







下文: 【大模型】萌新也能一文弄懂!! -- 连接图像文本的大模型CLIP的前世今生【二】
突然心血来潮,想要把之前工作中 & 各种科普论文资料 & 自己的见解和看法。 以分享&科普的 形势, 给大家看一看, 整个系列会分为三个专栏,分别介绍:
【1】CLIP (本文) 大模型的综述 & 产生的时代背景。
【2】CLIP 模型的结构,以及 相关的前置知识 (Transformer & Attention & ViT等)
【3】CLIP 的展望,以及相关的一些衍生和学术工作等。
供大家欣赏,互相学习 & 互相提升

1. 综述
2018 ~ 2020 年是属于NLP的年代, 在 NLP 甚至是学术界 还沉浸在 Bert & GPT 中 “大模型 & 大数据” 思想 带来 极强的领域效果,Base模型 强大的预训练,泛化能力的时候。 2021年 OpenAI 结合了 "大模型 & 大数据" 的思想,及 NLP&CV 众多 SOTA 的工作。 顺带发现 多模态领域 有坑位可以占 [这个相当重要], 开创性得提出了多模态近期最经典的工作: CLIP [Contrastive Language-Image Pretraining]
Paper: Learning Transferable Visual Models From Natural Language Supervision
一个基于图片-文本对的 对比式学习 的多模态预训练模型,当年发布便引发了强烈的关注。展现出了非常强大的图像 & 多模态领域识别能力, 将 NLP已成熟的 万能的预训练模型首次融入到多模态任务中。 OpenAI介绍官网
2. 整体特点
【1】极强的单一领域预测能力,CLIP 在经过 linear probe [Few-Shot, 让模型先见过少量数据,不改变骨干网络参数,后预测] 之后。在对应的领域中便展示出了极强的效果,与 SOTA 模型 相比 差不多 甚至更好的效果。
