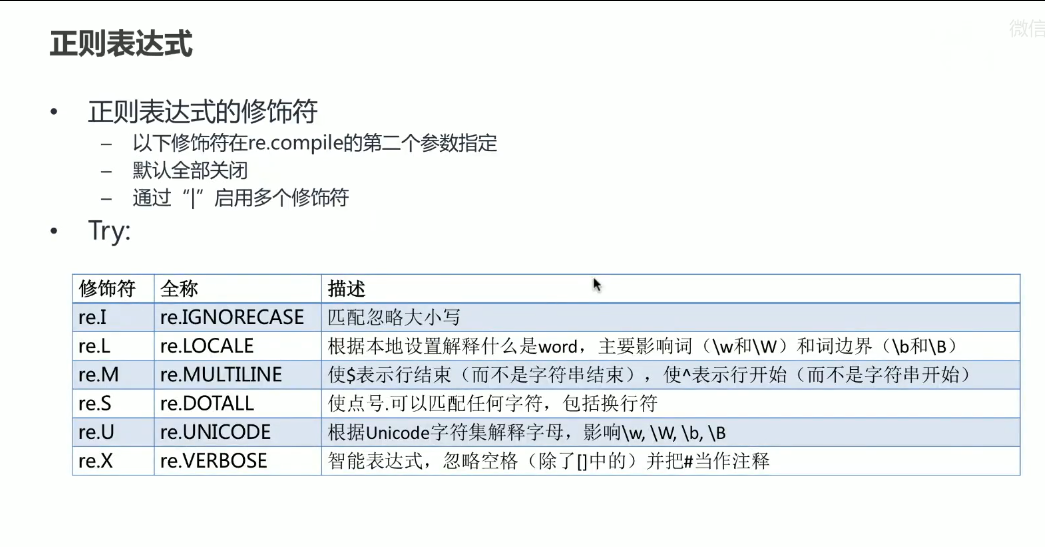
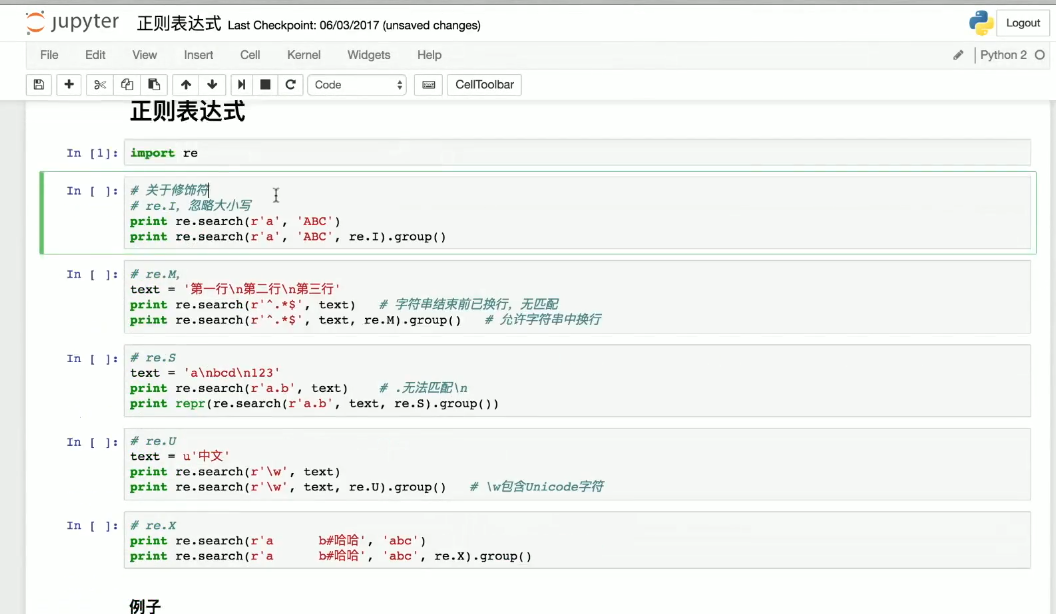
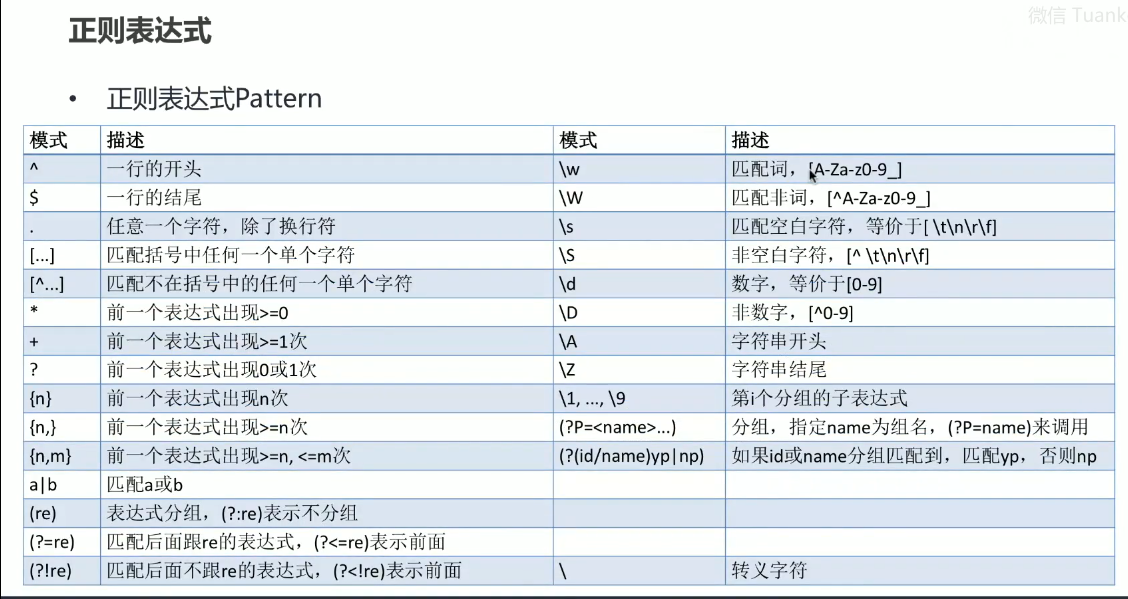
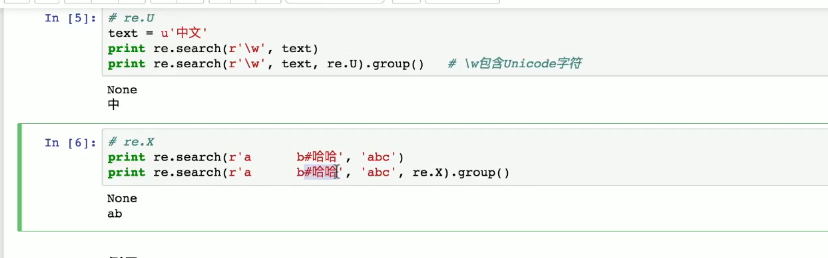
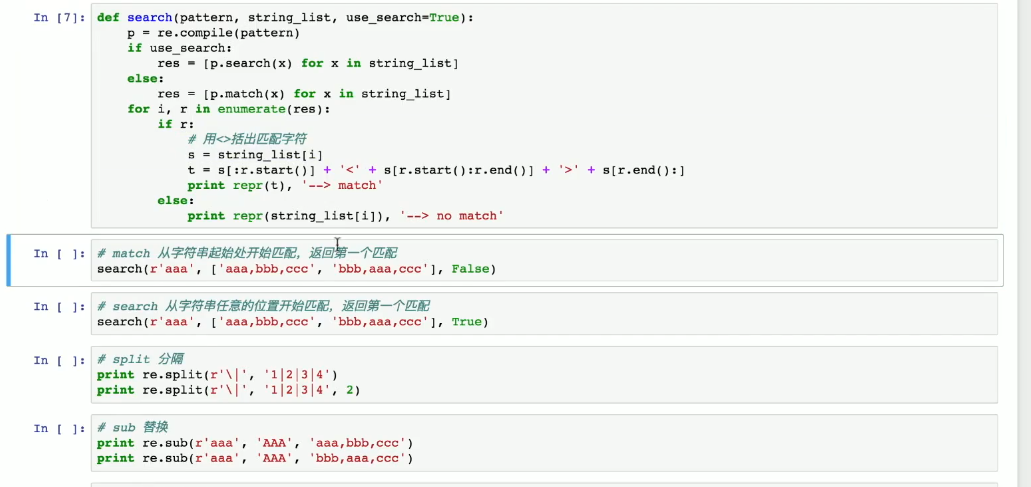

import re # 导入正则表达式模块
def search(pattern, string_list, use_search=True):
# 定义函数search,参数pattern为正则表达式模式,string_list为字符串列表,use_search为布尔值(默认True)
p = re.compile(pattern) # 编译正则表达式pattern,返回正则表达式对象p,提高后续匹配效率
if use_search: # 如果use_search为True
res = [p.search(x) for x in string_list] # 对string_list中每个字符串x,用p.search(x)搜索(从任意位置找第一个匹配),结果存入res列表
else: # 否则(use_search为False)
res = [p.match(x) for x in string_list] # 对string_list中每个字符串x,用p.match(x)匹配(从起始位置开始匹配),结果存入res列表
for i, r in enumerate(res): # 遍历res列表,i为索引,r为每个匹配结果
if r: # 如果r不为None(即有匹配)
s = string_list[i] # 取当前字符串s
t = s[:r.start()] + '<' + s[r.start():r.end()] + '>' + s[r.end():] # 构造t,将匹配部分用<>标注,r.start()为匹配开始位置,r.end()为结束位置
print(repr(t), '---> match') # 打印t的repr形式(显示字符串内容及类型),并标注'match'表示有匹配
else: # 如果r为None(即无匹配)
print(repr(string_list[i]), '---> no match') # 打印原字符串的repr形式,并标注'no match'表示无匹配
# 以下是示例部分:
# match示例:从字符串起始处开始匹配
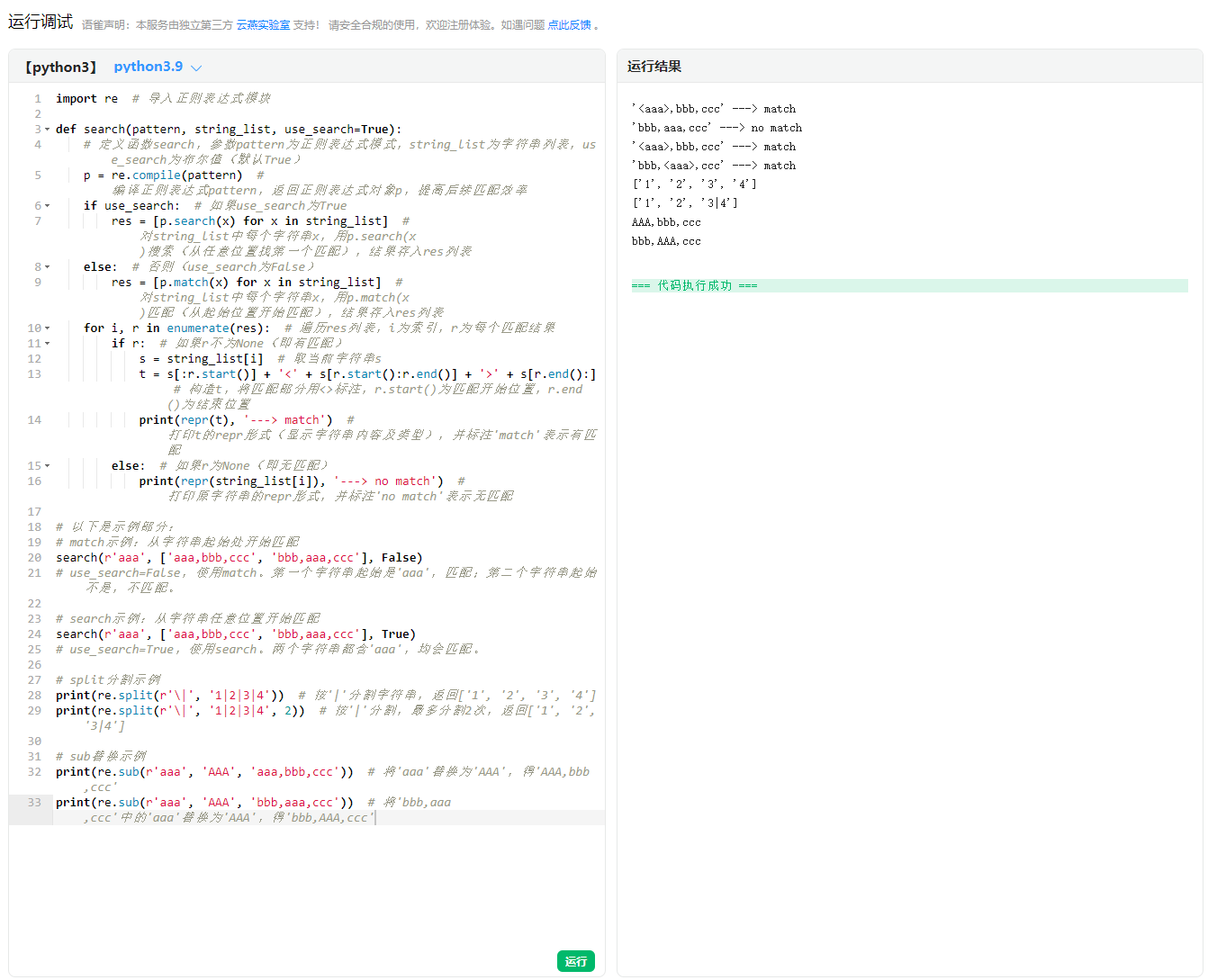
