





概述
虽然很多人都有针对这个60秒性能分析的翻译,不过这里还是要重写一遍,主要做备忘!下面先介绍10个命令列表

上述的10个命令基本涵盖了cpu,内存,硬盘,网络以及内核错误等多个方面,能在短时间内快速评估系统以及进程的运行状态。这些命令需要安装sysstat包。
如果你记不住命令,可以用下图的宏观模式来辅助记忆,此图摘自另外一个强人RiboseYim:
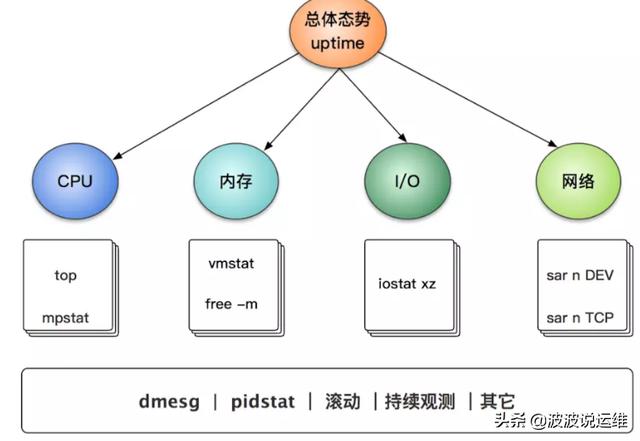
01
uptime
uptime gives a one line display of the following information. The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes.当前用户数目以及最近1分钟,5分钟以及15分钟的系统平均负载。系统平均负载指的是处于runnable(运行进程或者就绪进程)或者uninterruptable(不可中断的等待进程)状态的平均的进程数目。
$ uptime
上面的这个例子表明负载在不断上升,因为最近1分钟与最近15分钟的平均负载基本持平。
02
dmesg | tail
用于给出最近的10条系统消息,有些错误可能会报告出来。
$ dmesg | tail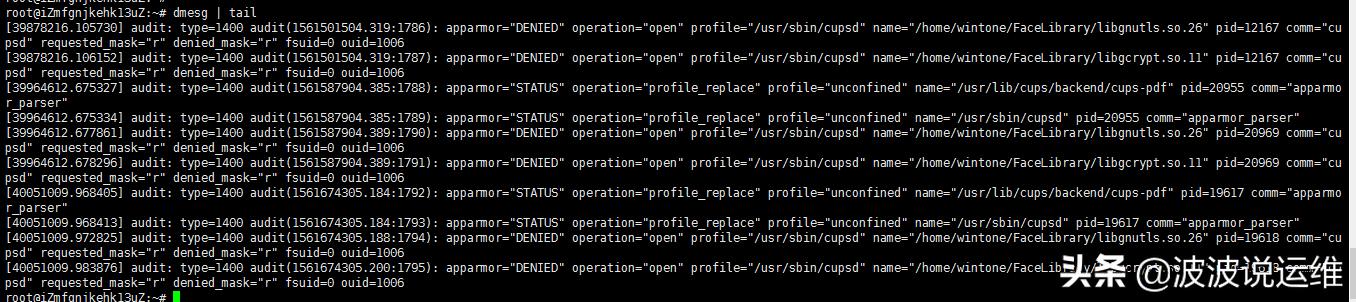
03
top
这是查看一个能查看多种指标的工具,先简单将它归为查看cpu的工具。它的自动刷新机制可能使得历史数据被清除。
$ top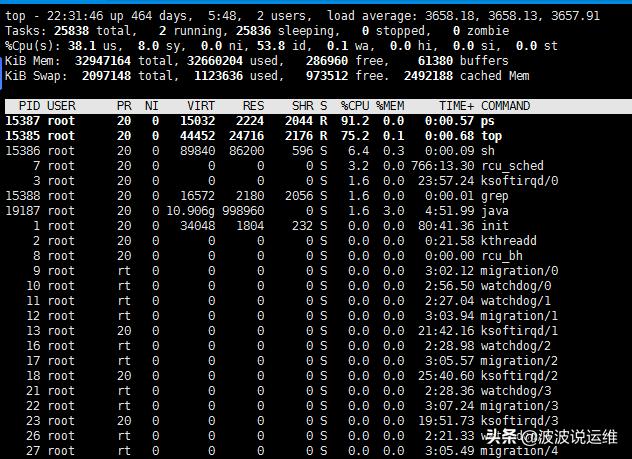
04
mpstat -P ALL 1
$ mpstat -P ALL 1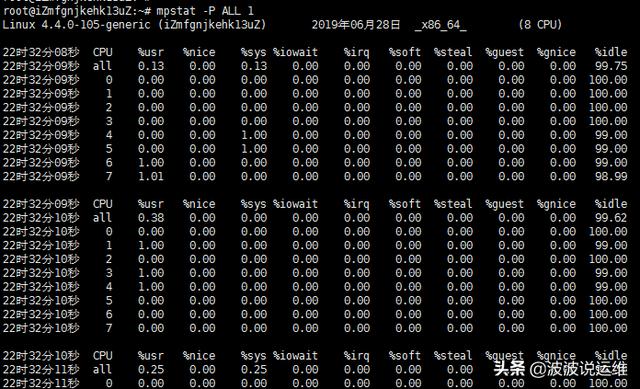
刚才的top关系的是整体cpu的情况,而mpstat关注的是每个cpu processor(注意这个是逻辑核心)的情况,可帮助查看各个cpu逻辑核是否负载均衡。例如如果只有一个cpu繁忙,那可判断属于单进程的程序。
例如我们的机器有8个cpu。因此,从mpstat来看一共是8个逻辑核心,cpu利用率最高为800%。
05