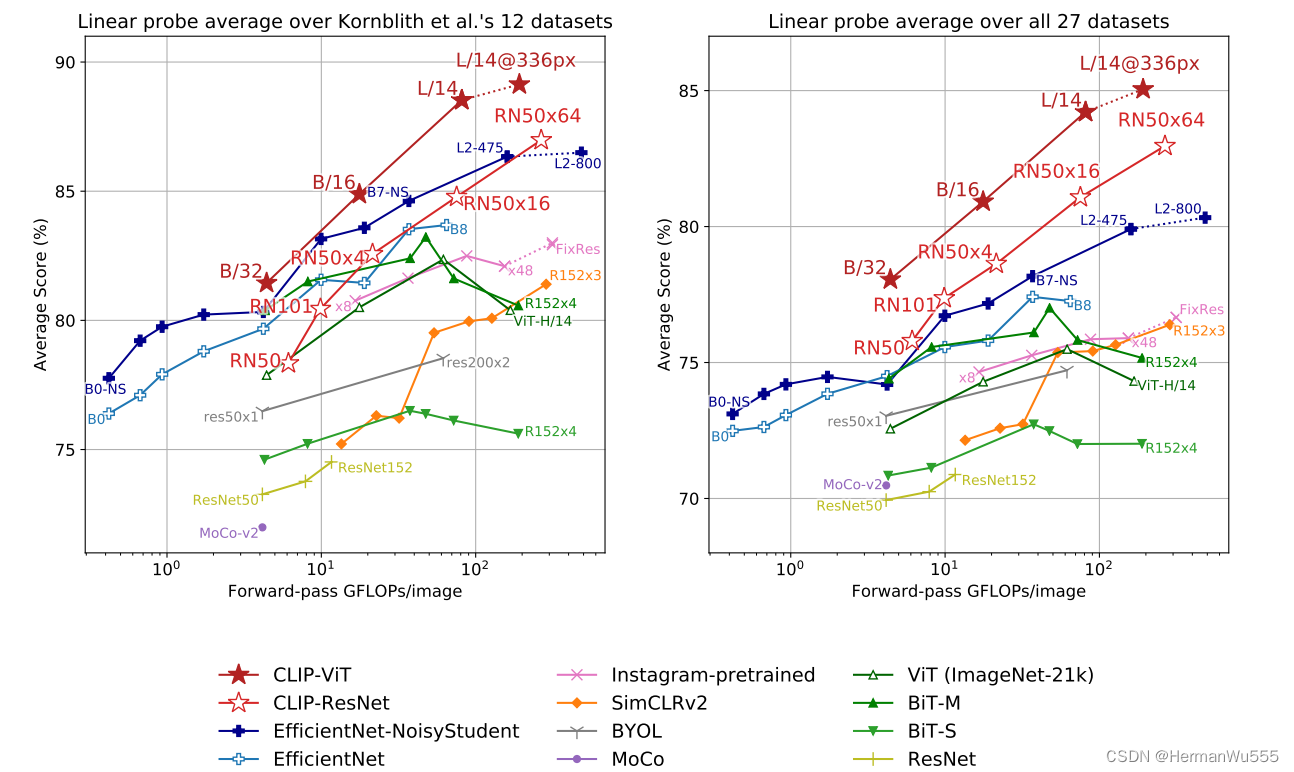
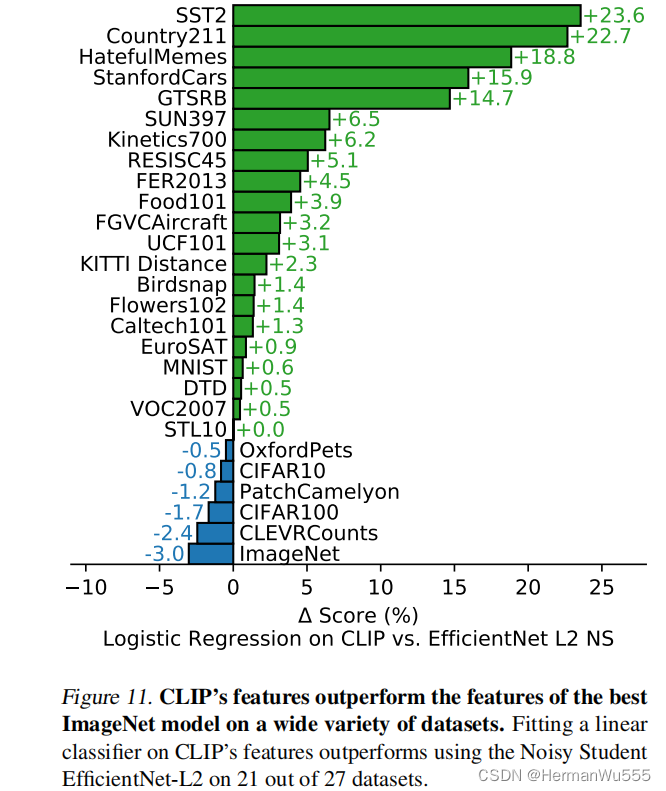
& 整体的 27个数据集任务中,few-shot 后效果都比 SOTA模型好 [Noisy-Student & viT]
3. CLIP 产生背景
3.1 "大模型 & 大数据" 趋势 ,模型具备 涌现能力
自从 BERT 模型提出来以后, NLP 领域 都朝着 模型越来越深 & 数据量越来越多的方向发展。
在数据维度上, NLP的众多子任务,虽然各不相同,但互有共性:
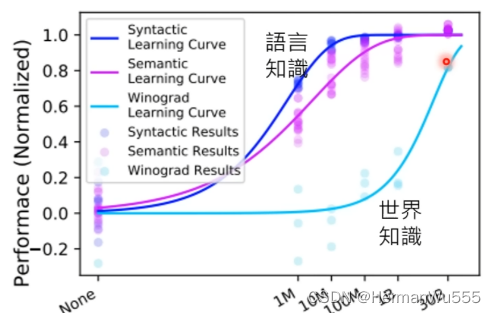
[2] 在 知识问答 & 理解 的任务中,若数据足够大,则可以从 [数据&领域知识] 抽象上升为 [常识,世界的知识], 模型的拟合能力大大提升
NLP重要子任务
| 简称 | 示意 | 例子 |
| QA | Question Answering, 问答任务。 常见为 Seq.Q -> Seq.A, 在Seq.Q 语言逻辑得基础上,于知识库中进行查询或者推理,并返回相关的结果 | Seq.Q : 中国有几个民族 Seq.A : 中国有56个民族 |
| NLI | Natural Language Inference, 自然语言推理。 常见为 Seq.1 & Seq.2 -> Inference. 通过 Seq.1 和 Seq.2 的内容,判断 这两句话的逻辑关系, 是 蕴含(Seq.2 由 Seq.1 推导而来) 矛盾 (Seq.1 和 Seq.2 是矛盾) 还是 中立 (Seq.1 和 Seq.2 没有相关) | 2、蕴含 Seq.1 : 以色列轰炸了巴勒斯坦的加沙地带 