





摘要:
深度学习语言模型在各种生物技术应用中显示出前景,包括蛋白质设计和工程。在这里,我们描述了 ProGen,这是一种语言模型,可以生成具有跨大型蛋白质家族的可预测功能的蛋白质序列,类似于在不同主题上生成语法和语义正确的自然语言句子。 该模型接受了超过 19,000 个家族的 2.8 亿个蛋白质序列的训练,并增加了指定蛋白质特性的控制标签。 ProGen 可以进一步微调到精选的序列和标签,以提高来自具有足够同源样本的家族的蛋白质的可控生成性能。 针对五个不同溶菌酶家族微调的人工蛋白质显示出与天然溶菌酶相似的催化效率,与天然蛋白质的序列同一性低至 31.4%。 ProGen 很容易适应不同的蛋白质家族,正如我们用分支酸变位酶和苹果酸脱氢酶所证明的那样。
结果
我们通过测试 ProGen 在来自溶菌酶家族的五个不同蛋白质家族中的世代 23,39(补充表 2),以实验方式评估了 ProGen 生成功能性人工氨基酸序列的能力。 蛋白质家族包含大量序列多样性(补充表 3),平均序列长度在 84-167 之间变化。 这些序列还显示出巨大的结构多样性和多重结构折叠(补充图 2)。 总的来说,这代表了一个模型的具有挑战性的设计空间,该模型在生成时不受限于已知功能野生类型附近的局部序列邻域,也没有提供结构先验。 我们从 Pfam 和 UniprotKB 来源收集了来自这五个家族的 55,948 个序列的数据集,用于获得阳性对照和微调(32-35)ProGen。
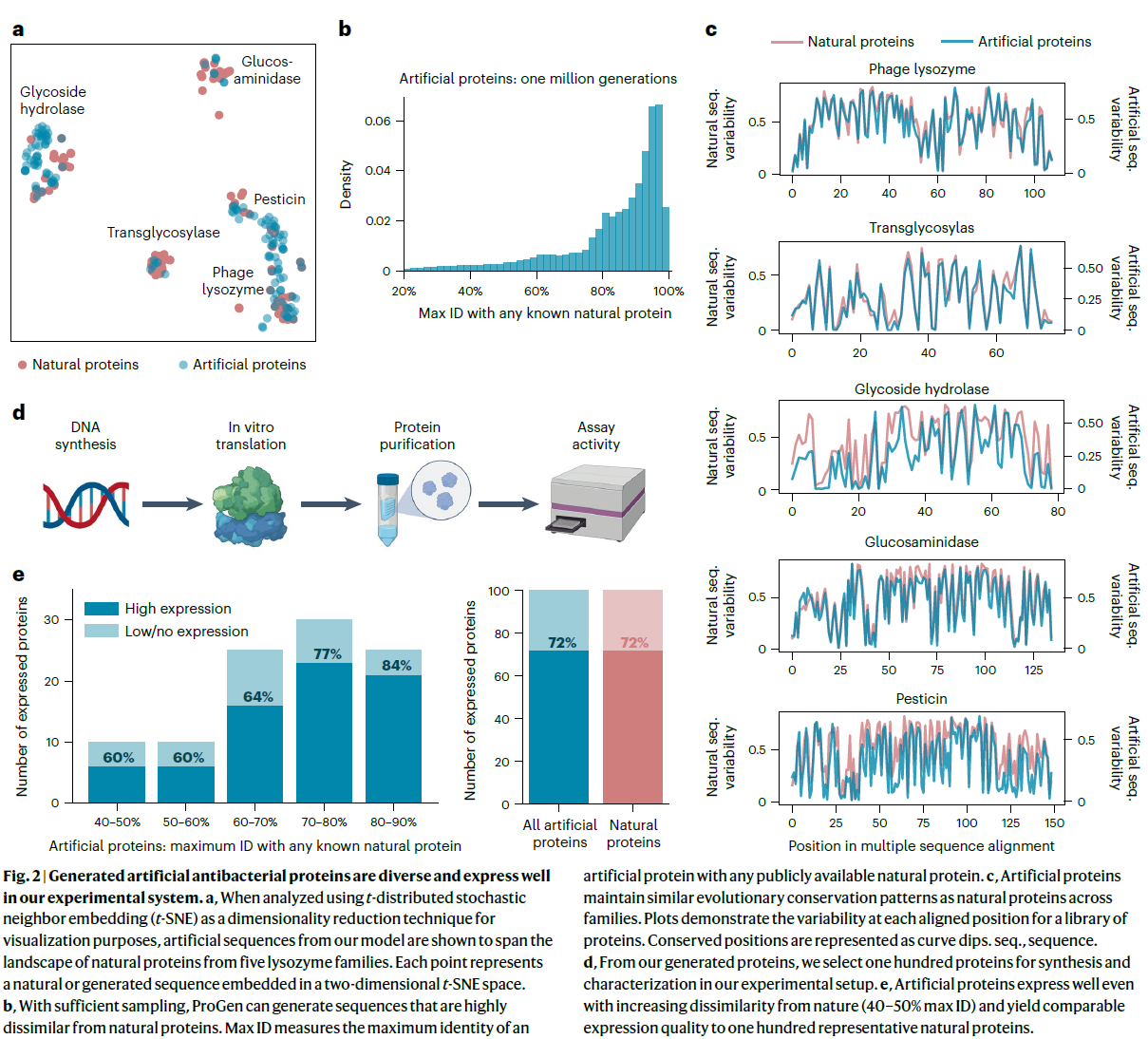
在使用精选的溶菌酶数据集对 ProGen 进行微调后,我们通过为每个家族提供 Pfam ID 作为对照标签,使用 ProGen 生成了一百万个人工序列。 我们的人工溶菌酶跨越天然溶菌酶(图 2a)的序列景观,跨越五个家族,包含不同的蛋白质折叠、活性位点结构和酶促机制 (40,41)。 由于我们的模型可以在几毫秒内生成全长人工序列,因此可以创建一个大型数据库来扩展自然库之外的合理序列多样性(补充表 3)。 尽管人工序列可能纯粹从序列同一性计算而与天然序列不同(图 2b 和补充图 3),但当在每个家族中形成天然和人工蛋白质的单独多重序列比对时,它们表现出相似的残基位置熵(图 2c) ). 这表明该模型已经捕获了进化保护模式,而无需像 Potts 模型 (42) 那样在直接耦合分析 (7,43–46) 中实施显式比对信息训练。
