





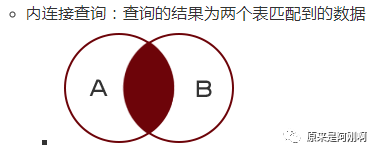
连接查询操作
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回。
mysql支持三种类型的连接查询,分别为:


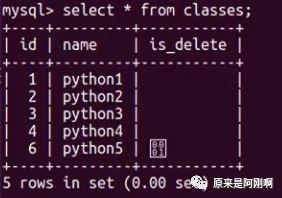
下面是一个班级表:
create table classes(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
isdelete bit default 0
);
insert into classes values
(1,"python1", 0),
(2,"python2",0),
(3,"python3",0),
(4,"python4",0),
(6,"python5", 1);
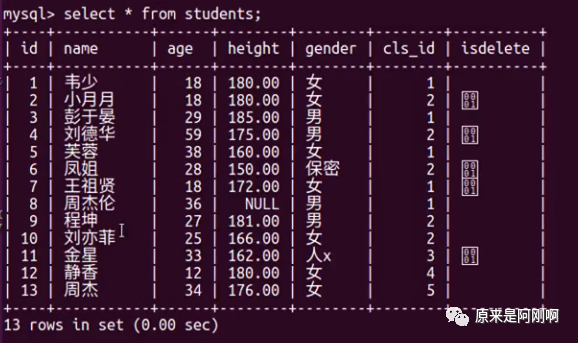
下面是一个学生表:
注意:一个数据库中如果有多个表的话,表名是不能省略的。

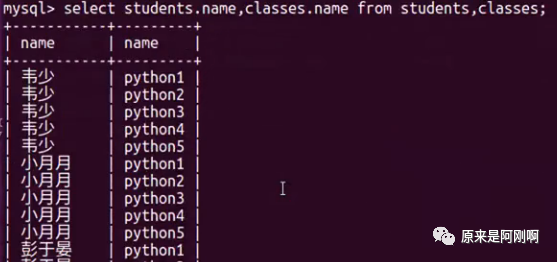
出来的数据不太符合。
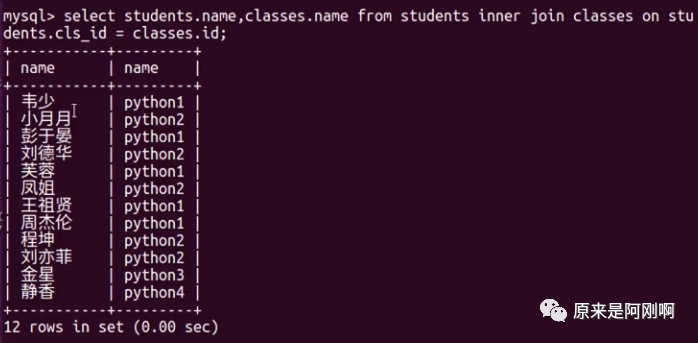
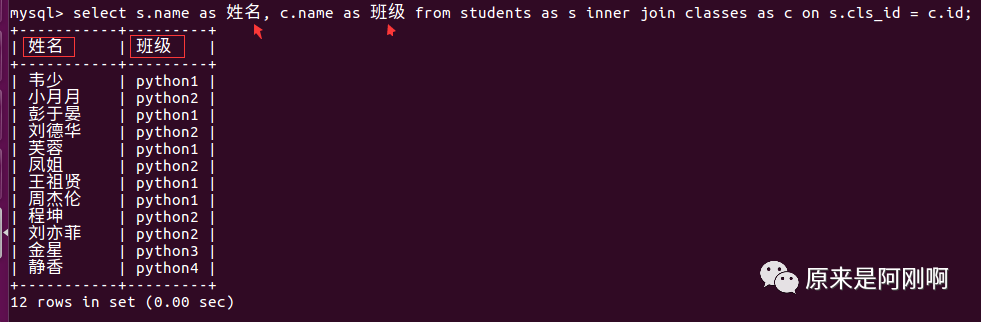
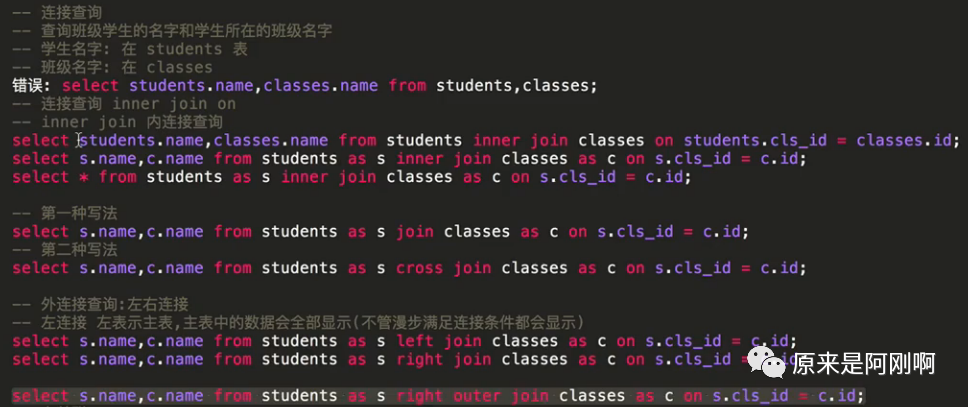
使用内连接查询班级表与学生表