search(r'aaa', ['aaa,bbb,ccc', 'bbb,aaa,ccc'], False)
# use_search=False,使用match。第一个字符串起始是'aaa',匹配;第二个字符串起始不是,不匹配。
# search示例:从字符串任意位置开始匹配
search(r'aaa', ['aaa,bbb,ccc', 'bbb,aaa,ccc'], True)
# use_search=True,使用search。两个字符串都含'aaa',均会匹配。
# split分割示例
print(re.split(r'\|', '1|2|3|4')) # 按'|'分割字符串,返回['1', '2', '3', '4']
print(re.split(r'\|', '1|2|3|4', 2)) # 按'|'分割,最多分割2次,返回['1', '2', '3|4']
# sub替换示例
print(re.sub(r'aaa', 'AAA', 'aaa,bbb,ccc')) # 将'aaa'替换为'AAA',得'AAA,bbb,ccc'
print(re.sub(r'aaa', 'AAA', 'bbb,aaa,ccc')) # 将'bbb,aaa,ccc'中的'aaa'替换为'AAA',得'bbb,AAA,ccc'运行结果:













以下是对这段代码的详细讲解:
代码功能概述
这段Python代码主要利用re(正则表达式)模块,通过re.search函数在给定字符串中查找符合特定模式的内容,并提取其中分组匹配到的子字符串。
代码逐行分析
- 注释部分
# (...) 表达式分组?这是一个注释,说明接下来代码中使用的正则表达式里,圆括号(...)起到分组的作用。在正则表达式中,分组可以方便提取匹配到的特定部分内容。 - 正则表达式匹配部分
f = re.search(r'a=(.*),b=(.*)$', 'a=100,b=200')
-
re.search是Python中re模块提供的函数,用于在字符串中搜索匹配正则表达式的第一个位置。它会扫描整个字符串,一旦找到符合模式的部分就返回一个匹配对象(Match object),如果没有找到则返回None。r'a=(.*),b=(.*)$'是正则表达式模式:
-
-
r表示这是一个原始字符串(raw string),在原始字符串中,反斜杠\不会被当作转义字符,这样可以避免很多因转义带来的麻烦,在写正则表达式时经常使用。a=表示匹配字符a紧接着一个=。(.*)是一个分组,其中.*表示匹配任意数量(包括0个)的任意字符。这个分组会捕获=后面到下一个逗号之间的所有字符。,b=表示匹配字符,紧接着b再紧接着一个=。(.*)是第二个分组,会捕获第二个=后面直到字符串结尾的所有字符。$是正则表达式的锚定符号,表示匹配字符串的结尾,确保整个模式要匹配到字符串的末尾位置。
