






人脸关键点检测是一个非常核心的算法业务,其在许多场景中都有应用。比如我们常用的换脸、换妆、人脸识别等2C APP中的功能,都需要先进行人脸关键点的检测,然后再进行其他的算法业务处理;在一些2B的业务场景中,如疲劳驾驶中对人脸姿态的估计,也可以先进行人脸关键点的检测,然后再通过2D->3D的估计,最后算出人脸相对相机的姿态角。
本文介绍的这个人脸检测算法PFLD,全文名称为《PFLD: A Practical Facial Landmark Detector》,文章链接可参考PFLD。作者分别来自天津大学、武汉大学、腾讯AI实验室、美国天普大学。该算法对嵌入式设备非常优化,在骁龙845的芯片中效率可达140fps;另外模型大小较小,仅2.1MB;此外在许多关键点检测的benchmark中也取得了相当好的结果。综上,该算法在实际的应用场景中(如低算力的端上设备)有很大的应用空间。目前该工作的源码还没有开源,公布了一个android 的测试app,感兴趣的朋友可以下载试试,PFLD Android APP。更多的实验结果,大家如果感兴趣可以参看文章里面的数据表。
下面我们就PFLD工作中的一些点,跟大家讨论一下。
- 简单的关键点检测器实现
首先我们来先看看如果只是为了实现一个简单的人脸检测器,我们会怎么去设计?本专栏之前的一篇文章曾经给大家介绍过---如何DIY轻型的Mobilenet回归器。人脸关键点检测任务本质上是一个回归器,我们可以将这个模型实现分为两步:1. 选择合适的特征提取骨干(feature extraction backbone);2. 选择合适的回归方式。在这里,我们骨干网络选择Mobilenet-V1,回归方式我们直接回归2xN个点,N为关键点的个数。网络结构如下图所示:
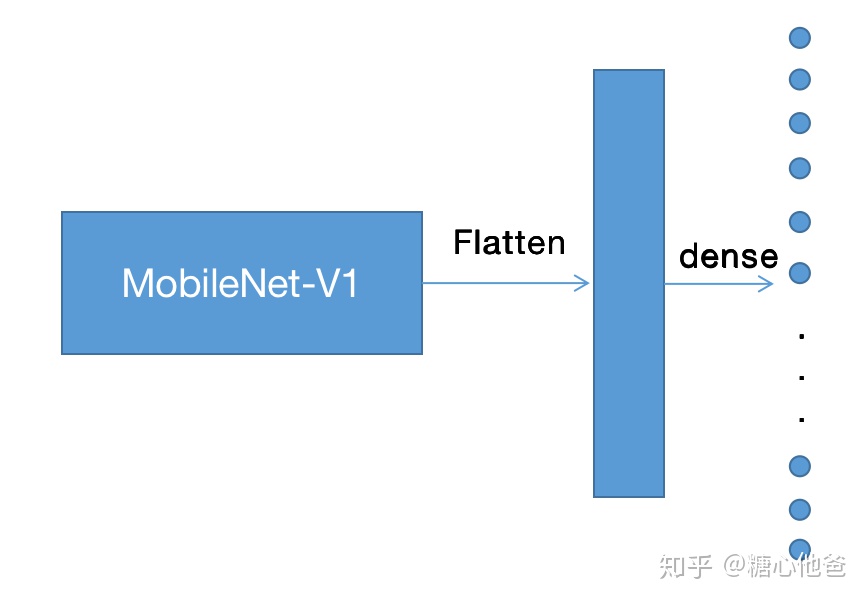
在训练的时候,我们只要给定足够的训练数据进行训练即可。
- 存在的问题及思考
我们在上述的人脸检测器模型中,想取得较好的结果,需要用足够的数据进行训练,此外还要加入一些tricks。但在实际的应用的时候,对于一些极端情况,如遮挡(手部、眼镜)、光照(强光、弱光)、极端姿态(yaw、pitch、raw较大的时候)、极端面部表情等。
为了解决上述的问题,从工程上角度的考虑,我们可以通过采用特征描述能力更强的backbone(如VGG16、ResNet等),或者增加极端情况下的训练数据、平衡各类情况下的训练数据的比例、控制数据数据的采样形式(非完全随机采样);针对上述的情况,PFLD从算法设计的角度,提出了自己的解决方案。
- PFLD模型设计
在模型设计上,PFLD的模型设计上骨干网络没有采用VGG16、ResNet等大模型,但是为了增加模型的表达能力,对Mobilenet的输出特征进行了结构上的修改。如下图:

