







序言
Redis 除了我们所熟知的缓存功能之外,还通过 RedisJSON、RediSearch、RedisTimeSeries、RedisBloom 等模块支持了 JSON 数据、查询与搜索(包括全文搜索、向量搜索、GEO 地理位置等)、时序数据、概率计算等等扩展功能。这些模块既可以按需导入,也被全部打包到了 Redis Stack 中方便我们直接使用。
本文将会简述 Redis 如何作为向量数据库使用。
Redis 作为向量数据库
假设我们使用 Redis 来完成以图搜图服务,核心数据有:
photoID:每个图片的唯一IDuserID:图片所属的用户ID,后续查询时可以作为过滤条件vector:每个图片的特性向量
创建索引 & 插入向量
为此,我们使用 JSON 格式来保存数据,并使用 FT.CREATE 命令创建索引(由于向量计算的特殊性,必须创建索引才能进行搜索):
FT.CREATE photos ON JSON
PREFIX 1 photoID: SCORE 1.0
SCHEMA
$.userID as userID NUMERIC
$.vector AS vector VECTOR FLAT 6 TYPE FLOAT32 DIM 512 DISTANCE_METRIC L2
上述命令的意思是:
- 我们基于 JSON 创建了一个名为 photos 的索引
- 该索引作用于前缀为
photoID:的所有 key - JSON 数据中有两个字段:
- 一个字段是 userID ,类型为
NUMERIC数字 - 另一个字段是 vector,类型为
VECTOR向量,该向量字段使用的相似性算法是FLAT(目前只支持FLAT和HNSW),6表示命令后面跟着 6 个参数,TYPE FLOAT32表示向量中元素的类型,DIM 512表示向量的维度是 512,DISTANCE_METRIC L2表示计算向量距离使用的是 L2 欧几里得距离(除了L2之外还支持IP内积和COSINE余弦距离)
- 一个字段是 userID ,类型为
代码示例(已经有很多文章示例用的 Python,本文决定用 Go 来实现):
package redis_test
import (
"bytes"
"context"
"encoding/binary"
"encoding/json"
"fmt"
"math/rand"
"strconv"
"github.com/redis/go-redis/v9"
)
func GenVectorArr(dim int) []float32 {
vectors := make([]float32, dim)
for i := 0; i < dim; i++ {
vectors[i] = rand.Float32()
}
return vectors
}
type Photos struct {
ID int `json:"-"`
UserID int `json:"userID"`
Vector []float32 `json:"vector"`
}
var rds *redis.Client
func getRedisClient() *redis.Client {
if rds == nil {
rds = redis.NewClient(&redis.Options{
Addr: "your-redis-host",
Username: "xxxx",
Password: "xxxx",
})
}
return rds
}
func CreateVector() {
rdb := getRedisClient()
ctx := context.Background()
rdb.FlushAll(ctx)
// 创建索引:
// FT.CREATE photos ON JSON
// PREFIX 1 photoID: SCORE 1.0
// SCHEMA
// $.userID as userID NUMERIC
// $.vector AS vector VECTOR FLAT 6 TYPE FLOAT32 DIM 512 DISTANCE_METRIC L2
val, err := rdb.Do(ctx, "FT.CREATE", "photos", "ON", "JSON", "PREFIX", "1", "photoID:", "SCORE", "1.0", "SCHEMA", "$.userID", "as", "userID", "NUMERIC", "$.vector", "as", "vector", "VECTOR", "FLAT", "6", "TYPE", "FLOAT32", "DIM", "512", "DISTANCE_METRIC", "L2").Result()
if err != nil {
panic(err)
}
fmt.Println("FT.CREATE:", val.(string))
// 插入 1000 个向量
for i := 0; i < 1000; i++ {
photo := Photos{
ID: 100000 + i,
UserID: 200000 + (i / 100),
Vector: GenVectorArr(512),
}
photobytes, _ := json.Marshal(photo)
if r := rdb.JSONSet(ctx, "photoID:"+strconv.Itoa(photo.ID), "$", photobytes); r.Err() != nil {
panic(r.Err())
}
}
}
示例中,我们使用 JSON.SET 插入了 1000 个随机生成的 512 维向量。
查看单个数据占用的内存大小可以使用 JSON.DEBUG MEMORY 命令:
> JSON.DEBUG memory photoID:100000
(integer) 16552
可以看到我们的单条数据使用了约 16 KB 内存,以此类推 1000 条数据需要 16 MB 内存,1 百万数据需要 16 GB 内存。
查看索引信息则可以使用 FT.INFO 命令。
向量搜索
向量搜索使用的命令是 FT.SEARCH。
搜索示例 1:
FT.SEARCH photos "*=>[KNN 10 @vector $BLOB AS my_scores]"
RETURN 1 $.userID
PARAMS 2
BLOB "查询向量"