Seq.2 : 以色列和巴勒斯坦处于战争状态 2、矛盾 Seq.1 : 我在LOL上,能和Faker五五开 Seq.2 : Faker 现在是 LOL 史上最强选手, 无人能敌 3、 中立 Seq.1 : 蔚来手机发布,市场备受好评 Seq.2 : 小黑子真下头 |
| Translation | 翻译。 常见为 Seq.1 -> Seq.2, 通过将相关句子从一个语言中翻译为另外一个语言,在语境 & 语义中维持不变 | Seq.1:To be, or not to be, that is the question. Seq.2: 生存还是毁灭,这是一个问题 |
| Winograd | Winograd-Style Tasks,代词语言理解任务。 常见为 Seq.1 - (Q.1) -> A.1 测试模型中对常见问题的推理能力, 通过一段句子的介绍,理解上下文的含义,对于 文本中的 代词 能明确的知道指代的是什么 | Seq.1: The trophy doesn't fit in the brown suitcase because it's too big Q.1 : What is too big A.1 : Trophy |
| NER | Named Entity Recognition, 实体识别 常见为 Seq.1 - (Q.1) -> A.1 , 旨在从文本中识别并分类具有特定意义的实体,如人名、地名、组织名、时间、日期等。 | Seq.1: Barack Obama was born in Hawaii Q.1: Hawaii Type A.1: Location |
