





注意:单击
此处https://urlify.cn/73Ib2m
下载完整的示例代码,或通过Binder在浏览器中运行此示例
RBF核的显式特征映射近似的一个示例。
它显示了如何使用
 sphx_glr_plot_kernel_approximation_001
sphx_glr_plot_kernel_approximation_001
 sphx_glr_plot_kernel_approximation_002
sphx_glr_plot_kernel_approximation_002
脚本的总运行时间:(0分钟2.019秒)
估计的内存使用量: 10 MB
RBFSampler
和
Nystroem
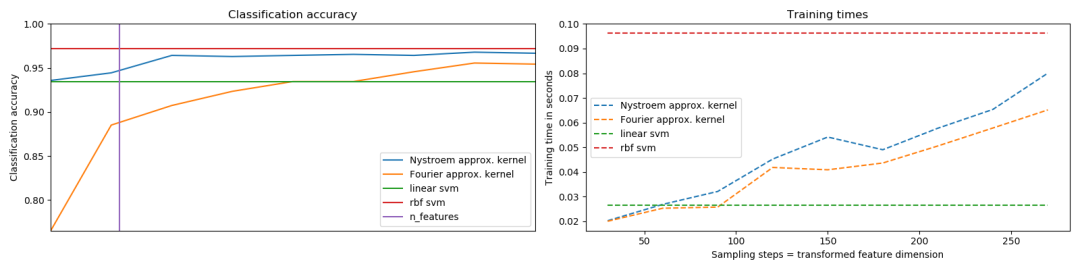
来近似RBF核的特征映射,以便在手写数字识别数据集上通过SVM来进行分类。比较了使用原始空间中的线性SVM、使用映射近似的线性SVM和使用内核化SVM的结果,显示了不同数量的蒙特卡洛采样(在使用随机傅立叶特征的
RBFSampler
的情况下)的时间和精度,以及用于映射近似的训练集(
Nystroem
)的不同大小的子集。
请注意,这里的数据集不足以显示核近似的好处,因为精确的SVM仍然相当快。
对更多维度进行采样显然会带来更好的分类结果,但代价更高,这意味着在运行时间和精度之间需要权衡,这由参数n_components决定。请注意,通过使用随机梯度下降可以大大加速解线性SVM和核近似SVM
sklearn.linear_model.SGDClassifier
的速度,但是对于内核化SVM来说,这是不容易实现的。
导入Python包,加载数据集
# 作者: Gael Varoquaux # Andreas Mueller # 许可证: BSD 3 clauseprint(__doc__)# 导入Python标准科学计算库import matplotlib.pyplot as pltimport numpy as npfrom time import time# 导入数据集,分类器,性能度量(metrics)from sklearn import datasets, svm, pipelinefrom sklearn.kernel_approximation import (RBFSampler, Nystroem)from sklearn.decomposition import PCA# 手写数字识别数据集digits = datasets.load_digits(n_class=9)绘制时间和准确性的图
要将分类器应用于此数据,我们需要将图像展平,来将数据转换为(样本,特征)矩阵。n_samples = len(digits.data)data = digits.data / 16.data -= data.mean(axis=0)# 取数据集的一半进行学习data_train, targets_train = (data[:n_samples // 2], digits.target[:n_samples // 2])# 现在在另一半数据集上进行预测:data_test, targets_test = (data[n_samples // 2:], digits.target[n_samples // 2:])# data_test = scaler.transform(data_test)# 创建一个分类器:一个支持向量分类器kernel_svm = svm.SVC(gamma=.2)linear_svm = svm.LinearSVC()# 创建一个来自核近似的管道(pipeline)# 和线性svmfeature_map_fourier = RBFSampler(gamma=.2, random_state=1)feature_map_nystroem = Nystroem(gamma=.2, random_state=1)fourier_approx_svm = pipeline.Pipeline([("feature_map", feature_map_fourier), ("svm", svm.LinearSVC())])nystroem_approx_svm = pipeline.Pipeline([("feature_map", feature_map_nystroem), ("svm", svm.LinearSVC())])# 使用线性和核svm进行训练和预测:kernel_svm_time = time()kernel_svm.fit(data_train, targets_train)kernel_svm_score = kernel_svm.score(data_test, targets_test)kernel_svm_time = time() - kernel_svm_timelinear_svm_time = time()linear_svm.fit(data_train, targets_train)linear_svm_score = linear_svm.score(data_test, targets_test)linear_svm_time = time() - linear_svm_timesample_sizes = 30 * np.arange(1, 10)fourier_scores = []nystroem_scores = []fourier_times = []nystroem_times = []for D in sample_sizes: fourier_approx_svm.set_params(feature_map__n_components=D) nystroem_approx_svm.set_params(feature_map__n_components=D) start = time() nystroem_approx_svm.fit(data_train, targets_train) nystroem_times.append(time() - start) start = time() fourier_approx_svm.fit(data_train, targets_train) fourier_times.append(time() - start) fourier_score = fourier_approx_svm.score(data_test, targets_test) nystroem_score = nystroem_approx_svm.score(data_test, targets_test) nystroem_scores.append(nystroem_score) fourier_scores.append(fourier_score)# 绘制出结果:plt.figure(figsize=(16, 4))accuracy = plt.subplot(121)# 第二个y轴是时间(second y axis for