为了通过实验评估 ProGen 在天然蛋白质的一系列序列差异中的性能,我们选择了 100 个序列,这些序列根据生成质量和天然序列的多样性进行过滤,作为我们研究中任何蛋白质的最高命中率(“最大 ID”)来衡量 训练数据集包含 2.8 亿个蛋白质,主要由 UniParc21 组成(补充图 4)。 我们选择的蛋白质包括 100 个人工序列(补充表 2),每个蛋白质家族至少有 8 种蛋白质。 人工蛋白质的平均序列长度在 93-179 之间变化,与我们从 Pfam 精选的数据集中的天然溶菌酶相当。 人工蛋白质包括特定氨基酸和成对相互作用,这些相互作用以前从未在溶菌酶家族特异性比对中的比对位置观察到(补充表 4 和 5)。 我们还从 55,948 个精选的溶菌酶序列中选择了一个阳性对照组。 我们使用 MMseqs247 对自然序列进行聚类,并从五个家族中的每一个家族中选择了大约 20 个具有聚类代表性的序列。
为了评估功能,通过无细胞蛋白质合成和亲和层析合成和纯化全长基因。 在 100 种天然蛋白质的阳性对照集中,72% 的表达良好,如色谱峰和条带可视化所测量。 ProGen 生成的蛋白质在所有序列同一性箱中与任何已知的天然蛋白质(最大 ID 40-90%;图 2e)的表达同样好(总共 72/100)。 此外,我们使用 bmDCA7 设计了人工蛋白质,bmDCA7 是一种基于直接耦合分析的统计模型,它明确地近似于一阶和二阶残基依赖性。 从他们的公开可用代码开始,我们尝试使 bmDCA 模型收敛于与 ProGen 相同的序列,并使用额外的比对信息并搜索了广泛的超参数。 bmDCA 无法适应五个溶菌酶家族中的三个,并且对其余两个蛋白质家族表现出 60% 的可检测表达(30/50 蛋白质)。 这些结果表明,与一批天然蛋白质相比,ProGen 可以生成结构良好折叠的人工蛋白质,即使在序列比对大小和质量限制替代方法成功的情况下也能正确表达。
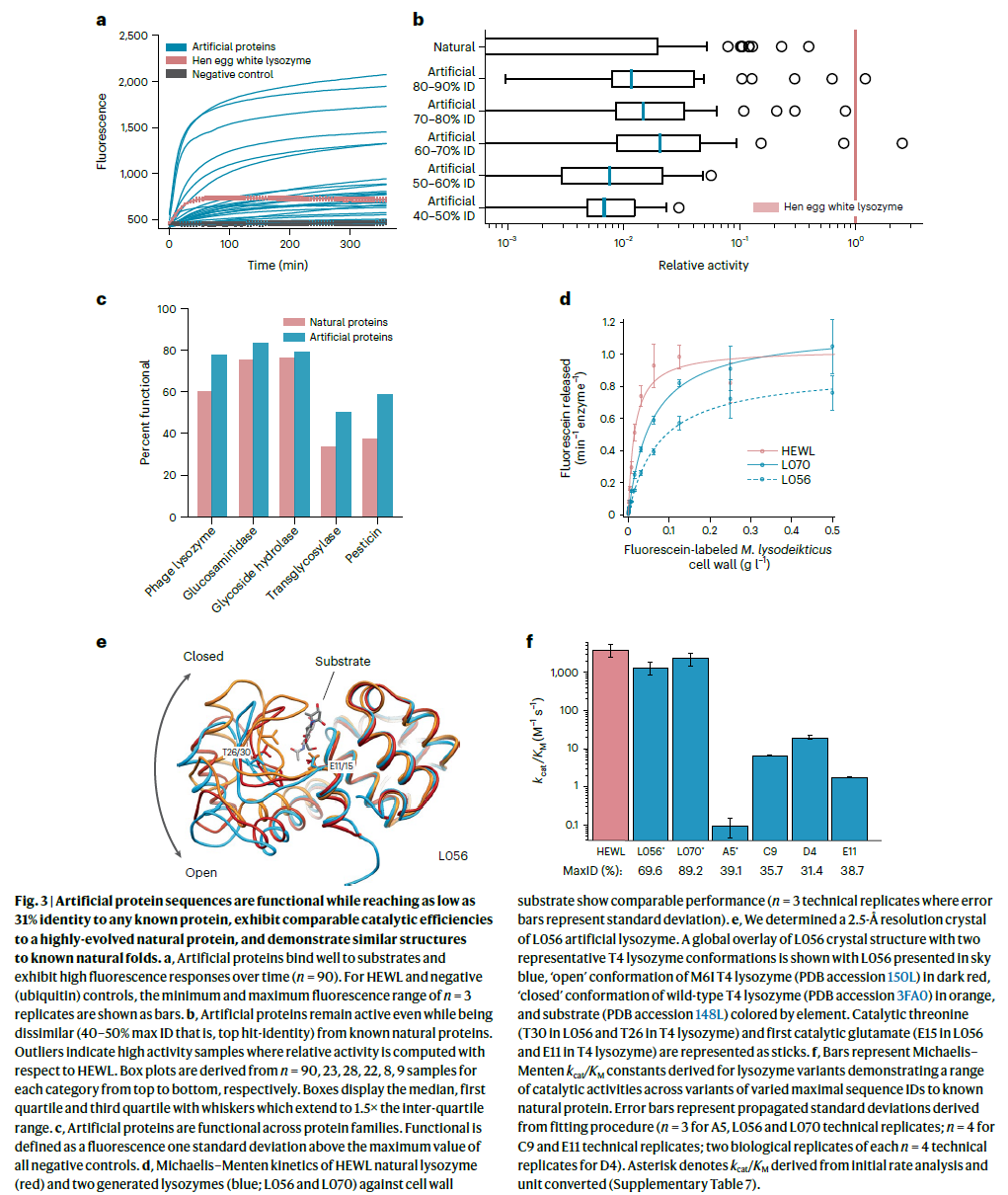
接下来,我们在荧光素标记的溶菌微球菌细胞壁(Molecular Probes EnzChek 溶菌酶试剂盒)的猝灭释放的基础上检查了活性,使用从每组表达的 100 种蛋白质中随机选择的 90 种蛋白质。以 96 孔板形式制备蛋白质以提取 随时间变化的荧光曲线(图 3a)。 鸡蛋清溶菌酶 (HEWL) 是一种自然进化的样本蛋白,除了泛素作为阴性对照外,还被测量为阳性对照。 