| NLGC | Natural Language Generation Content. 常见为 (Q.1) -> Seq.1 , 指利用计算机程序自动生成自然语言文本的任务 | 输入(长篇文章):"Scientists have discovered a new species of plant in the Amazon rainforest..." 输出(摘要):"A new plant species has been discovered in the Amazon rainforest by scientists." |
在参数维度上, NLP的众多模型参数,性能随着参数量增加并不是线性关系,而是突然跃升,即涌现。在未达到门槛之前,性能一直在随机的水平徘徊。
OpenAI 2022 年发布论文 "Language Models (Mostly) Know What They Know" 中。这篇论文介绍了 GPT-3 预训练语言模型能力,同时提到了一个叫 Calibration 的实验[模型 置信度 与真实概率 间的关系], 实验发现在参数足够大的情况下是存在很好的校准结果,但是在模型参数比较小的时候,发现模型并不具备很好的校准。
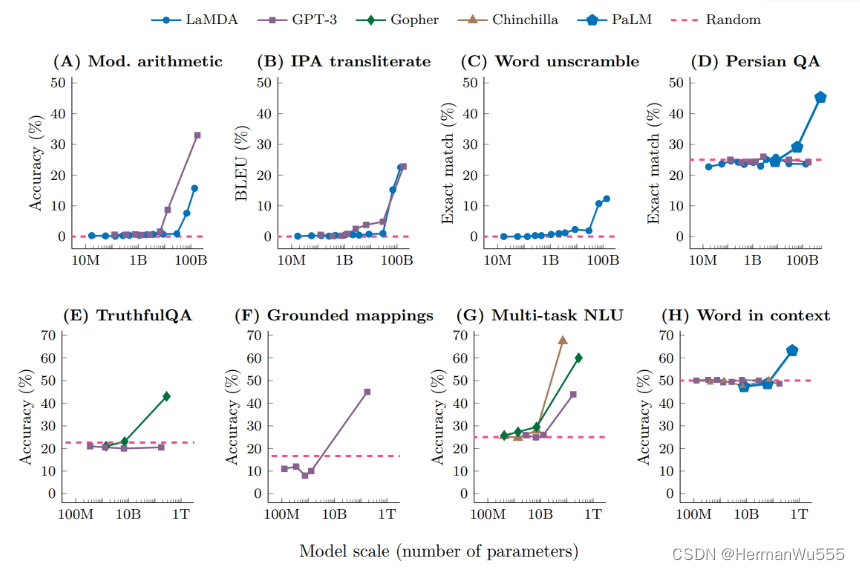
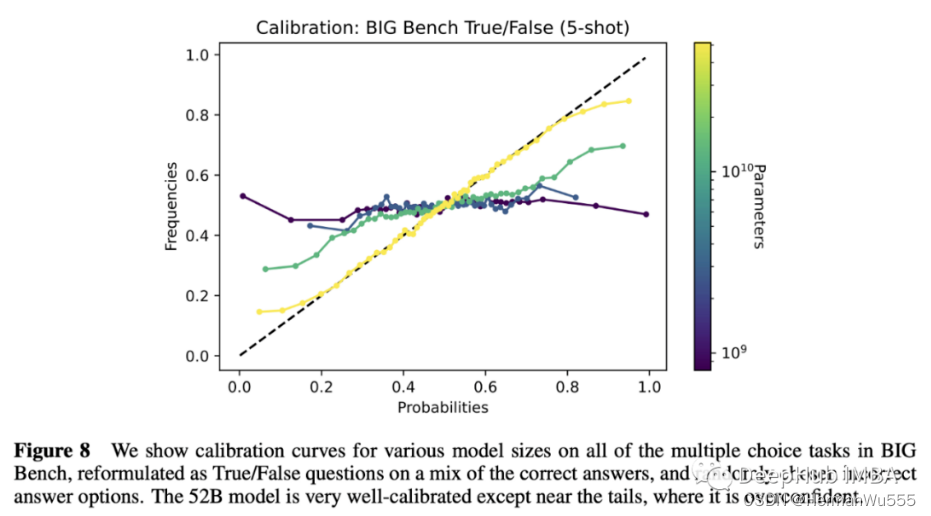
参数量大了以后,模型对于 问题的 误导信息 & 逻辑结构 & 全局理解上都会有更深层次的认识。
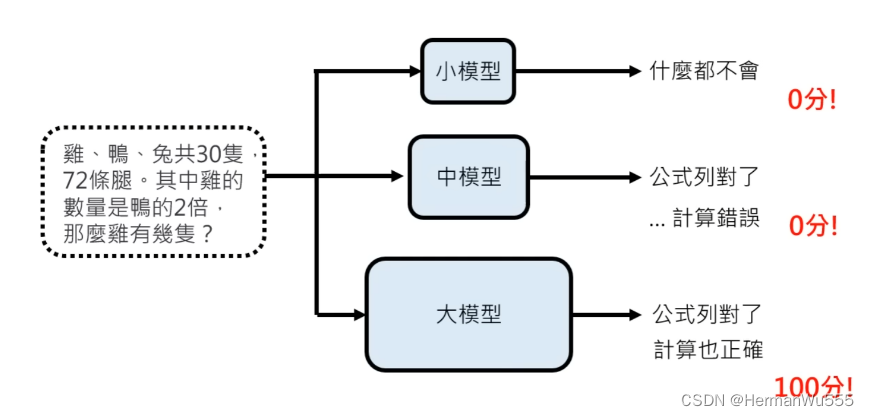
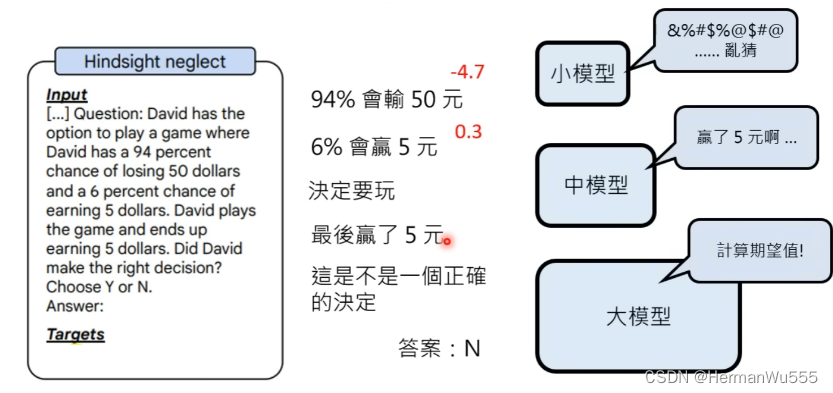
[4] 在有误导性的问题中,大模型
能更好的回答.
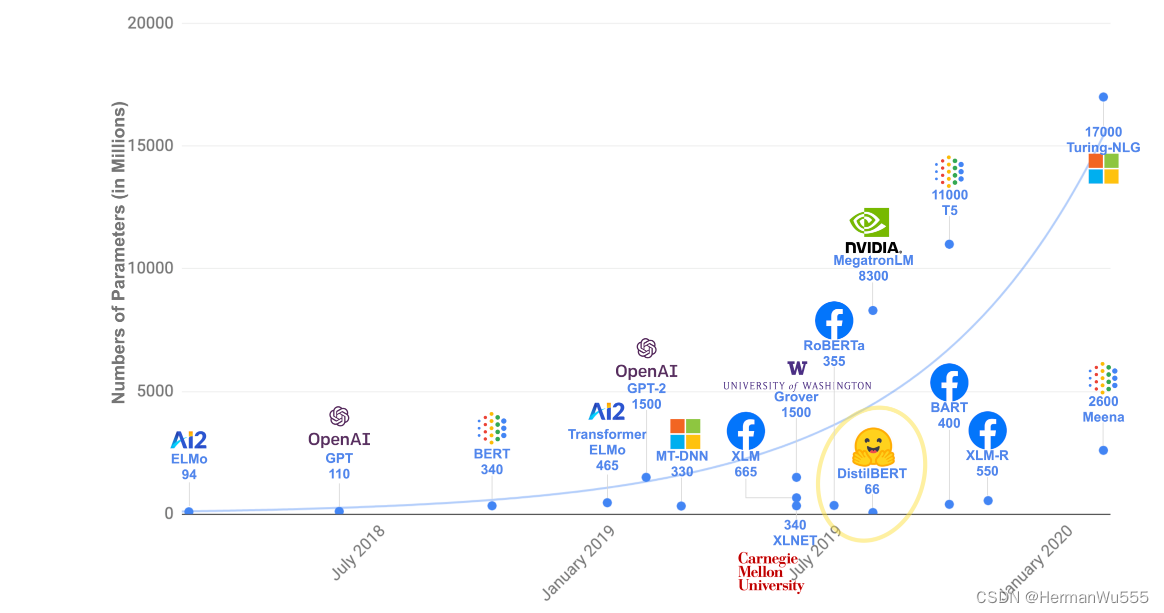
除了 DistilBERT 等少数模型,大部分 Transformer 模型都为了取得更好的性能而不断地增加模型大小(参数量)和增加预训练数据。下图展示了近年来模型大小的变化趋势