on后面跟着连接查询的条件。
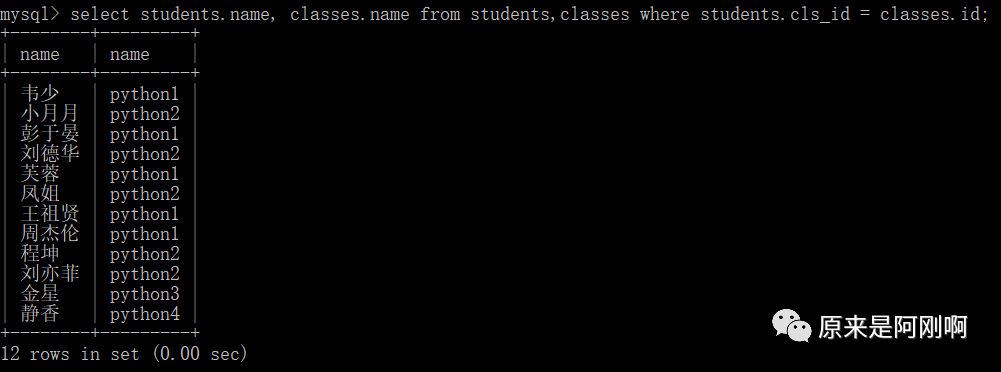

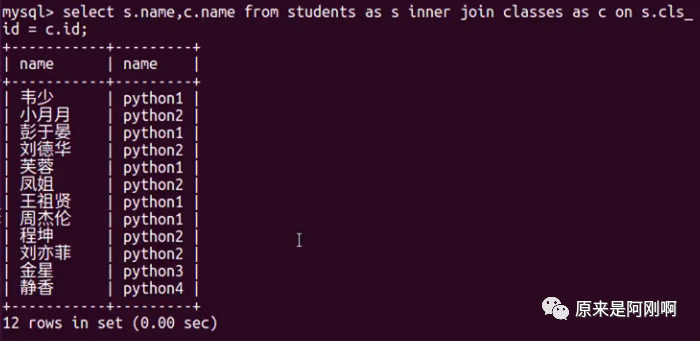
可以通过as将sql语句简化一下:

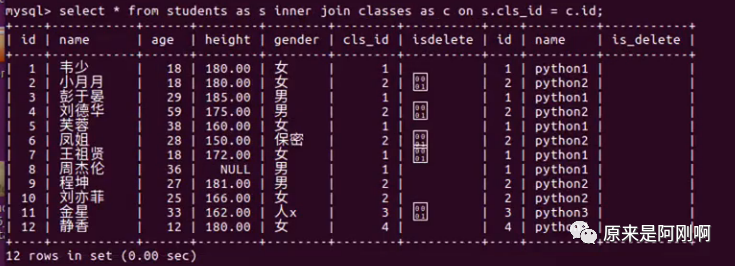
左右连接查询
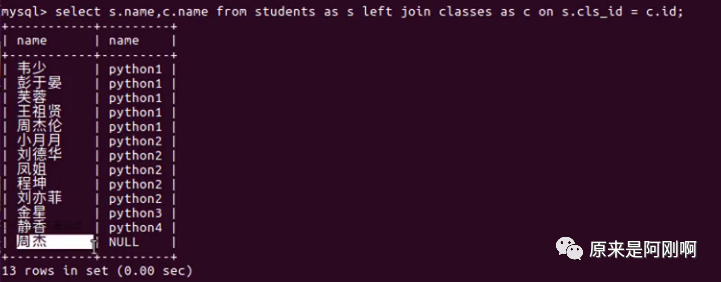
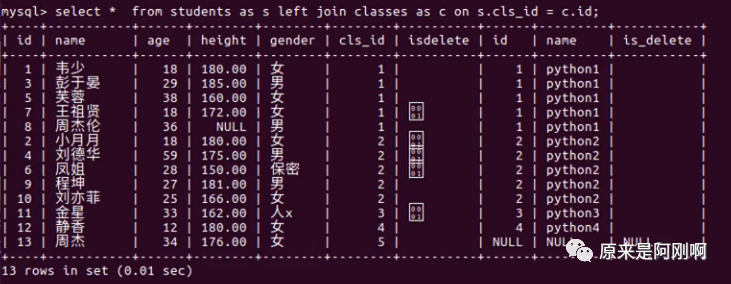
左右连接有主和从的关系。
左连接,那students是主表,那classes是从表。