-
-
'a=100,b=200'是待匹配的目标字符串。re.search会在这个字符串中寻找符合前面正则表达式模式的内容。在这个例子中,它能成功匹配,因为字符串'a=100,b=200'满足a=后面有内容,然后是,和b=后面也有内容直到结尾这样的模式。
- 提取分组内容部分
print(f.groups())
groups()是Match object(这里的f就是Match object)的一个方法,用于返回一个包含所有分组捕获到的子字符串的元组。在前面的正则表达式中,我们定义了两个分组(.*),第一个分组捕获到了100,第二个分组捕获到了200,所以f.groups()会返回('100', '200'),print(f.groups())这行代码的作用就是把这个包含分组内容的元组打印输出。
综上,这段代码运行后,会在控制台打印出('100', '200') ,实现了从给定字符串中提取特定格式数据的功能。

以下是对这段代码的详细介绍:
代码功能概述
这段Python代码使用re模块(正则表达式模块),通过re.search函数在给定字符串中查找符合特定正则表达式模式的内容,并提取其中分组匹配到的子字符串。
代码逐行解析
- 注释部分
# (...) 表达式分组, 重复调用
这是一条注释,说明接下来的代码中使用的正则表达式里圆括号(...)用于分组,并且该正则表达式会涉及分组的重复匹配相关操作。 - 正则表达式匹配部分
f = re.search(r'(a=)(\d+),.*?\1(\d+)', 'a=100,b=200,a=300')
-
re.search函数:是re模块中的函数,作用是在字符串中搜索符合正则表达式模式的内容,只要找到第一个匹配的部分就返回一个匹配对象(Match object),若未找到则返回None。- 正则表达式模式
r'(a=)(\d+),.*?\1(\d+)':
-
-
r:表示原始字符串(raw string)。在原始字符串中,反斜杠\不会被当作转义字符处理,这在编写正则表达式时能避免很多因转义产生的问题。(a=):这是第一个分组。它会匹配字符a紧接着一个=,并且将匹配到的内容(即a=)作为一个分组捕获起来。(\d+):这是第二个分组。\d表示匹配一个数字字符,+表示前面的字符(这里是数字字符)出现1次或多次,整体会匹配一个或多个连续的数字,并将其捕获为一个分组。