PFLD通过融合三个不同尺度的特征,来增加模型的表达能力。该网络结构骨干部分采用的是Mobilenet-v2,在嵌入式设备中仍能取得很好的性能。
- PFLD的模型训练策略
一开始我们设计的那个简单的网络,采用的损失函数为MSE,所以为了平衡各种情况的训练数据,我们只能通过增加极端情况下的训练数据、平衡各类情况下的训练数据的比例、控制数据数据的采样形式(非完全随机采样)等方式进行性能调优。
- 损失函数设计
PFLD采用了一种很优雅的方式来处理上述各情况样本不均衡的问题,我们先看看其损失函数的设计:
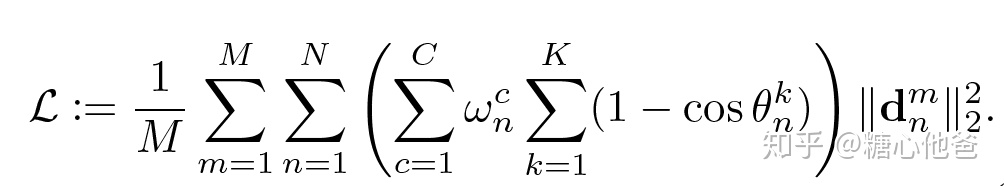
上式中 wn为可调控的权值函数(针对不同的情况选取不同的权值,如正常情况、遮挡情况、暗光情况等等),theta为人脸姿态的三维欧拉角(K=3),d为回归的landmark和groundtrue的度量(一般情况下为MSE,也可以选L1度量)。该损失函数设计的目的是,对于样本量比较大的数据(如正脸,即欧拉角都相对较小的情况),给予一个小的权值,在进行梯度的反向传播的时候,对模型训练的贡献小一些;对于样本量比较少的数据(侧脸、低头、抬头、表情极端),给予一个较大的权值,从而使在进行梯度的反向传播的时候,对模型训练的贡献大一些。该模型的损失函数的设计,非常巧妙的解决了平衡各类情况训练样本不均衡的问题。
2. 配合训练的子网络
PFLD的训练过程中引入了一个子网络,用以监督PFLD网络模型的训练。该子网络仅在训练的阶段起作用,在inference的时候不参与;该子网络的用处,是对于每一个输入的人脸样本,对该样本进行三维欧拉角的估计,其groundtruth由训练数据中的关键点信息进行估计,虽然估计的不够精确,但是作为区分数据分布的依据已经足够了,毕竟还该网络的目的是监督和辅助训练收敛,主要是为了服务关键点检测网络。有一个地方挺有意思的是,该子网络的输入不是训练数据,而是PFLD主网络的中间输出,大家可看下图:
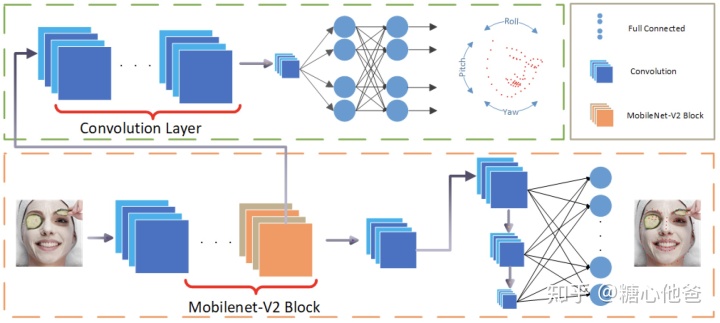
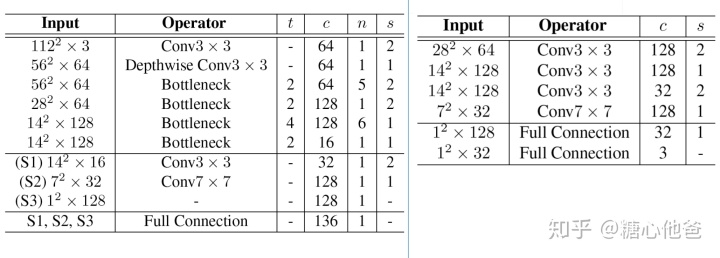
主网络和姿态估计子网络的详细配置如下表:
- 最后
感谢PFLD的作者,为我们提供了许多工程上的调优思路。后续笔者也会开源一个版本的PFLD实现,用以跟大家交流。另外欢迎大家留言讨论、关注专栏,谢谢大家!
实战嵌入端的AI算法zhuanlan.zhihu.com
- 参考
- PFLD: A Practical Facial Landmark Detector
2. 如何DIY轻型的Mobilenet回归器
















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