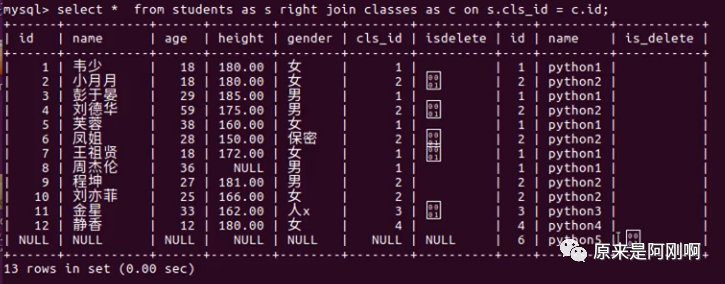
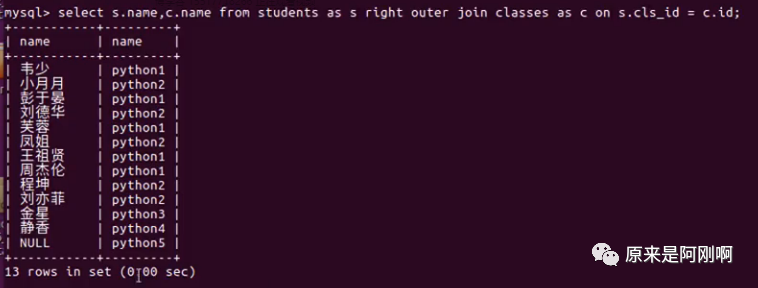
右连接查询:就是以classes为主表,那students就是从表。
(了解)连接查询的其他的写法扩充---自行学习
下面是内连接的两种简写形式:
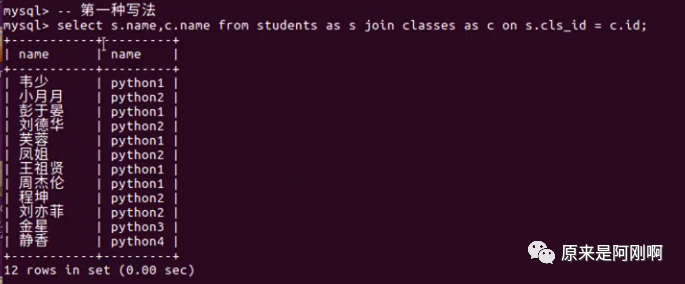
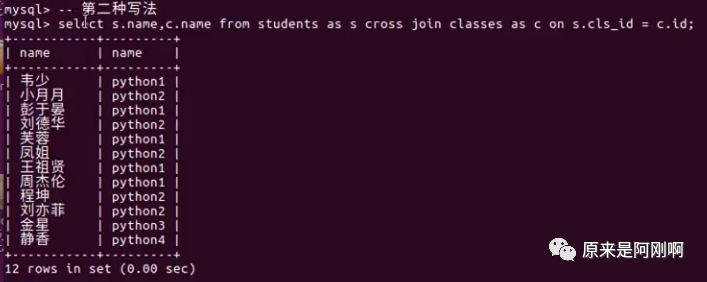
下面是右连接的另外一种语法形式:
还有left outer join这种语法---可以自行测试一下。
自关联查询的基本操作
准备工作:
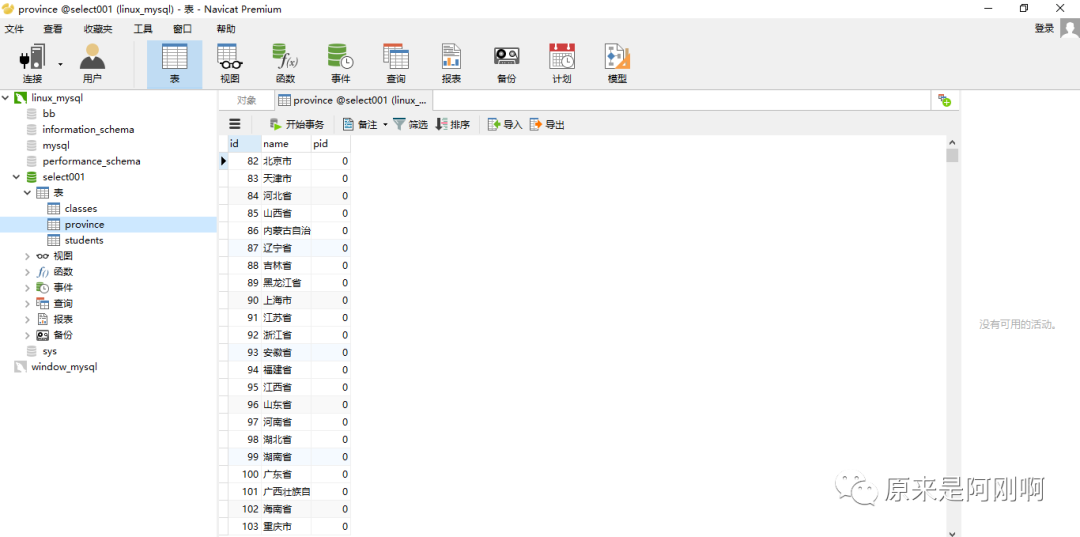
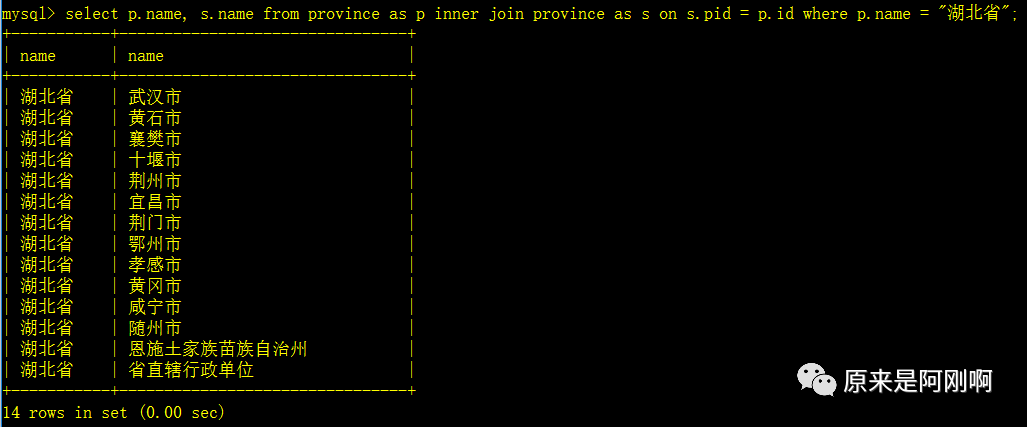
查询所有的省和自治区:
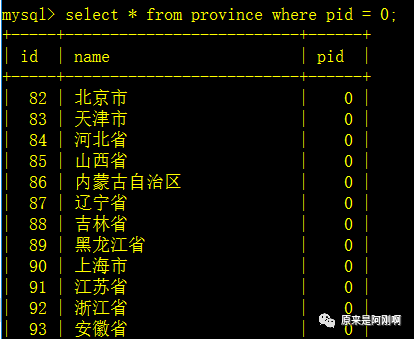