产生比任何阴性对照的最大荧光高一个标准偏差的荧光的蛋白质被认为是有功能的。 在我们的人造蛋白质中,有 73% (66/90) 具有功能并且在家族中表现出高水平的功能(图 3c)。 代表性的天然蛋白质表现出相似的功能水平,59% (53/90) 的总蛋白质被认为是功能性的。 没有一种 bmDCA 人工蛋白质表现出可检测水平的功能(补充图 5),这可能是由于收敛、采样或其他特定模型运行问题,进一步突出了 ProGen 的多功能性,提供了一个潜在的更强大的替代方案。 这些结果表明,ProGen 生成的蛋白质序列不仅可以很好地表达,而且可以维持跨蛋白质家族的不同序列景观的酶功能。
除了功能的二元值外,我们还计算了体外测定的 HEWL 的相对活性评分。 我们的人工蛋白质与天然蛋白质的活性水平相匹配,即使在与任何已知天然蛋白质的序列同一性水平较低的情况下也是如此(图 3b 和补充图 6)。 值得注意的是,天然和人工蛋白质中的少量蛋白质都在 HEWL 的一个数量级内,这比所有阴性对照都活跃得多。 这些高度活跃的异常值证明了我们的模型有可能生成可以与通过进化压力高度优化的天然蛋白质相媲美的序列。
从 100 种人工蛋白质中,我们选择了 5 种蛋白质,它们的最大 ID 范围很广 (48–89%),以在大肠杆菌中重组表达。 其中,只有一个 L008 没有产生可检测的表达(补充图 7)。 两个(L013 和 L038)对包涵体表达强烈,没有进一步研究。 两种蛋白质 L056(最大 ID 69.6%)和 L070(最大 ID 89.2%)表达良好,并对在 16 °C 过夜诱导期间使用的大肠杆菌 BL21(DE3) 菌株产生杀菌活性。 用过的培养基具有酶活性,因此从该材料中纯化酶。
虽然这两种酶都通过尺寸排阻色谱纯化为预期大小的单体,但我们还观察到每种酶的确定的后期洗脱(明显较低的分子量,可能是由于与柱的葡聚糖成分结合)对应于全- 通过 SDS-PAGE 检测长度酶(补充图 7)。 两种单体的 KM 值都太弱,无法使用异质荧光素标记的 M. lysodeikticus 细胞壁底物(Molecular Probes EnzChek 溶菌酶试剂盒)进行测量; 然而,使用伪一级动力学测定法,两种单体都具有活性(补充图 8)。 相比之下,我们可以很容易地测量纯化的表观低分子量物质的 KM 值,其中 L056 和 L070 都具有高活性并且具有与 HEWL 相当的米氏参数(图 3d)。 