





已经完成了利用python爬虫实现定时QQ邮箱推送英文文章,辅助学习英语的项目,索性就一口气利用python多做一些自动化辅助英语学习的项目,对自己的编程能力和英文水评也有一定的帮助,于是在两天的努力下,我完成了今天的项目。
首先是艾宾浩斯记忆法,大家了解一下真的非常有效果(至少对于我来讲啦┑( ̄Д  ̄)┍)
项目源码:
由于本人非常喜欢python和英语,所以后期也做很多将两者结合起来的项目。所以,如果大家对本项目有兴趣,希望体验或加入开发.
本项目主要是通过在事先准备好的excel单词文件中每天抽取单词,并反复使用QQ邮箱发送到自己的邮箱里提醒自己有一定规律的背单词,项目最大的难点有三。
对于csv文件的对应切片任务等操作
对于日志的记录
艾宾浩斯记忆法是一个周期性的过程,需要反复的计算。
当然,由于这个项目的文件还是比较多的,所以为了简化这个项目,我就先按照自己的开发思路来说,当然如果要自己来使用本项目还是要费一番心思读一读代码才好,因为在dataframe数据的处理部分随便拿一个小坑讲一下都是一篇文章(😂)所以,各位一定要耐心读下去鸭。
好了
show me the code
开发环境 :python3.6
IDEA : pycharm2019
阿里云ECS: centos7
接下来我们看一下项目路径,并注意对应进行解释:
(忽略我拙略的变量英文,就是因为这样所以才好好学习英语鸭)
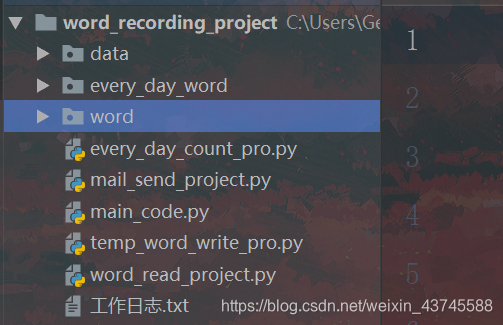
分别来解释一下
data 目录:
用于存放日志文件,分别有data_log.csv和word.csv
data_log.csv 用于每天随机抽取单词的时候避免抽取到重复的单词。
word.csv 是每天将每个单词的time时间数据记录进去进而用于计算单词复习的时间。
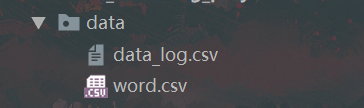
**every_day_word 目录**:
用于存储每天随机抽取的单词机器词义等相关信息,并将其存储为csv格式,以对应的时间为文件名存储,同步在上面的data_log.csv的time索引内。
word 目录 :
存储总的单词大表数据的目录,很简单。
接下来就是我们的项目代码部分,如你所见项目代码都在项目的根目录处,

接下来我会一 一的说明这些代码,当然是以我自己的顺序,对了代码的详细解释在代码的注释里面,有任何疑问和想法可以加入上面的群来交流。
word_read_project.py
这一部包含了多个函数与变量,是项目文件处理的第一核心部分,主要难点在于dataframe的控制问题以及日志的读写问题,需要耐心的看完,推荐搭配pycharm专业版使用,非常方便。
#auther :keepython
import pandas as pd
import numpy as np
import os
import time
import random
word_file_path = 'word/六级核心词汇表(EXCEL表格).xls'
data_log_path = 'data/data_log.csv'
# data_log = pd.read_csv(data_log_path)
words = pd.read_excel(word_file_path,header=0)
# print(len(words)+1)#求出一共多少列,从1开始算
# print(words.columns)#列索引名称
# print(words.index)#行索引名称
words_index = words.index
#函数功能:传入随机生成的单词索引,返回单词dataframe相关信息
def find_word(random_word_index,words):
print(type(random_word_index))
#根据随机单词的索引导出单词的相关信息
random_words = words.loc[list(random_word_index)]
# print(random_words)
return random_words
#函数功能: 在进行random_80函数操作以后对word.csv进行同步记录,注意传进来的必须是列表的形式
def word_csv_log(random_words,time_stamp):
word_path = 'data/word.csv'
word_log = pd.read_csv(word_path,index_col=0)#读取单词日志文件,同时将索引设置为对应的时间
for random_word in random_words:#将对应的随机抽取的单词5min,30min,12hour分别标记为1
word_log.loc['time'][random_word] = time_stamp
word_log.iloc[0:3][random_word][0] = 1
word_log.iloc[0:3][random_word][1] = 1
word_log.iloc[0:3][random_word][2] = 1
word_log.to_csv(word_path)
print('标记完成'.center(40,'='))
#函数功能:读取日志已经选择的单词索引内容返回列表
def data_log_read(data_log_path):
data_logs = pd.read_csv(data_log_path)
data_log_index = np.array(data_logs).tolist()
return data_log_index
#函数功能:通过索引提取dataframe中的行,返回对应的dataframe数据方便生成csv文件
def random_80_word_to_csv(random_index,words):
random_80_word_df = words.iloc[random_index,:]
return random_80_word_df
#函数功能:随机从传入的单词索引列表中抽取80个词
def random_80_word(words_indexs,words):
data_log_path = 'data/data_log.csv'
# print(type(words_index))#显示传入索引格式
try:
data_log_index = data_log_read(data_log_path)#返回日志中的索引
words_index = [i for i in words_indexs if i not in data_log_index]
except :
words_index= list(words_indexs)
random_word = random.sample(list(words_index),80)#同时记录被选中的索引数据
print(len(random_word))
random_words = find_word(random_word,words)[['单词']]
random_words = np.array(random_words).tolist()#这里是列表嵌套的形式需要解套
random_words = [i[0] for i in random_words]#将随机抽取的
#time模块的使用还要考虑到后面everyday_word.csv文件命名的问题,文件名称中不能有特殊符号
time_stamp = time.strftime("%Y-%m-%d-%H-%M", time.localtime())#使用time模块以对应的年-月-日-小时-分钟的形式返回的数据为字符串
every_day_word_path = 'every_day_word/'+str(time_stamp)+'.csv'