统计中国所有的省和自治区和直辖市:

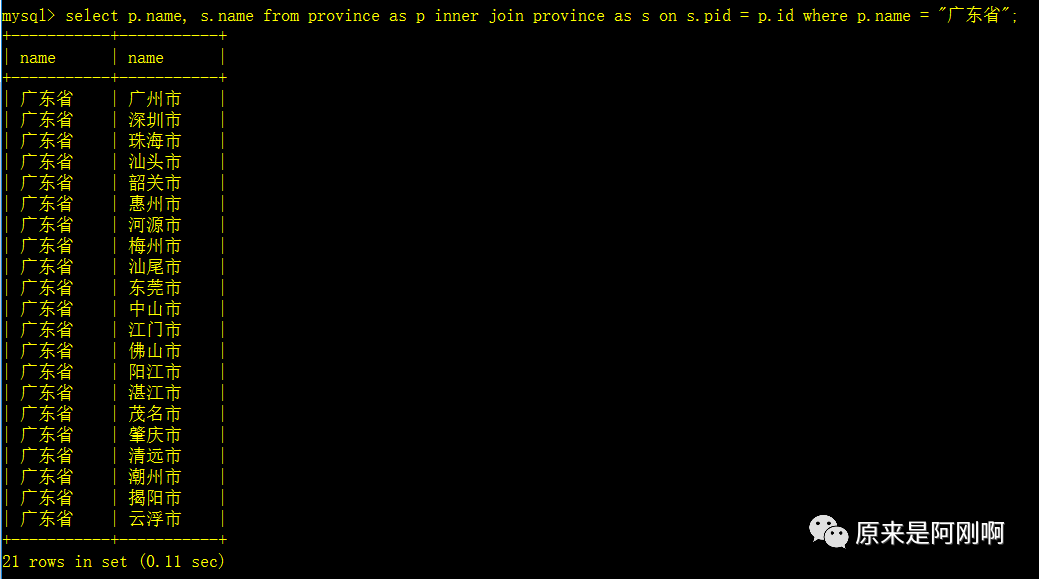
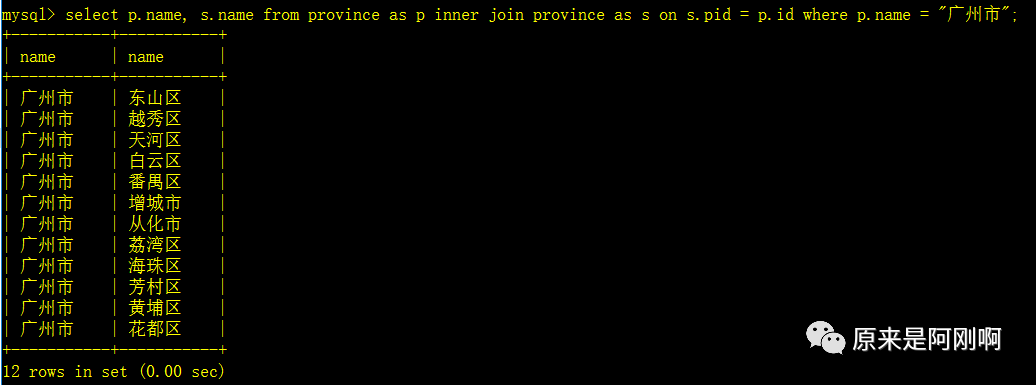
查询广东省都有哪些市(想像成两张表):
子查询的概念和分类
子查询
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句
主查询
主要查询的对象,第一条 select 语句
主查询和子查询的关系
子查询是嵌入到主查询中
子查询是辅助主查询的,要么充当条件,要么充当数据源
子查询是可以独立存在的语句,是一条完整的 select 语句
子查询分类
标量子查询: 子查询返回的结果是一个数据(一行一列)
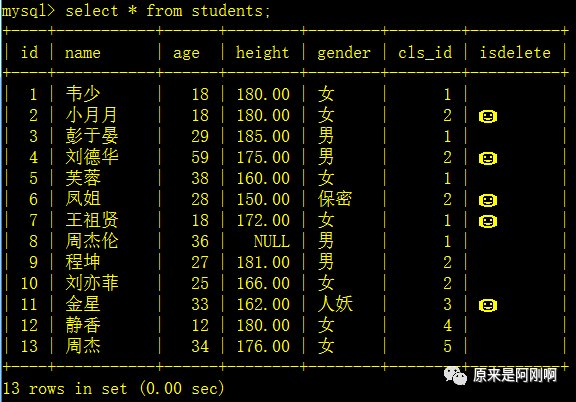
查询大于平均身高的学生
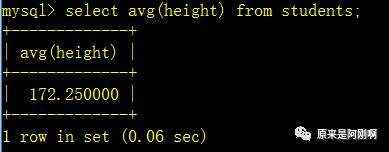
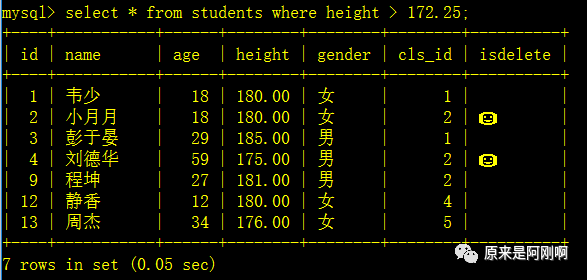
上面是分了两次进行查询出来想要的数据的,那也可以进行合并成一次查询,而且上面的查询是写死的,下面的这种形式是活的,当再添加与删除数据以后,都不用手动的改变:
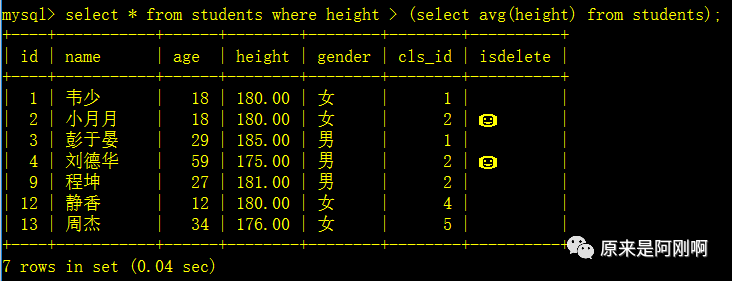
列级子查询: 返回的结果是一列(一列多行)
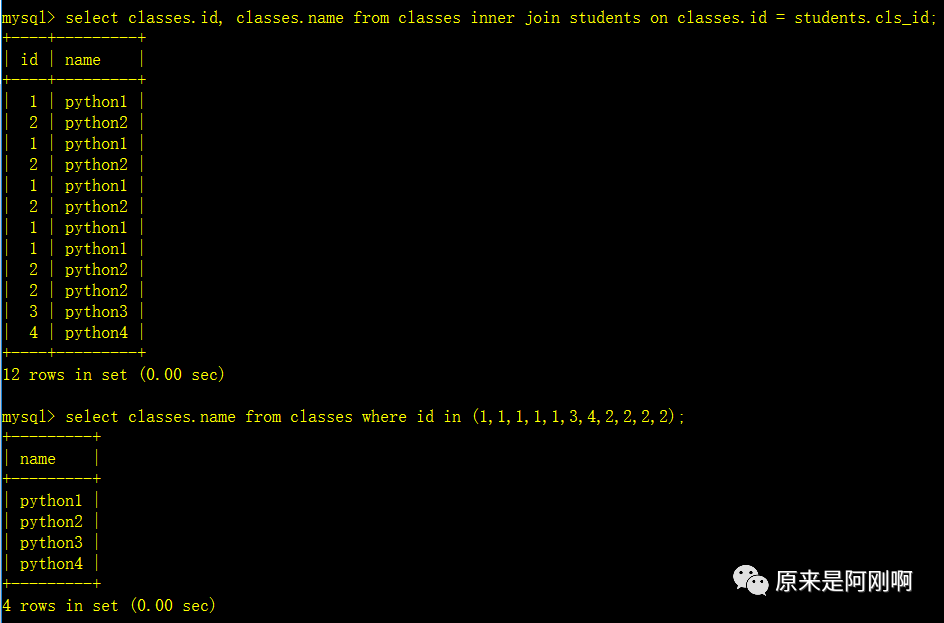
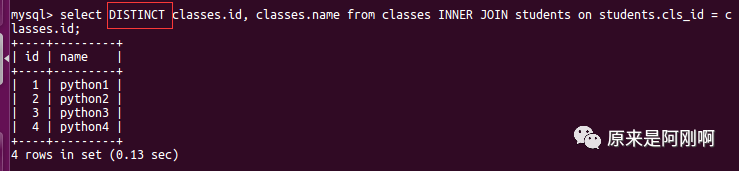
查询出有学生的班级都有哪些?