总之,L056 和 L070 具有与 HEWL 相当的强大催化活性和杀菌能力,同时与它们最接近的已知天然序列分别相差 53 和 18 个氨基酸。 我们还发现,对于将 L056 和 L070 与其自然界中各自最近的序列同源物分开的突变,位置或结构元素没有偏差。 相反,不同的残基均匀分布。 甚至在活性位点裂隙和影响构象状态的区域内发现了一些突变(对于 L056)。 尽管具有可比较的酶活性,但 L070 和 L056 仅共享 17.9% 的序列 ID。 总之,这些结果表明 ProGen 可以生成具有接近天然活性的人工蛋白质。
接下来,我们检查了人工蛋白质的结构差异。 我们确定了 L056 的 2.5-Å 分辨率晶体(图 3e 和补充表 6)。 全局折叠与预测相似,Cα 均方根偏差 (RMSD) 与 trRosetta 预测的主链结构相差 2.9 Å,而与野生型 T4 溶菌酶结构相差 2.3 Å RMSD48, 49。 最大的结构差异发生在由残基 18-31 形成的 β 发夹中。 该区域形成底物结合裂缝的底部,是对底物结合很重要的铰链结合运动的一部分 51。 T4 溶菌酶的 M6I 突变体(蛋白质数据库 (PDB) 登录号 150L)的结构用作该铰链“打开”状态的模型,更类似于 L056 (1.0 Å Cα RMSD) 的结构。 与具有共价捕获底物(PDB 登录号 148L)的结构比对表明,活性位点裂缝形成良好,关键催化残基 Glu15(T4L 中的 Glu 11)和关键底物结合残基 Thr30(T4L 中的 Thr26)正确定位。 此外,L056 的疏水核心堆积良好,只有两个体积小于 5 Å3 的小堆积空隙,这是这种尺寸结构的典型特征52。
为了检查 ProGen 是否可以在“暮光之城”序列同一性 53 中生成功能性蛋白质,其中两种蛋白质不假定具有功能相似性 54,我们生成了 95 个新的人工序列,其最大序列同一性低于两个溶菌酶家族任何已知天然蛋白质的 40% (PF00959 和 PF05838)。 在所选序列中,89 个中的 78 个(88%)表达良好,78 个中的 24 个(31%)可溶(补充图 9)。 我们纯化了六种高度表达的蛋白质,发现它们都具有活性,但米氏活性低于 HEWL 或先前生成的人工蛋白质 L056 和 L070(图 3f、补充图 10 和补充表 7)。 