







BlazePose: On-device Real-time Body Pose tracking解析
论文连接:https://arxiv.org/pdf/2006.10204.pdf
论文代码:https://google.github.io/mediapipe/solutions/pose.html
论文出处:2020CVPR Workshop
研发团队:google research
1. 概述
-
BlazePose是一个轻量化的,可用于移动设备上的人体姿态估计网络。
-
网络提供人体的33个body keypoints,在Pixel2手机上速度超过30fps。
-
本文贡献主要2点:(1)新型的人体姿态跟踪方案;(2)轻量化人体姿态估计网络。
-
body pose estimation分为:heatmap-based方法和regression-based方法。
heatmap-based方法是先生成热图,再根据热图算出关键点;
regression-based方法是直接回归(decode)出关键点。 -
本文的idea是:使用一个encoder-decoder网络结构预测所有关节点的热图,然后再用另外一个encoder直接回归出所有关节点的坐标。
其中,热图分支只用于训练,不出现在inference中。
2. 模型构架和pipeline设计
2.1 推理流程(Inference pipeline)
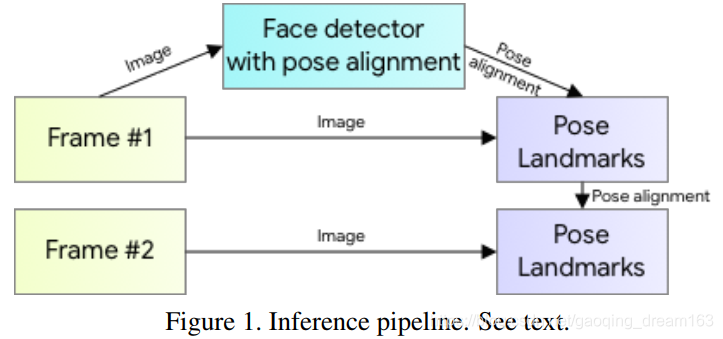
- 推理过程使用一个detector-tracker的设置,如上图所示。
- pipeline包括一个轻量化的body pose detector,跟一个pose tracker network。
- 跟踪器tracker用于预测关键点坐标、当前帧是否有人、当前帧感兴趣区域的微调。
- 当tracker预测到当前帧没有人时,在下一帧重新运行detector。
2.2 Person detector
- 大部分目标检测器在后处理部分都依赖于Non-Maximum Suppression (NMS)算法。该算法对于具有少自由度刚体来说效果很好,但对于多自由度(人体,人手)姿态效果不好。因为多个boxes满足满足NMS算法的IoU阈值。
- 因此,本文采用相对刚性的人脸(face)的检测(用Blazeface网络)来代替人体的检测,作为person detector。
- 该face detector除了检测人脸,还预测额外的人体特定参数:臀部中点、环绕整个人的原的大小、倾斜度(连接两个肩中点和臀中点的线之间的角度)。如下图:

2.3 拓扑结构(Topology)
33个关键点。只在脸部、手和脚上使用最少数量的关键点来估计后续模型感兴趣区域的旋转、大小和位置。
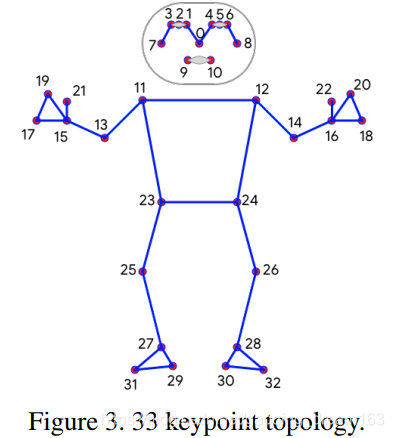
2.4 数据集
为了确保模型支持数据集中不存在的严重遮挡,作者使用了大量的遮挡模拟增强。
数据集的训练数据集包含60K幅图像,场景中有一个人或少数人以常见的姿势,以及25K幅图像,场景中有一个人进行健身锻炼。
2.5 网络结构
使用上面提到的人体检测器中的人体对齐方案,之后进行姿态检测,姿态检测网络如下:
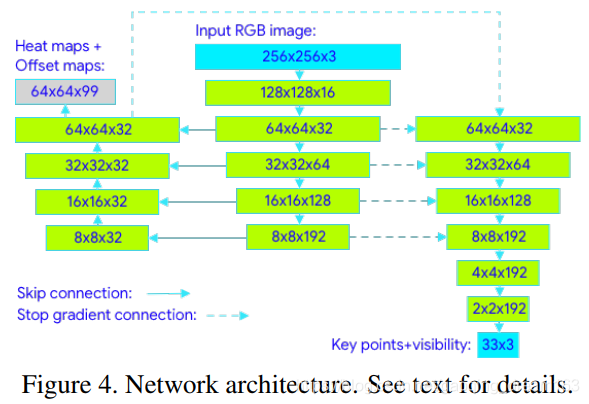
采用heatmap、offset和坐标回归方法,如图4,heatmap和offset只用于训练,在推理时会删除对应的输出层。
因此,我们有效地利用热图来监督轻量级的嵌入,然后回归编码器网络利用轻量级的嵌入。
我们积极利用网络所有阶段之间的skip-connections,以达到高层次和低层次特征之间的平衡。
然而,从回归编码器的梯度不会传播回热图训练的特征。我们发现这不仅改善了热图预测,而且大大提高了坐标回归精度。
2.6 对齐和遮挡增强
姿态的先验是解决方案的重要部分,增强训练时的数据准备期间,作者选择故意限制角度(angle)、尺度(scale)和平移(translation)的支持范围。
基于检测或前一帧关键点,作者对人进行对其,使臀部中间的点作为神经网络输入的正方形图像的中心。
姿态的旋转(angle):为臀部中间与肩部中间的点的直线L,并旋转图像,使得L与y轴平行。
尺度进行估计(scale):使所有身体点都在一个包围身体的方形边界框中。如图2。此外,应用了10%的缩放和移位增强,以确保跟踪器处理帧之间的身体扭动和扭曲的对齐。
对不可见点的预测:我们在训练过程中模拟遮挡(用各种颜色填充的随机矩形),并引入逐点可见性分类器,以表明某个特定点是否被遮挡,以及位置预测是否被认为不准确。这可以实现持续跟踪一个人,即使是在严重遮挡的情况下,如仅上半身或当大部分人的身体不在场景中,如图5所示。

3. 实验
测试集为手动标注的两个1000张图片。每张图片有一到几个人。第一个数据集,成为AR数据集,有大量野外的人体姿态。第二个数据集,只包含瑜伽和健身的姿态(Yoga Dataset)。
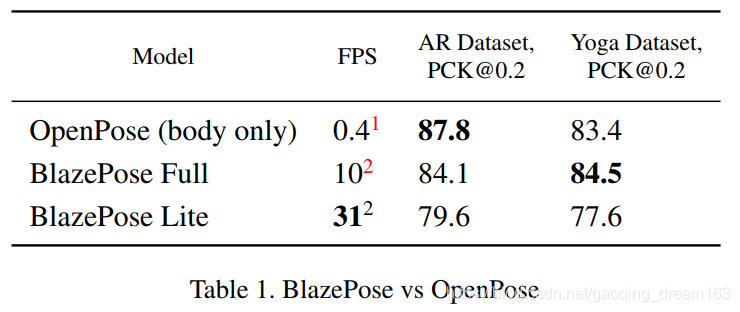
对比对象为openPose,为了保持一致性,只使用COCO的拓扑结构,用17个点进行评估。这是blazePose和openPose的一个公共子集。评价标准为PCK@0.2(如果2D欧几里得误差小于相应人躯干尺寸的20%,我们就会假设这个点能被正确检测到)。
本文训练了两个不同容量的模型,BlazePose Full(6.9MFlop,3.5M Params)和BlazePose Lite(2.7MFlop,1.3M Params)。在AR数据集上,blazePose稍微不如OpenPose。但blazePose Full在瑜伽和健身数据集上比OpenPose好。但需要注意的是,与在20核的桌面CPU的OpenPose相比,BlazePose在单个中级的手机cpu上比OpenPose要快25到75倍。
效果展示:


















 3656
3656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