3.2 “迁移学习” 思路 流行延申
对于目前的大模型来说,已经是 海量数据 和 极大的模型,训练一次模型,对成本的开支极大
[GPT-3 模型完整训练一次耗费 1200万人民币,使用 285,000个CPU ; 约10,000个GPU, 31个员工]
训练一次基本无法回头, 出错成本极大
[GPT-3 模型训练中出现了一个Bug,由于数据集是上网 拔取下来的 导致 训练集都可能看到 任何的测试数据集,但是由于 训练的成本太大, OpenAI 选择 放弃治疗,不重新训练 并在论文中阐述该bug的解决方法] 来自论文 Language Models are Few-Shot Learners
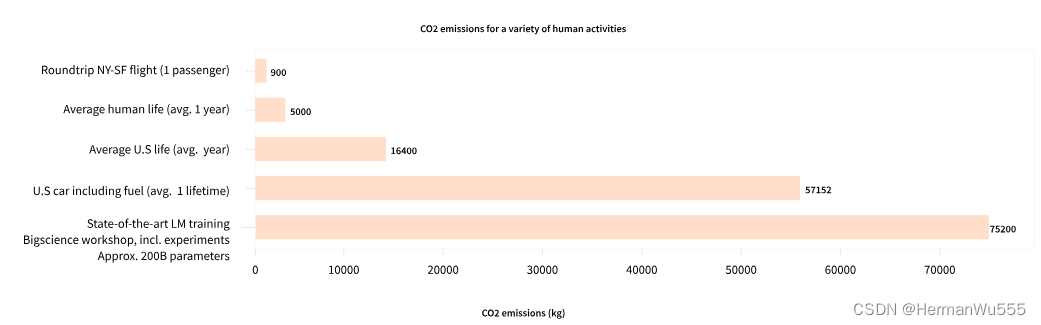
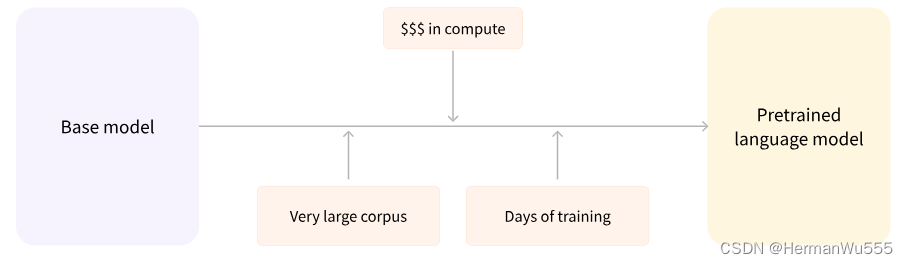
一个不错的 共享的 预训练模型变得尤为重要, 只要有一个 预训练好的模型,从预训练好的模型中进行继续的训练,便可大幅度降低计算成本 和 碳排放 ,所以 迁移学习 思想便变得 极为重要
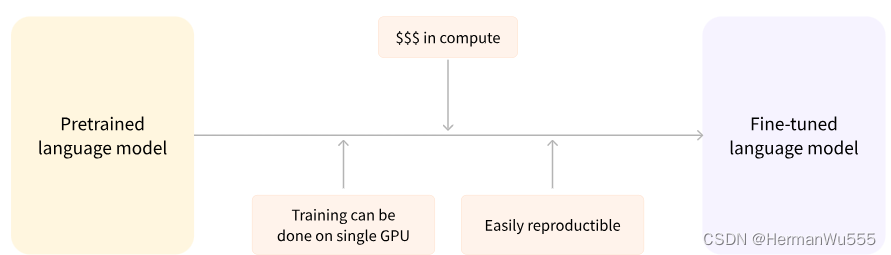
这种迁移学习的好处是:
-
预训练时模型很可能已经见过与我们任务类似的数据集,通过微调可以激发出模型在预训练过程中获得的知识,将基于海量数据获得的统计理解能力应用于我们的任务;
-
由于模型已经在大量数据上进行过预训练,微调时只需要很少的数据量就可以达到不错的性能;
-
换句话说,在自己任务上获得优秀性能所需的时间和计算成本都可以很小。
3.3 CV领域数据量少, 价格昂贵
在 CLIP 文章发表前, 用于训练 CV模型的 通用数据集: ImageNet & MS-COCO等数据, 且由于CV业务场景的缘故,选择的方法一般为 人工标注 & 其他高置信度的标注 的方法,这导致 标注数据 成本过于昂贵 & 高质量的数据标注太少。