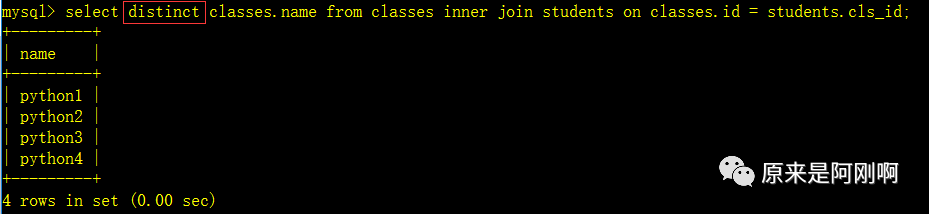
通过子查询去实现:
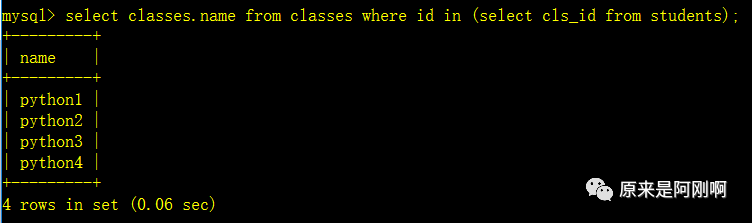
下面是将子查询换成了实现的结果,分步进行讲解了:
行级子查询: 返回的结果是一行(一行多列)
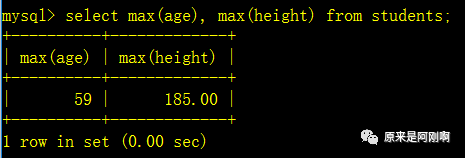
需求: 查找班级年龄最大,身高最高的学生
行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
查询结果为空说明这两个没有出现在同一个人的身上。
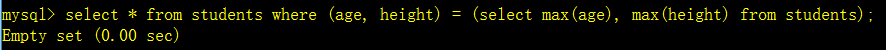