free -m
这个命令相信大家都很熟悉了,主要是用来关注内存的情况。
$ free -m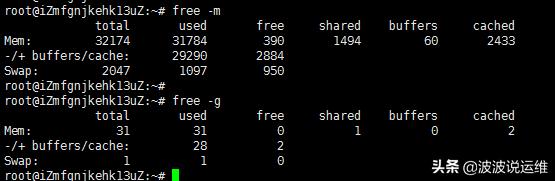
这里free代表当前的空闲内存,还不到1个G。如果free很小,可能会导致进程申请内存失败。
06
vmstat 1
$ vmstat 1 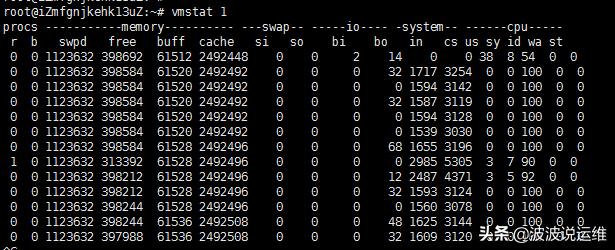
每个一秒输出一行,分别包括进程,内存,swap,I/O,系统以及cpu相关统计值。
简单总结几个注意点:
- r列:代表运行的进程数目(就绪或者运行),很大表明工作量很多;
- memeory列可以根据free -m的结果进行分析;
- si和so:如果它的值非0,表明内存不够用,交换分区起用了;
- us,sy等:代表user,sys,idle,wait,以及stole time。 user time很大表明用户任务繁忙,wait很大表明磁盘I/O时间很长,这个时候cpu一般是空闲的(需要阻塞等待),它类似于idle,但是不同的是,cpu处于等待I/O而无法执行。
07
iostat -xm 1
如果你的数据库正在做备份之类的动作,相信你的磁盘I/O一定很高,这时候可以怎么去观察呢?通过以下命令:
$ iostat -xm 1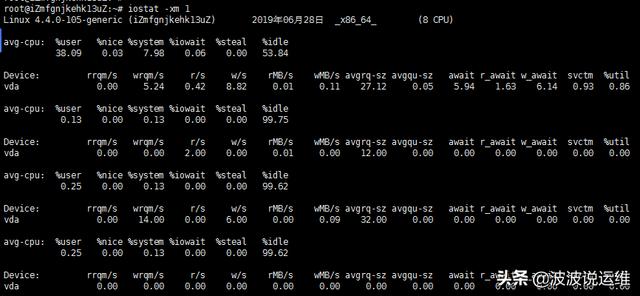
上面的数据太多列了,重点关注r/s, w/s, rMB/s, wMB/s, avgqu-sz, await, %util。
- r/s, w/s: 每秒读写设备的次数(可认为是随机读的次数),一般情况下随机读几百次硬盘就扛不住了;
- rMB/s, wMB/s: 每秒读写字节数;
- avgqu-sz: 平均的I/O等待队列大小,如果大于0,表明有I/O在等待;
- await:平均服务时间(包括等待以及服务的时间的总和);
- %util:磁盘利用率,这个太有用了,如果利用率为100%,那么磁盘I/O基本上处于饱和状态。
08
sar -n DEV 1
最后介绍下怎么去检测网络,命令如下:
$ sar -n DEV 1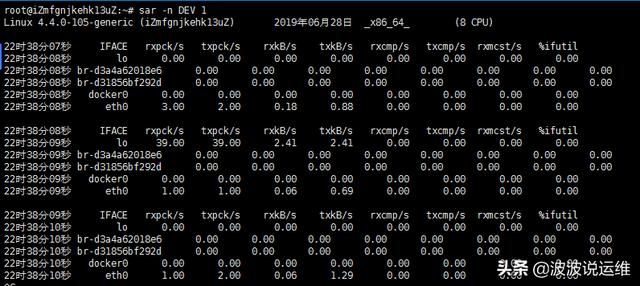