然而在 NLP 任务中, 由于 自监督思想 的方法 [BERT --> mask Learning & Next Sentence Prediction],及互联网 & 图书百科知识等缘故,相对 CV 他具备着海量的数据集,让模型去训练。
| 领域 | 数据库名称 | 数据量 | 介绍 |
| CV | Visual Genome | 10 万 | 由 斯坦福大学等研究机构共同研究设立, 是一个大规模的视觉理解数据集,旨在推动计算机视觉和自然语言处理的研究。 该数据被于论文 《Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations》 中收录,并于2016年发表 |
| MS-COCO | 12 万 | (Microsoft Common Objects in Context)由微软提供的大规模图像数据集,用于图像理解和计算机视觉研究。该数据集包含了超过 120,000 张标记过的图像,涵盖了超过 80 种不同的物体类别。 | |
| YFCC100M | 1亿(全量) 1500万 (过滤后) | (Yahoo Flickr Creative Commons 100 Million)是一个由雅虎研究院发布的大规模多媒体数据集,其中包括了一亿个来自Flickr图像分享网站的图像和视频, 但是数据质量标注较差, | |
| ImageNet | 1000 万 + | (Image Database Network)是一个大规模的图像数据库,是计算机视觉领域的重要基准数据集之一。 | |
| NLP | BookCorpus | 8亿 [token] | 包含了来自图书的大量文本数据, 该数据被用于训练 BERT / GPT-1 |