,:匹配字符,。.*?:.*表示匹配任意数量(包括0个)的任意字符,?是使.*变为非贪婪模式,即尽可能少地匹配字符。\1:这是一个反向引用。\1表示引用前面第一个分组(也就是(a=)分组)匹配到的内容。在这里它用于确保后面再次出现的内容和第一个分组匹配的内容一致,即再次出现a=。(\d+):这是第三个分组,和第二个分组类似,会匹配并捕获一个或多个连续的数字。
-
-
- 待匹配字符串
'a=100,b=200,a=300':re.search函数会在这个字符串中寻找符合上述正则表达式模式的内容。在这个例子中,它会匹配到a=100以及后面再次出现的a=300部分。
- 待匹配字符串
- 提取分组内容部分
print(f.groups())
groups()是匹配对象(Match object,这里的f就是一个Match object)的方法,用于返回一个包含所有分组捕获到的子字符串的元组。在前面的正则表达式中,定义了三个分组,第一个分组捕获到a=,第二个分组捕获到100,第三个分组捕获到300,所以f.groups()会返回('a=', '100', '300'),print(f.groups())这行代码的作用就是把这个包含分组内容的元组打印输出。
综上所述,这段代码运行后,会在控制台打印出 ('a=', '100', '300') ,实现了从给定字符串中按照特定正则模式提取分组内容的功能。

代码总体目的
这段Python代码主要利用re(正则表达式)模块,通过re.search函数在给定字符串中查找符合特定模式的内容,并提取其中分组匹配到的子字符串,同时展示了正则表达式中不分组的用法。
代码逐行详解
- 注释部分
# (?:) 表达式不分组
这是一条注释,指出接下来代码中会涉及到正则表达式里(?:)这种不分组的语法结构。在正则表达式中,通常圆括号()用于分组并捕获内容,但(?:)同样可以对表达式进行组合,却不会将其作为捕获组,即不会被groups()等方法提取。 - 第一组代码
-
f = re.search(r'a=(?:.*?),b=(.*)$', 'a=100,b=200')
-
-
re.search是re模块中的函数,用于在字符串中搜索匹配正则表达式的第一个位置,返回匹配对象(若找到匹配)或None(若未找到) 。- 正则表达式
r'a=(?:.*?),b=(.*)$':
-
-
-
-