查看网络接口吞吐量,如下:
- rxpck/s, txpck/s: 网卡每条的读写(传入,传出)的packets数目;
- rxkB/s, txkB/s: 网卡每秒读写的字节数据量(可判断网卡是否打满)。
09
sar -n TCP, ETCP 1
实际业务中,TCP请求居多,这里可以重点关注一下TCP连接的请求相关情况。
$ sar -n TCP,ETCP 1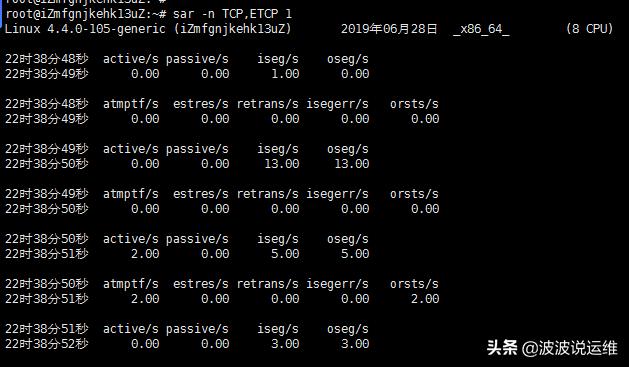
TCP和ETCP(error TCP)选项主要是用来关注正常或者异常的TCP相关负载参数,重点关注几个:
- active/s:主动发起的连接数目(每秒本地发起connect的数量);
- passive/s:每秒接收的连接数量(listen之后的accept的数量);
- iseg/s:输入的segment频率;
- oseg/s:输出逇segment频率;
- retrans/s:TCP重传的频率。
10
pidstat 1
上面你完全看完了,那么应该具有了基本感知,cpu,内存,磁盘和网络,以及dmesg。接下来介绍的pidstat可以看做是进程管理的一种情况,专门用来关注task的,可以看到pid的很多额外信息,例如内存,磁盘I/O等。
$ pidstat 1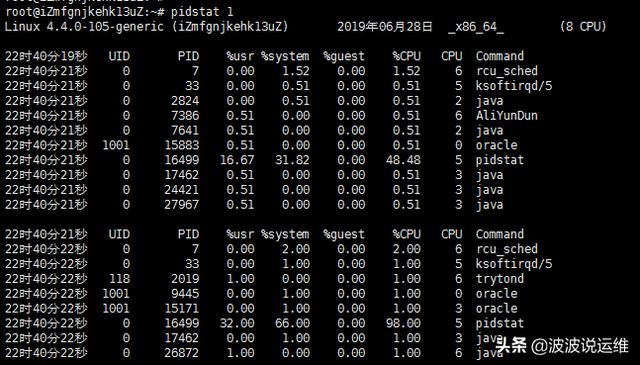
针对一个进程,一行记录,相比于top,它的优势在于是滚屏输出,而不是清屏。这样,有利于跟踪更长时间的窗口。
总结
针对上面的命令我这里简单对其归类了一下,总括(uptime),cpu(top, mpstat -P ALL 1),进程(pidstat 1),内存(vmstata 1, free -m),磁盘(iostat -xm 1)和网络(sar -n DEV 1, sar -n TCP,ETCP 1)。
后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注一下~















 2026
2026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