SORTBY my_scores
DIALECT 2
含义是:
- 在 photos 索引上进行向量搜索,
"*=>[KNN 10 @vector $BLOB AS my_scores]"搜索范围是*既索引的全部数据,执行的是 KNN 搜索,返回 10 个文档,搜索字段是 vector,相似度分数定义为 my_scoresRETURN 1 $.userID搜索结果只返回 userID 字段(由于 vector 字段比较大,取回会浪费网络传输时间,所以用不到的话就忽略)PARAMS 2两个查询参数BLOB "查询向量"通过二进制传输查询向量SORTBY my_scores排序DIALECT 2执行查询的 dialect 版本
搜索示例 2,增加预过滤:
FT.SEARCH photos "(@userID:[200000,200000])=>[KNN $K @vector $BLOB AS my_scores]"
RETURN 1 $.userID
PARAMS 4
BLOB "查询向量"
K 3
SORTBY my_scores
DIALECT 2
通过设置 userID 的范围对索引中的部分数据进行向量搜索。
代码示例:
// Float32SliceToBytes converts a []float32 to a byte slice (BLOB).
func Float32SliceToBytes(data []float32) ([]byte, error) {
buf := new(bytes.Buffer)
err := binary.Write(buf, binary.LittleEndian, data)
if err != nil {
return nil, err
}
return buf.Bytes(), nil
}
func SearchVector() {
rdb := getRedisClient()
ctx := context.Background()
// 构造查询向量
searchVector := GenVectorArr(512)
searchBlob, _ := Float32SliceToBytes(searchVector)
// KNN 向量搜索,对 vector 字段进行向量搜索,返回 10 个文档,按照与查询向量的距离对结果进行排序:
// FT.SEARCH photos "*=>[KNN 10 @vector $BLOB AS my_scores]" RETURN 1 $.userID PARAMS 2 BLOB "查询向量" SORTBY my_scores DIALECT 2
val, err := rdb.Do(ctx, "FT.SEARCH", "photos", "*=>[KNN 10 @vector $BLOB AS my_scores]", "RETURN", "1", "$.userID", "PARAMS", "2", "BLOB", searchBlob, "SORTBY", "my_scores", "DIALECT", "2").Result()
if err != nil {
panic(err)
}
fmt.Println("FT.SEARCH:", val)
// KNN 向量搜索,增加预过滤条件
// FT.SEARCH photos "(@userID:[200000,200000])=>[KNN $K @vector $BLOB AS my_scores]" RETURN 1 $.userID PARAMS 4 BLOB "查询向量" K 3 SORTBY my_scores DIALECT 2
r2, err := rdb.Do(ctx, "FT.SEARCH", "photos", "(@userID:[200000,200000])=>[KNN $K @vector $BLOB AS my_scores]", "RETURN", "1", "$.userID", "PARAMS", "4", "BLOB", searchBlob, "K", "3", "SORTBY", "my_scores", "DIALECT", "2").Result()
if err != nil {
panic(err)
}
fmt.Println("-------------------------")
fmt.Println("FT.SEARCH with filter total results:", r2)
}
性能
Redis 官方专门写过一篇文章 Benchmarking results for vector databases。
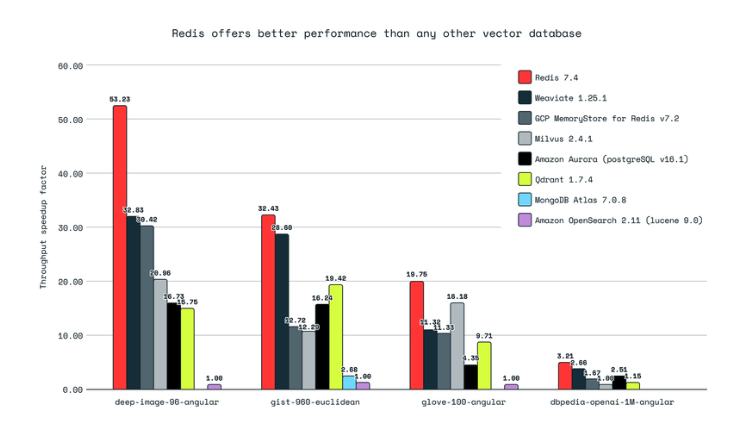
其结论就是不论是吞吐量还是搜索延时,Redis 作为向量数据库在测试中表现得最好。
另外由于向量计算比较耗时,如果仍然放在单线程中完成,一定会发生阻塞影响后续调用,所以针对搜索场景,Redis 使用了多线程的方式进行了改进:

更多信息请查阅上述官方文章。
最后,如果我们的数据量并不大,那么使用 Redis 作为向量数据库也是一个很好的选择。
参考资料:
- https://redis.io/blog/benchmarking-results-for-vector-databases/
- https://cookbook.openai.com/examples/vector_databases/redis/getting-started-with-redis-and-openai
- https://redis.io/docs/latest/develop/get-started/vector-database/
- https://redis.io/docs/latest/develop/interact/search-and-query/advanced-concepts/vectors/
- https://redis.io/docs/latest/develop/interact/search-and-query/indexing/
- https://redis.io/docs/latest/develop/interact/search-and-query/query/vector-search/















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









