







本文是一份总结帖,主要目的是教未来的师弟们,如何成为帮老师装服务器系统的工具人,不出意外的话,我们组应该是不会有师妹的
首先,先说明一点,Ubuntu和nvidia驱动,每次版本变化,安装方式都略有不同,我以前的方法仅供参考,具体的操作中一定要看英文提示!!!
在开始安装 之前,请了解一下cuda driver、cuda toolkit、cudnn三者的关系,可以参考我之前的帖子
具体下载的下载地址这里也有
还需要了解一下vim编辑器怎么用、shell指令怎么用
可以参考Linux vi/vim 和Linux 命令大全
尤其需要掌握vim如何进入输入模式,如何保存退出!
了解之后就可以动手开装了
关于Ubuntu系统的U盘制作和安装部分,我参考的是Ubuntu18.04安装教程
教程基本没啥问题,不过我装Ubuntu20.04的时候,已经有一些步骤不一样的,不过总体的操作都是相同的
值得注意的是,我师兄说,硬盘小的时候不需要分盘,可以跳过分盘步骤让系统自动分盘。
系统安装好后,需要打开系统的22号口,方便以后ssh连接
具体操作使在命令行中依次输入
sudo apt-get install openssh-server
sudo apt-get install ufw
sudo ufw enable
sudo ufw allow 22如果有gcc、ifconfig、pip3之类的指令没有安装的话,在用的时候,根据提示安装即可。
下面我们开始安装nvidia driver,下载地址 NVIDIA Driver Downloads
对于比较老的主板,比如4楼的x99主板,需要在bios中关闭secure boot 可参考华硕主板怎么关闭Secure Boot
驱动的安装过程可以参考环境搭建01——Ubuntu如何查看显卡信息及安装NVDIA显卡驱动 (重点是这篇文章 3.安装显卡驱动和后面的内容)和重装显卡驱动,解决NVIDIA-SMI has failed问题
一定要注意英文提示,不能像win系统下一样,盲目的下一步
还有一种方法是使用ubuntu自己检索到的驱动
点击附加驱动

这里就能看到没有适合你显卡的驱动

如果没有,还是按照上一个方法手动装吧
然后我们要安装cuda toolkit,cuda toolkit可以和nvidia driver版本不同,建议使用目前pytorch支持的、最新的cuda
下载地址:CUDA Toolkit Archive
可以参考Ubuntu16.04 ppa显卡驱动安装,cuda9.1,cudnn7.1安装(我们不需要使用ppa)
具体的重点是 (4.安装CUDA9.1)
也可以看看Ubuntu安装多版本cuda,并在多版本之间切换
注意,装cuda11.1的时候,我发现有些步骤已经不太相同了,比如安装cuda11.1的时候,对于选装的部分没有y/n选择,
取而代之的是通过上下和回车确定要不要装,这里Driver一定不要选,因为之前已经装过driver了,sample也可以不选

有点像win下装软件时候的多选框,所以具体还是要看英文提示
再强调一点
如果你装完,发现nvcc依然不能用,并且提示你
sudo apt-get install nvidia-cuda-toolkit 来使用nvcc的时候,千万不要用这个指令,系统认为你没有安装cuda,实际上你已经装了
正确操作: 进入:
cd /usr/local/cuda查看cuda的bin目录下面有没有nvcc,有的话就将它加入路径
通过
vim ~/.bashrc进去后,在最后添加
export PATH=/usr/local/cuda-10.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH然后
source ~/.bashrc如果你小子手快。。。已经装了。。。用
sudo apt-get --purge remove nvidia-cuda-toolkit给他删了
cuda之后,自然是cuDNN,注意下载cuDNN,需要注册一个账号才能下载
下载地址:cudnn-download
下载的cuDNN必须和cuda toolkit匹配
下载cuDNN后先解压
tar -xzvf cudnn-9.1-linux-x64-v7.tgz注意-xzvf后的文件名需要换成你下载的cudnn
然后执行以下操作
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*按理说,在这之后,就可以通过
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2查看cudnn的版本,但是。。。我就从来都没有成功过,不论是1080ti的那台、还是2080ti+3090的那台、或者是3090*4的那台
都没能正常的查看到cudnn的版本,不过看不到版本并不影响我们进行后续的gpu加速
注:该问题已解决
原因是新版本cudnn的版本信息包含在cudnn_version.h而不是cudnn.h
所以
除了复制cudnn.h
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/应该增加
sudo cp cuda/include/cudnn_version.h /usr/local/cuda/include/对应的
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2改为
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2有些代码里在这之后还有deb包的安装过程
比如
sudo dpkg -i libcudnn8_8.0.5.39-1+cuda11.0_amd64.deb
sudo dpkg -i libcudnn8-dev_8.0.5.39-1+cuda11.0_amd64.deb
sudo dpkg -i libcudnn8-samples_8.0.5.39-1+cuda11.0_amd64.deb
这是cudnn安装的另一种方法,没必要两种方法都来一遍
有时候会报出类似
/sbin/ldconfig.real: /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn.so.8 is not a symbolic link这样的错误,我们进入相应目录,通过
sudo ldconfig -v检查一下连接,发现
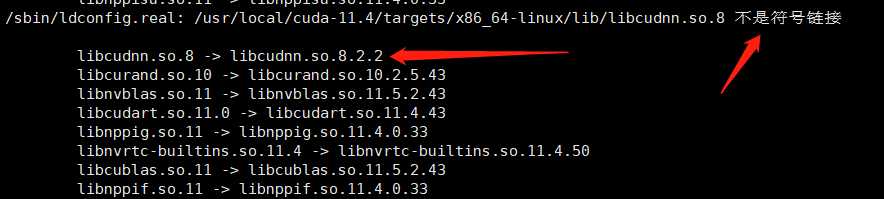
虽然他也有了只指向,但是貌似不太正常
为此,我们需要手动建立连接
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
sudo ln -sf /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.2 /usr/local/cuda-11.4/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
再检查一下连接

一切都正常了
注意你报错的位置和版本,不要盲目的复制
其实这是cuda toolkit安装时候,生成的包,不是我们复制到lib64的包,也许,即使我们不手动复制cudnn,cuda依然可以运行(仅仅是猜测)
最后是安装torch
根据需要选择需要的torch,用他提供的指令即可(pip要改成pip3)

虽然我们cuda是11.1的,但是装这个11.0的torch也能用
如果需要安装anaconda请参考
具体的操作大概就这些,有问题以后再补充吧。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