与天然蛋白质 D4 具有最低序列同一性的蛋白质(与硝基弧杆菌生物体的蛋白质的 31.4% ID)具有 20.2 M-1s-1 的 kcat/KM,比 HEWL 低约 200 倍。 虽然这些远距离蛋白质的活性大大降低,但可以采用定向进化来提高活性。 总的来说,这些结果证明了一种生成可溶性活性蛋白质的程序,这些蛋白质在序列空间中距离足够远,以至于它们可能不被视为传统的序列同源物。
为了进一步比较结构表示,我们使用 AlphaFold2(参考文献 14)来预测功能人工序列的结构。 与 L056 的晶体结构一样,预测的人工结构与自然界中发现的已知结构(补充图 11)大致匹配,包括低同一性(<40%)人工序列。
为了进一步比较结构表示,我们使用 AlphaFold2(参考文献 14)来预测功能人工序列的结构。 与 L056 的晶体结构一样,预测的人工结构与自然界中发现的已知结构(补充图 11)大致匹配,包括低同一性(<40%)人工序列。
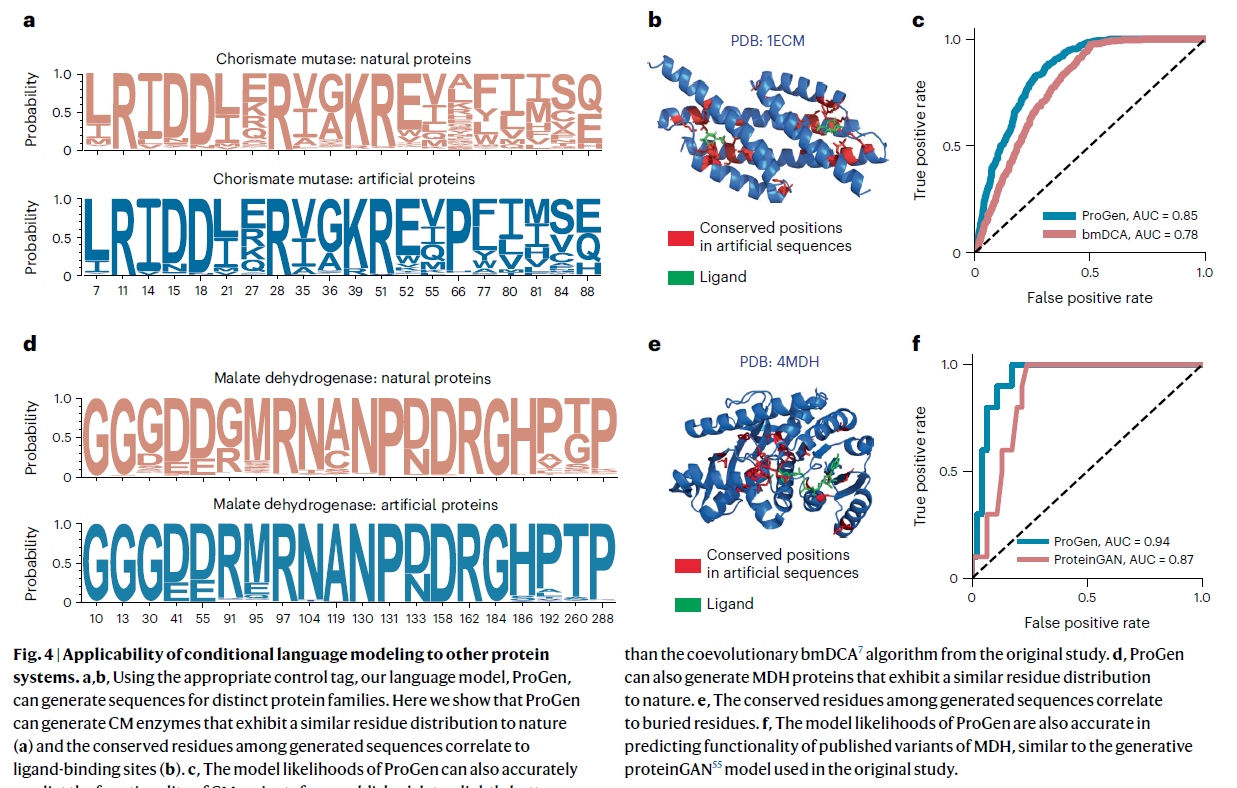
ProGen 在跨越许多家族的通用蛋白质序列数据集上进行训练,当提供相应的控制标签作为输入时,ProGen 可以设计来自任何家族的蛋白质。 为了探索溶菌酶家族以外的这种能力,我们评估了 ProGen 在生成和预测功能性全长序列方面的性能,这些序列来自以前应用过其他方法的家族:分支酸变位酶 (CM)7 和苹果酸脱氢酶 (MDH)。 生成的蛋白质表现出与天然序列库相似的保护模式(图 4a、d)。 在将世代与具有已知结构的序列对齐后(图 4b,e),我们观察到生成序列中的保守位置与配体结合和掩埋残基相关。 使用先前公布的序列及其对 CM7 和 MDH55 蛋白的实验测量测定数据,我们还评估了这些序列的 ProGen 模型可能性与其相对活性的一致性,并将其与原始研究中使用的生成方法(bmDCA7 和 proteinGAN55)进行了比较。 具体来说,我们使用 Pro-Gen 测量了人工序列的每个标记对数似然值,并使用它们来预测人工序列是否应该起作用。 在 CM 函数数据上,ProGen 对数似然的曲线下面积 (AUC) 为 0.85,显着优于(P < 0.0001,双尾检验,n = 1617)bmDCA,后者的 AUC 为 0.78(图 4c) ). 在 MDH 函数数据上,ProGen 对数似然的 AUC 为 0.94(图 4f),优于 ProteinGAN 鉴别器得分,AUC 为 0.87(P < 0.1,双尾检验,n = 56)。 总而言之,ProGen 的模型可能性与两个不同蛋白质数据集(CM 和 MDH)上的实验测量测定数据比专门为这些家族定制的原始研究的序列生成方法更一致。