timings)timescale = plt.subplot(122)accuracy.plot(sample_sizes, nystroem_scores, label="Nystroem approx. kernel")timescale.plot(sample_sizes, nystroem_times, '--', label='Nystroem approx. kernel')accuracy.plot(sample_sizes, fourier_scores, label="Fourier approx. kernel")timescale.plot(sample_sizes, fourier_times, '--', label='Fourier approx. kernel')# 精确rbf和线性核的水平线:accuracy.plot([sample_sizes[0], sample_sizes[-1]], [linear_svm_score, linear_svm_score], label="linear svm")timescale.plot([sample_sizes[0], sample_sizes[-1]], [linear_svm_time, linear_svm_time], '--', label='linear svm')accuracy.plot([sample_sizes[0], sample_sizes[-1]], [kernel_svm_score, kernel_svm_score], label="rbf svm")timescale.plot([sample_sizes[0], sample_sizes[-1]], [kernel_svm_time, kernel_svm_time], '--', label='rbf svm')# 数据集dimensionality = 64的竖线accuracy.plot([64, 64], [0.7, 1], label="n_features")# 图例和标签accuracy.set_title("Classification accuracy")timescale.set_title("Training times")accuracy.set_xlim(sample_sizes[0], sample_sizes[-1])accuracy.set_xticks(())accuracy.set_ylim(np.min(fourier_scores), 1)timescale.set_xlabel("Sampling steps = transformed feature dimension")accuracy.set_ylabel("Classification accuracy")timescale.set_ylabel("Training time in seconds")accuracy.legend(loc='best')timescale.legend(loc='best')plt.tight_layout()plt.show()RBF核SVM和线性SVM的决策面
第二个图可视化了带有特征映射近似的RBF核SVM和线性SVM的决策面。该图显示了数据前两个主要分量的投影(components)分类器的决策面。特别要注意的是,数据点(用点表示)不一定要分类到它所在的区域,因为它可能不会位于前两个主要分量所构成的平面上。RBFSampler
和
Nystroem
在
核近似
上有详细描述。
# 可视化第一个主要分量的投影的决策面# 数据集的两个主要分量pca = PCA(n_components=8).fit(data_train)X = pca.transform(data_train)# 沿着前两个主要分量构建网格multiples = np.arange(-2, 2, 0.1)# 沿着第一个分量first = multiples[:, np.newaxis] * pca.components_[0, :]# 沿着第二个分量second = multiples[:, np.newaxis] * pca.components_[1, :]# 结合grid = first[np.newaxis, :, :] + second[:, np.newaxis, :]flat_grid = grid.reshape(-1, data.shape[1])# 要绘制的图的标题titles = ['SVC with rbf kernel', 'SVC (linear kernel)\n with Fourier rbf feature map\n' 'n_components=100', 'SVC (linear kernel)\n with Nystroem rbf feature map\n' 'n_components=100']plt.figure(figsize=(18, 7.5))plt.rcParams.update({'font.size': 14})# 预测和绘制图for i, clf in enumerate((kernel_svm, nystroem_approx_svm, fourier_approx_svm)): # 绘制决策边界。对于每一个边界,我们需要绘制不同颜色 # 在mesh [x_min, x_max]x[y_min, y_max]中的点。 plt.subplot(1, 3, i + 1) Z = clf.predict(flat_grid) # 把结果放进一个彩色图中 Z = Z.reshape(grid.shape[:-1]) plt.contourf(multiples, multiples, Z, cmap=plt.cm.Paired) plt.axis('off') # 也要绘制训练数据 plt.scatter(X[:, 0], X[:, 1], c=targets_train, cmap=plt.cm.Paired, edgecolors=(0, 0, 0)) plt.title(titles[i])plt.tight_layout()plt.show()
下载Python源代码: plot_kernel_approximation.py
下载Jupyter notebook源代码: plot_kernel_approximation.ipynb
由Sphinx-Gallery生成的画廊
文壹由“伴编辑器”提供技术支持
☆☆☆为方便大家查阅,小编已将scikit-learn学习路线专栏 文章统一整理到公众号底部菜单栏,同步更新中,关注公众号,点击左下方“系列文章”,如图:
欢迎大家和我一起沿着scikit-learn文档这条路线,一起巩固机器学习算法基础。(添加微信:mthler,备注:sklearn学习,一起进【sklearn机器学习进步群】开启打怪升级的学习之旅。)
















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









