





今天给大家介绍的是一项由硅谷Salesforce Research的Ali Madani等人和斯坦福的Possu Huang教授课题组合作的工作,他们在这篇论文中提出的一种蛋白生成语言模型ProGen。作者将蛋白质工程视为无监督序列生成问题,利用大约2.8亿个的蛋白质序列对12亿个参数进行训练,且要求这些蛋白质序列是基于分类和关键字标签的,如分子功能和细胞成分,这为ProGen模型提供了前所未有的进化序列多样性,并允许它进行基于一级序列相似性、二级结构准确率和构像能量的细粒度控制生成。根据NLP指标,ProGen模型表现出良好的性能,且随着氨基酸上下文和条件标签的增多,模型效果会进一步提升。ProGen也适用于未见的蛋白家族,若进行微调,模型效果更好。
1.介绍
产生具备所需属性的蛋白质是生物学领域最复杂但最具影响力的工作之一,在过去50年间,蛋白质工程研究不断发展,并取得了一系列举世瞩目的成就。但是,领先的蛋白质工程实验技术仍然依赖于启发式和随机突变来选择进化的最初序列。
在氨基酸编码蛋白质的过程中,氨基酸链折叠成局部(二级)和全局(三级)结构,这些结构将直接影响蛋白质功能。然而,直接获取蛋白质三维结构信息成本很高且非常耗时,因此,一级序列信息比带有结构注释的序列多得多,并且蛋白质序列呈指数增长。
最近的研究开始利用更大规模的原始蛋白质序列数据集,采用最先进的表示学习技术,将自然语言处理(NLP)方法应用到蛋白质属性分类。然而,还并未有人尝试采用最先进的人工文本生成方法,特别是对蛋白质工程最有用的可控的生成方法。
为此,作者介绍了一种可控的蛋白质生成模型ProGen。ProGen模型是一个含有12亿个参数的语言模型,该模型在包含2.8亿个蛋白质序列的数据集和编码不同注释的条件标签上训练而成,这些标签包含分类、功能和位置信息。通过调节这些标签,ProGen提供了一种可根据所需属性生成特定蛋白质的方法,如下图所示。
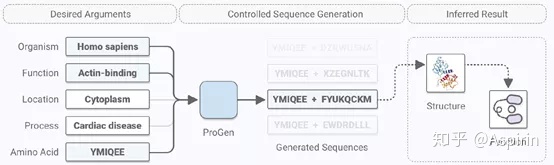
通过序列相似性、二级结构准确度和构象能量等指标评估时,ProGen模型生成的蛋白质满足所需的结构和扩展功能。更高水平的指标评价的模型质量更好,这表明ProGen模型已经在序列水平上学会识别了保持结构和功能的关键位点和序列。在最高水平上,构象能量分析表明生成的蛋白质的能量接近于天然蛋白质,这证明这些蛋白质满足所期望的结构和推测的功能。
2.模型
作者将可控的属性称为条件标签,通过这些条件标签可以控制氨基酸序列的生成。利用概率链式法则可以得到组合序列的概率分布p(x):
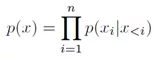
其中,序列是在氨基酸序列前加上条件标签序列
而形成的序列。如此一来,条件蛋白生成问题则转化成了下一个元素预测问题,这个元素既可以是氨基酸,又可以是标签。然后,可以训练带有参数的神经网络来最小化数据集上的负对数似然值:
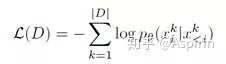
依据这一公式,给定所需属性的蛋白质的标签序列,可以得到此蛋白的氨基酸序列。同时需要注意,
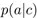
,即相应标签条件下的蛋白质序列分布仅是学习的模型可以恢复的许多条件分布的一个。
作者训练了一个Transformer的变体来学习氨基酸和条件标签的条件分布。在向量空间中,包含n个元素(token)的序列嵌入在n个对应的向量中,每个向量都是学习的元素嵌入和正弦位置嵌入的总和,这些向量序列被堆叠成矩阵