r表示原始字符串,防止反斜杠被错误转义。a=:匹配字符a紧接着=。(?:.*?):(?:)是不分组语法,.*?表示以非贪婪模式匹配任意数量的任意字符。这里使用(?:)意味着虽然它匹配了a和b之间的内容,但这部分内容不会被当作一个捕获组。,b=:匹配字符,紧接着b紧接着=。(.*):这是一个分组,以贪婪模式匹配b=后面直到字符串结尾的任意字符。$:匹配字符串结尾。
-
-
-
-
- 待匹配字符串
'a=100,b=200',re.search在其中寻找符合上述模式的内容。
- 待匹配字符串
-
-
print f.groups()
-
-
groups()是匹配对象f(re.search返回的匹配对象)的方法,用于返回一个包含所有捕获组内容的元组。由于前面只有(.*)这个分组是捕获组,所以这里会返回包含b后面匹配内容的元组,即('200',)。
-
- 第二组代码
-
f = re.search(r'a=(.*?)(?:b|bc)=(.*)$', 'a=100,bc=200')
-
-
- 正则表达式
r'a=(.*?)(?:b|bc)=(.*)$':
- 正则表达式
-
-
-
-
a=:匹配字符a紧接着=。(.*?):这是一个分组,以非贪婪模式匹配a=后面的任意字符。(?:b|bc):(?:)不分组,b|bc表示匹配b或者bc,这里只是组合条件判断,不捕获内容。=(.*):匹配=,然后以贪婪模式匹配后面直到字符串结尾的任意字符,并作为一个分组捕获。$:匹配字符串结尾。
-
-
-
-
- 待匹配字符串
'a=100,bc=200',re.search在其中查找符合模式的部分。
- 待匹配字符串
-
-
print f.groups()
-
-
- 这里有两个捕获组
(.*?)和(.*),groups()方法会返回包含这两个捕获组内容的元组,即('100', '200')。
- 这里有两个捕获组
-
代码总结
这段代码通过两个示例,展示了正则表达式中(?:)不分组语法的使用。在实际应用中,不分组语法可以在需要组合条件但又不想额外增加捕获组时使用,这样在调用groups()等提取捕获组内容的方法时,结果会更简洁、符合预期,避免不必要的分组干扰。

代码总体功能
这段Python代码使用正则表达式模块re,通过自定义函数search(图中未展示其定义)来对给定字符串列表进行正则匹配,主要展示了正则表达式中(?=re)这种正向先行断言的用法。
代码详细解读
- 注释部分
# (?=re) 匹配后面跟re的表达式
这是一条注释,说明接下来代码中使用的正则表达式语法(?=re)的含义。(?=re)是正向先行断言,其中re代表一个正则表达式模式,它的作用是匹配位置,要求当前位置后面的内容能匹配re,但并不消耗后面的字符,即不会把断言匹配的内容作为匹配结果的一部分。 - 函数调用部分