| English Wiki | 25亿 [token] | 包含了大量来自于 英文维基百科中的文章, 该数据被用于训练 BERT / GPT-3 | |
| WebText | 45亿 [token] | Reddit上包含的所有的高赞文章, 该数据被用于训练 GPT-2 | |
| WebText2 | 190亿 [tokens] | WebText数据集 的扩展版本, 该数据被用于训练 GPT-3 | |
| Common Crawl | 4100亿 [tokens] | 开放获取的互联网抓取数据集,旨在提供对大规模网络数据的访问。它由来自全球各地的网络爬虫所收集,包括了数百亿个网页。该数据被用于训练 GPT-3 | |
| Books1 Books2 | Books1: 120亿 [token] Books2: 550亿 [token] | 包含大量书籍文本的数据集,其中包括了各种主题和领域的书籍内容。该数据被用于训练 GPT-3 |
表格可以看出,相对NLP的海量数据而言, 高质量&合适的CV数据数量少之又少
这些都限制了 CV 的方向发展, 很多 SOTA 模型甚至之前的论文 都有着非常不错的想法,但是受限于数据量,其 性能天花板 远远没有达到,甚至也是这个原因导致模型无法加深。
因此CLIP的作者们, 抑或是 OpenAI团队, 秉承着 大数据 大模型 的思想,发现了目前多模态领域的这个洼地,以及 公司兄弟团队的经验 [GPT的思想,当时的历史时期,同公司兄弟团队的GPT已经迭代到 3代;且 谷歌的 BERT 在 NLP领域大放异彩]。 OpenAI 于是在多模态领域开始了他们的工作。于是便有了 CLIP 这篇伟大的 作品


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