为了解通用序列数据集和目标蛋白质家族序列对 ProGen 生成能力的相对影响,我们使用 CM 和 MDH 实验测量的测定数据进行了两项消融研究。 首先,我们评估了仅使用通用序列数据集训练的 ProGen 的性能。 我们使用 CM 和 MDH 的控制标签测量了此版本 ProGen 的人工序列的每个标记对数似然。 这些可能性显示 CM 的 AUC 显着下降 0.18(P < 0.0001,双尾测试,n = 1,617),MDH 的 AUC 显着下降 0.08(P < 0.1,双尾测试,n = 56),与 fine- 在预测人工序列是否应该起作用时调整了 ProGen。 相反,与微调的 ProGen 相比,仅在 CM 和 MDH 蛋白质序列上训练而没有在通用序列数据集上进行初始训练的 ProGen 架构也表现出显着的性能下降——AUC 减少了 0.11(P < 0.0001,两个 -尾部测试,n = 1,617) 和 0.04(P < 0.05,双尾测试,n = 56)分别针对 CM 和 MDH 数据。
这些结果表明,我们训练策略的两个组成部分——对通用序列数据集的初始训练和对感兴趣的蛋白质家族的微调——对最终模型性能有显着贡献。 使用包含许多蛋白质家族的通用序列数据集进行训练,使 ProGen 能够学习编码内在生物学特性的通用且可转移的序列表示。 微调感兴趣的蛋白质家族可以引导这种表示,以提高局部序列邻域的生成质量。 类似于在自然语言处理 25、34、56 和计算机视觉 57、58 中使用迁移学习和微调在大型数据集上训练的神经网络所显示的适应性,蛋白质语言模型有可能成为生成具有所需特性的定制蛋白质的多功能工具 . 在补充图 12 中,不同蛋白质家族的可用序列分布表明,我们目前的技术在蛋白质宇宙中有很大一部分是有用的。 我们推断,无需微调即可成功生成具有功能活性的人工蛋白质,尤其是对于较大的蛋白质家族; 但是,这样做的成功率可能很小。 在我们的研究中,我们没有尝试在没有额外微调的情况下通过实验测试生成的序列。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