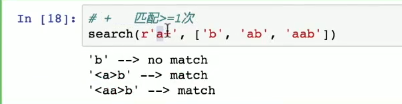
search(r'a(?=123)', ['abc', 'a12', 'abca123'])
-
search:从代码上下文推测,这是一个自定义函数(图中未展示具体定义),应该是封装了re模块的相关功能,用于在字符串列表中进行正则匹配操作。r'a(?=123)':这是传递给search函数的正则表达式模式。
-
-
r:表示原始字符串,防止反斜杠被错误转义。a:匹配字符a。(?=123):正向先行断言,要求在字符a后面紧接着能匹配123,但123本身不会被包含在最终的匹配结果里。
-
-
['abc', 'a12', 'abca123']:这是传递给search函数的字符串列表,函数会依次对列表中的每个字符串按照给定的正则表达式模式进行匹配。
- 匹配结果部分
-
'abc' ---> no match:对于字符串'abc',其中虽然有字符a,但a后面不是123,不满足a(?=123)的匹配条件,所以没有匹配,输出no match。'a12' ---> no match:字符串'a12'中a后面是12,不是123,不符合正向先行断言的要求,因此没有匹配,输出no match。'abca123' --> match:在字符串'abca123'中,存在字符a,并且这个a后面紧接着是123,满足a(?=123)的匹配条件,所以能匹配上,输出match,同时将匹配的a用<>标注出来,显示为'abc<a>123'。
代码总结
这段代码利用正向先行断言(?=re)的特性,在字符串列表中筛选出符合特定后续字符模式要求的字符串。正向先行断言在实际应用中常用于在不改变匹配结果内容的前提下,对匹配位置进行条件限制,比如在文本处理中筛选特定格式的字符串等场景。

搜索匹配a后面不出现123的字符

搜索匹配a前面出现123的字符串

搜索匹配a前面不出现123的字符串

代码总体功能
这段Python代码主要功能是利用正则表达式来判断一个数是整数还是只有2位小数的小数,通过自定义的search函数(图中未展示其定义)对给定字符串列表进行正则匹配,并输出匹配结果。
代码详细解读
- 注释部分
-
# (?(id/name)yp|np) 条件匹配:这是对正则表达式中条件匹配语法的说明。(?(id/name)yp|np)表示如果前面名为id/name的分组有匹配成功,就尝试匹配yp部分;否则尝试匹配np部分。# 判断一个数是整数还是只有2个小数位的小数:明确了这段代码使用正则表达式要实现的具体业务逻辑。
- 正则表达式及函数调用部分