,以便它可被attention层处理。
第i层由两个块顺序组成,每个块保留模型维度d,第一块的核心是k多头attention:
第二块的核心是具有ReLU激活的前馈网络,其中
且:在每个块的核心功能之前先进行层规范化(LayerNormalization),并进行残差连接,最后产生:
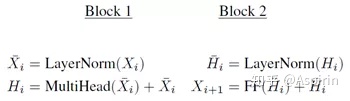
从最后一层的输出计算得分:
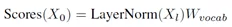
在训练过程中,此得分是交互熵损失函数的输入。在生成过程中,得分用softmax标准化,生成一个新元素的采样分布。
3.实验
3.1数据
作者使用了Uniparc、UniprotKB、SWISS-PROT、TrEMBL和Pfam上所有可用的蛋白序列和相关标签以及NCBI的注释信息,所有的数据超过了2.81亿个蛋白质,其中2.8亿条数据作为训练集,10万条数据作为蛋白质家族测试集(OOD-test),100万条数据作为随机采用测试集(ID-test)。条件标签分为关键词标签和注释标签两个类别。
3.2训练
训练过程使用了每个序列及其反向序列,并且在每个序列前添加标签子集。此外,作者使用了只有氨基酸序列而没有条件标签的样本,使得ProGen可在未知蛋白属性的情况下,仅利用标签序列数据也能生成蛋白质。然后,作者将所有序列截断,最大长度为512,填充长度小于512的序列。
3.3生成
首先,ProGen使用上下文序列作为输入,并输出氨基酸的概率分布。接着从分布中取样,并且使用取样的氨基酸更新上下文序列。重复进行这一过程,直至所需长度的蛋白质生成。
3.4评估
为了评估模型的训练和测试能力,复杂度(perplexity)作为语言模型的衡量指标,硬准确率(hard accuracy)评估每个氨基酸误差,软正确性(softaccuracy)是标准氨基酸替换矩阵。
为了评估生成质量,作者从以下三个层次进行分析:(1)一级序列相似性。一级序列相似性是利用Biopython包计算出的全局成对序列对其得分,其结果根据蛋白质长度进行标准化。(2)二级结构。二级结构准确率是由PSIPRED计算的预测二级结构残基,其置信度大于0.5。(3)构象能量分析。构象能量使用Rosetta-RelaxBB协议。
此外,作者给定了不同随机突变水平的基线。对于一个给定序列,这个序列中25%-100%氨基酸会被20个标准氨基酸或自身替代。对于构象能量,作者提供了一个全丙氨酸基线。这些基线给上述指标提供了一个衡量标准。
4.结果
4.1ProGen语言模型评估
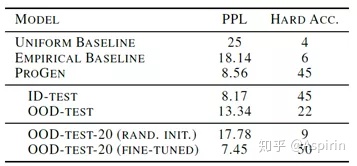
实验结果显示ProGen对于标准基线(UniformBaseline)和经验基线(Empirical Baseline)均有显著提高。下表第2部分分别列出了ID-test和OOD-test两个测试集的结果。ID-test的结果表明ProGen可以很好地随机生成蛋白家族序列,而OOD-test测试集的结果较差,但仍然优于经验基线。进一步将OOD-test集划分为OOD-test-80和OOD-test-20,在OOD-test-80收敛前微调ProGen,并在OOD-test-20上重新测试,下表第3部分展现了相对于随机初始化权重的训练架构而言,微调的ProGen有了改善。
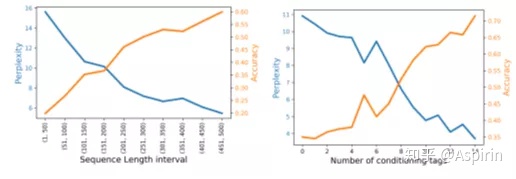
随着氨基酸和上下文条件标签的增加,ProGen性能也会随之提高,如下图所示。无论是增加序列长度还是条件标签数,复杂度都在不断减小而硬准确率都在不断增加。
ProGen的参数数量可与最大规模的语言模型相提并论,但是,下图中的训练曲线表明无论多大的规模和数量,ProGen均不会出现过拟合现象。这说明蛋白质生成将受益于更大规模的模型和更长时间的训练。
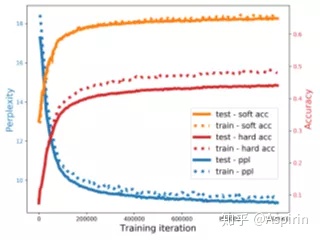
模型基于BLOSUM62软准确率的表现比硬正确率高出20%,这表明ProGen预测误差主要是由天然氨基酸的取代产生的,这些氨基酸可能会保留更高水平的结构。
4.2ProGen生成
在3.4节中已经提到了评估生成质量的3个指标以及一些突变基线,参考这些基线,当从一级序列转移到全部构象结构指标时,ProGen质量有了提高,这表明模型已经学习了结构中的突变不变性。
下图描述了使用top-k采样和重复惩罚的不同组合进行实验的结果,对于所有上下文长度,当k取1且重复惩罚用于最近生成的氨基酸时,模型表现最好。通过这种采样,ProGen成功生成了序列相似的蛋白质,其相似度可与随机突变50%在给定上下文未见的基酸相比较。
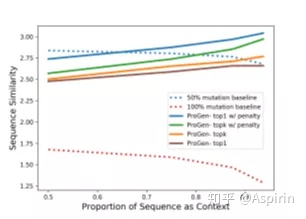
下图显示了标签对序列相似性的影响,至少与3个条件标签相关的序列才开始超过50%的突变基线,并且随着氨基酸上下文的增加,至少有8个条件标签的序列才能接近25%的突变基线。从图中也可看出,即使是最好的情况,ProGen也没有超过25%的突变基线。但是根据二级结构准确率,至少有8个条件标签的序列超过了25%的突变基线。这两者之间的矛盾也证明了观点:根据更直接对应于功能的高级指标,低级指标的误差通常对应于可接受的替换。
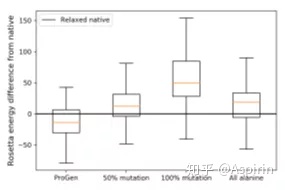
下图显示了天然蛋白质、ProGen样本、50%和100%随机氨基酸突变的天然蛋白质和全丙氨酸基线的能量水平差异,由ProGen生成的蛋白质更接近于天然蛋白质的能量水平,生成样本的能量接近甚至低于相关的天然模板。
5.总结
本文介绍了一种可控的蛋白质生成语言模型ProGen,该模型生成的蛋白质接近自然结构能量,这意味着其具备功能可行性,该模型有潜力与其它先进的方法一样成为一个新的方法。在重头设计蛋白中,利用带有条件标签的ProGen可以设计在新蛋白家族或宿主中的具有折叠形状的新蛋白。
参考资料
https://arxiv.org/abs/2004.03497














 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