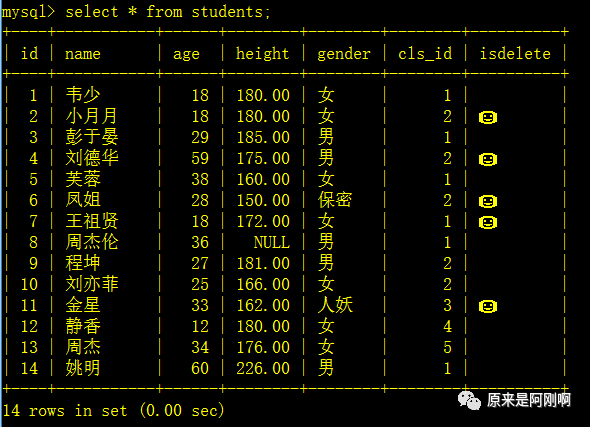

查询班级中年龄最小并且身高也最小的人:
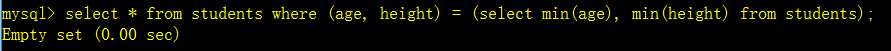

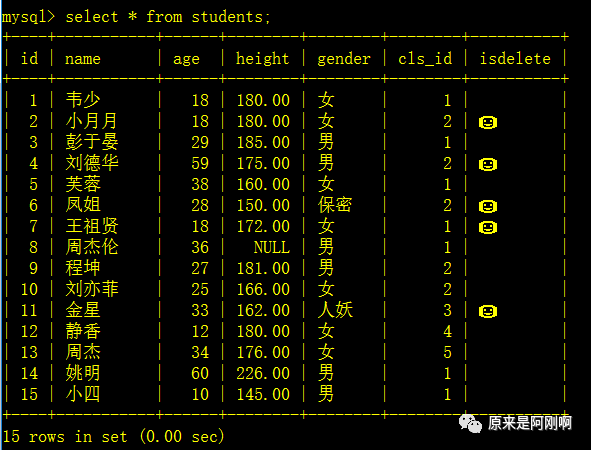

表级子查询: 返回的结果是多行多列
查询学生与班级对应的信息
下面是用上面讲的内连接查询实现的:
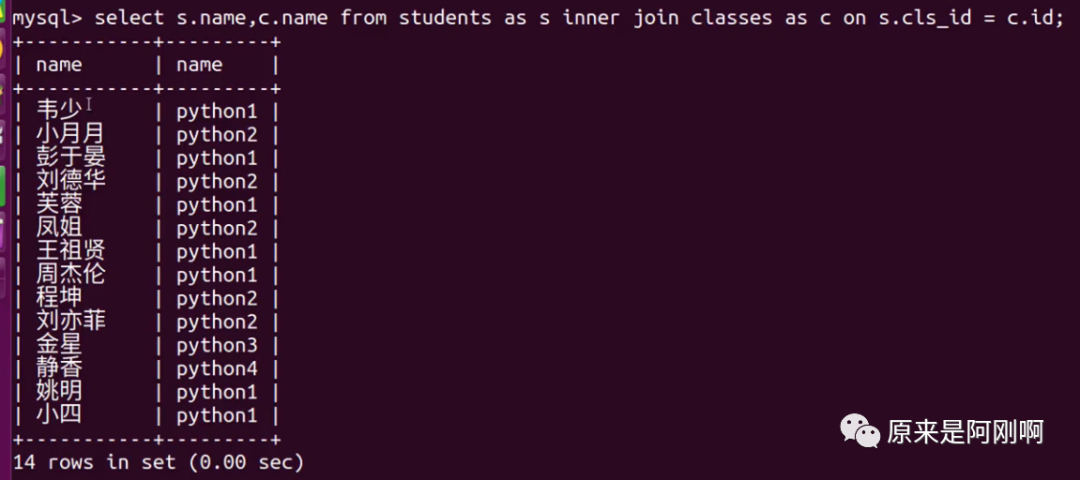
下面是使用子查询实现的:
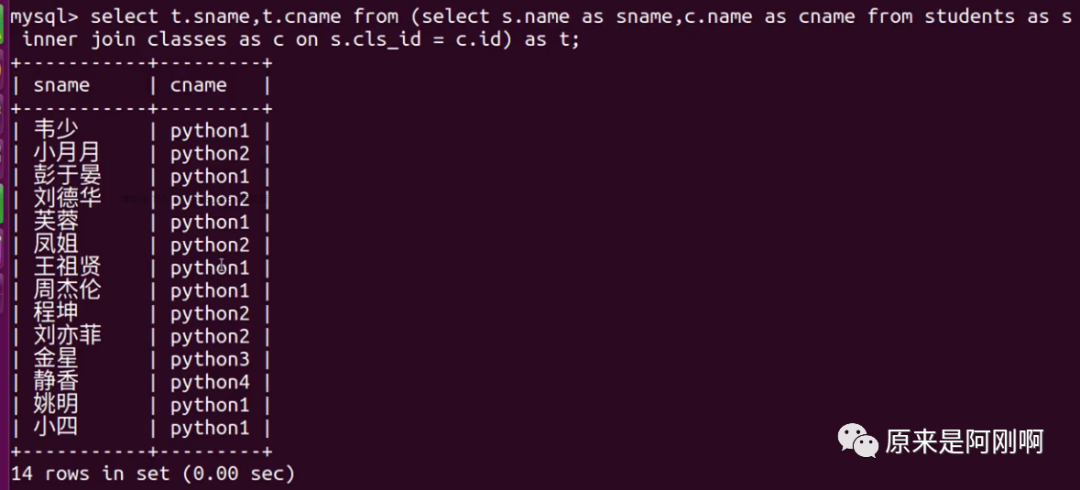
一般不用,查询效率相对费时间。
说明:发现很多表级子查询的语句,都是可以使用连接查询实现的,此时推荐使用连接查询,因为连接查询的语句更简洁,逻辑更清晰
子查询中出现的关键字
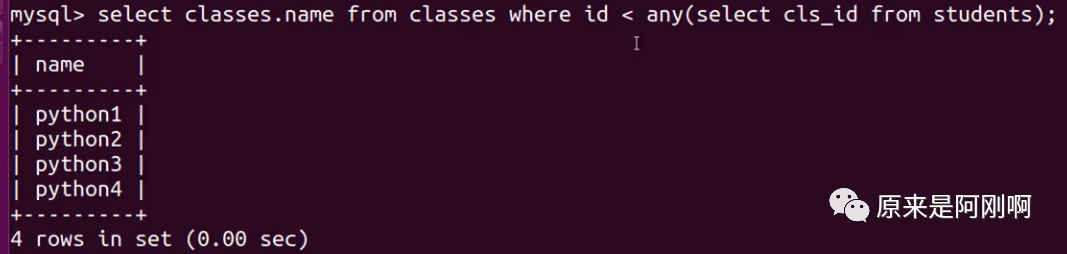
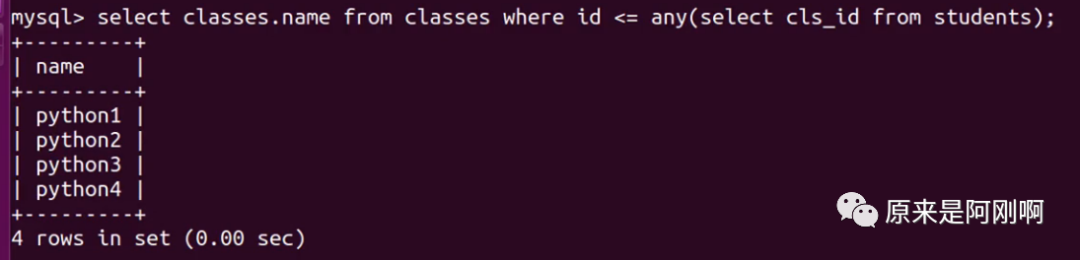
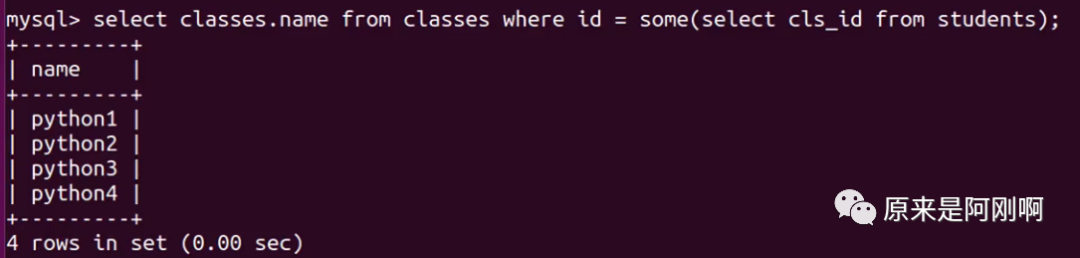
带any关键字的子查询:

any关键字表示满足其中任意一个条件,它允许创建一个表达式对子查询的返回值列进行比较,只要满足内层子查询中的任意一个比较条件,就返回一个结果作为外层查询条件。
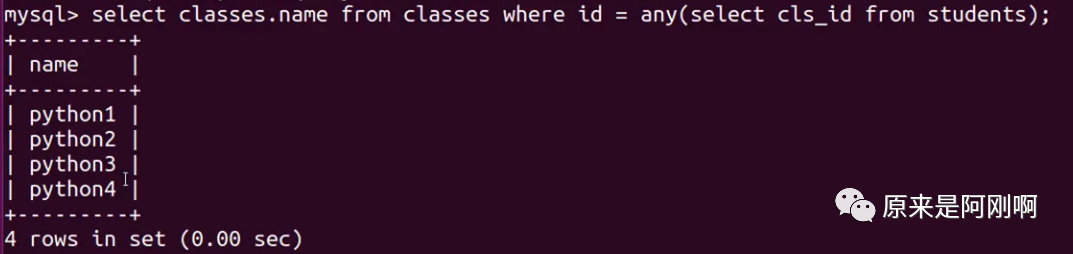

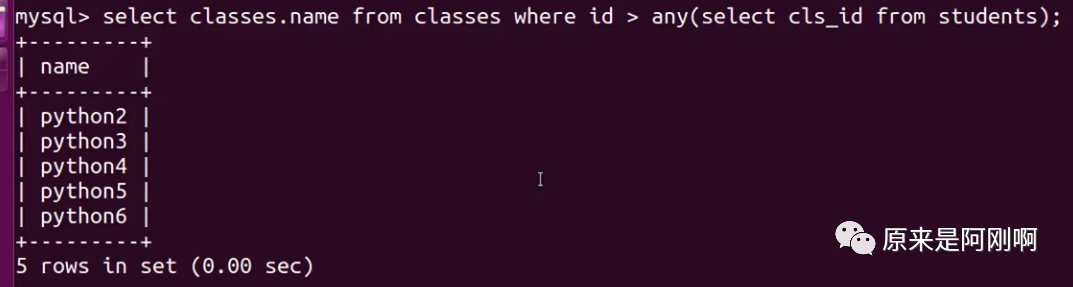
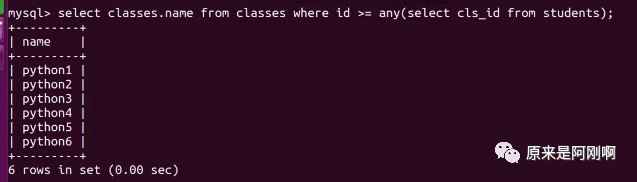
带all关键字的子查询:

all与any有点类似,只不过带all关键字的子查询返回的结果需同时满足所有内层查询条件。


带in关键字的子查询:


查询存在年龄为20岁的员工的部门。

在查询的过程中,首先:会执行内层子查询,得到年龄为20岁的员工的部分id,然后,再根据部门的id与外层查询的比较条件,最终最到符合条件的数据。
查询不存在年龄为20岁的员工的部门。
select语句中还可以使用not in关键字,其作用正好与in相反。

带exists关键字的子查询:
exists关键字后面的参数可以是任意一个子查询,这个子查询的作用相当于测试。它不产生任何数据,只返回true或flase,当返回值为true时,外层查询才会执行。
查询employee表中是否存在年龄大于21岁的员工,如果存在,则查询department表中的所有记录:

由于employee表中有年龄大于21岁的员工,因此,子查询的返回结果为true,所以,外层的查询语句会执行,即查询出所有的部门信息。
需要注意的是:exists关键字比in关键字的运行效率高,所以,在实际开发中,特别是大数据量时,推荐使用exists关键字。
带比较运算符的子查询:
在前面的子查询中使用了“>”比较运算符,子查询中还可以使用其他的比较运算符,如“=”“<=”“=”“!=”等。< span="">















 5620
5620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