search(r'^(?(has_dot)\d+\.?|\d+\.\d{2})$', ['123', '1.23', '123.34', '1.234', '1.23a', 'a.23'])
-
search:推测是自定义函数,封装了re模块相关操作,用于在字符串列表中进行正则匹配。- 正则表达式
r'^(?(has_dot)\d+\.?|\d+\.\d{2})$':
-
-
r:原始字符串标识,防止反斜杠转义问题。^:匹配字符串的起始位置。(?(has_dot)\d+\.?|\d+\.\d{2}):条件匹配部分。
-
-
-
-
(has_dot):这里是一个命名分组,不过在这个正则里它更像是一个标记分组,用于后续条件判断。(?(has_dot)\d+\.?|\d+\.\d{2})表示如果前面has_dot分组有匹配(这里实际是看是否匹配到小数点相关内容 ),就尝试匹配\d+\.?,即一个或多个数字后面跟一个可选的小数点;否则尝试匹配\d+\.\d{2},即一个或多个数字后跟小数点再跟恰好2个数字。
-
-
-
-
$:匹配字符串的结束位置。
-
-
['123', '1.23', '123.34', '1.234', '1.23a', 'a.23']:待匹配的字符串列表。
- 匹配结果部分
-
'123' --> match:字符串'123',从起始到结束符合\d+(属于(?(has_dot)\d+\.?分支 ),匹配成功。'123.' --> no match:字符串'123.',小数点后无数字,不满足(?(has_dot)\d+\.?|\d+\.\d{2})的规则,匹配失败。'1.23' --> match:字符串'1.23',符合\d+\.\d{2},匹配成功。'12.34' --> match:字符串'12.34',符合\d+\.\d{2},匹配成功。'1.234' --> no match:字符串'1.234',小数点后有3位数字,不满足\d+\.\d{2},匹配失败。'1.23a' --> no match:字符串中包含字母a,不满足整数或2位小数的规则,匹配失败。'a.23' --> no match:起始字符为字母a,不满足整数或2位小数的规则,匹配失败。
代码总结
这段代码通过正则表达式中的条件匹配语法,结合自定义的search函数,对字符串列表中的数进行模式匹配,判断其是否为整数或2位小数的小数,并输出相应匹配结果,展示了正则表达式在数据格式判断方面的应用。



















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