random_80_word_df = random_80_word_to_csv(random_word,words)#在这一步调用函数同时生成对应random文件数据
word_csv_log(random_words,time_stamp)
print(type(random_80_word_df))
random_80_word_df.to_csv(every_day_word_path)
data = {time_stamp: random_word}#用于data_log.csv路径不存在情况
if os.path.exists(data_log_path):#将今天生成的随机单词存入日志csv文件中备用
datas = pd.read_csv(data_log_path)
datas.loc[:, str(time_stamp)] = pd.Series(random_word)
# datas[time_stamp] = random_word #注意,由于日期的原因无法输入列索引相同的数据,dataframe本质有点像优化的数据库
datas.to_csv(data_log_path,index=False)#注意这里的mode的设置,必须设置为覆盖模式
else:
datas = pd.DataFrame(data)
datas.to_csv(data_log_path, index=False)
return random_word,every_day_word_path#将随机索引的80个词返回
random_word_index,every_day_word_path = random_80_word(words_indexs=words_index,words= words)
# print(random_word_index)
random_words_df = find_word(random_word_index,words)#返回的依然是dataframe格式的数据
# print(type(random_words))#返回索引到的单词数据用于建立日期表
random_words = random_words_df[['单词']]#对列进行操作这里还是dataframe格式
random_words_lists = np.array(random_words).tolist()#注意这里的random_words_list每一个random_word都是单独的列表,迭代时需要[0]
for random_word in random_words_lists:
print('今日随机单词'.center(80,'='))
print(random_word[0])
#这里借助numpy将dataframe转换为list格式方便后面进行文件重组时间文件
#word_read_pro.py的最终目的就是提供80个随机单词,不具备判断能力,但是记录随机筛选的单词的索引
#在随后的返回函数中根据csv时间文件判断是否需要call_back
# random_words_lists = np.array(random_words).tolist()#注意这里的random_words_list每一个random_word都是单独的列表,迭代时需要[0]
temp_word_write_pro.py
暂时文件读写模块
主要用于将word中的单词数据转化为data日志的方式,方便后面的存储与数据处理。这一模块需要单独运行,可以在部署服务器之前运行一遍就好,当然还是要注意centos7的绝对路径的问题。
show me the code
# auther : keepython
import pandas as pd
import numpy as np
import random
file_name = '六级核心词汇表(EXCEL表格)'
word_file_path = '/word_recording_project/word/' + file_name+'.xls'
words = pd.read_excel(word_file_path,header=0)
words_index = words.index
words = words[['单词']]
print(len(np.array(words).tolist()))
words = np.array(words).tolist()#将所有单词转换为列索引,行索引转换为天数
print(len(words))
datas = {}
for word in words :
datas[word[0]] = {
"5min":0,
"30min":0,
'12hour':0,
'day1':0,
'day2':0,
'day4':0,
'day7':0,
'day15':0,
'time':'1111-11-11-11-11'
}
words_df = pd.DataFrame(data=datas)
print(words_df)
words_df.to_csv('/word_recording_project/data/word.csv')
# print(words_df)
every_day_count_pro.py
这一部分从标题来看就是用于对every_day_word中的文件与data中的日志文件配合计时并返回对应的文件路径用于后面的邮件发送调用。
import time
import datetime
import pandas as pd
import numpy as np
from word_read_project import every_day_word_path
from mail_send_project import mail_send_fuc
#函数功能:负责time时间的相减,并分别返回时间间隔时间为1day 2day 4day 7day 15day 的路径列表
def read_log_remind():
word_log_path = '/word_recording_project/data/word.csv'
word_log = pd.read_csv(word_log_path,index_col=0)
word_log = word_log.T
word_log = word_log[word_log.time != '1111-11-11-11-11'] # 提取word.csv文件中time所有不等于‘1111-11-11-11-11’的模块
#将矩阵转置方便使用index提取路径
time_stamp = time.strftime("%Y-%m-%d-%H-%M", time.localtime()).split('-')
log_times = np.array(word_log['time']).tolist()
today = datetime.datetime(int(time_stamp[0]),
int(time_stamp[1]),
int(time_stamp[2]),
int(time_stamp[3]),
int(time_stamp[4]))
#分别设置对应天数的路径列表
day_1_path = []
day_2_path = []
day_4_path = []
day_7_path = []
day_15_path = []
for log_time in log_times:
log_timed = log_time.split('-')
# print(log_timed)
last_day = datetime.datetime(
int(log_timed[0]),
int(log_timed[1]),
int(log_timed[2]),
int(log_timed[3]),
int(log_timed[4])
)
reduce = today - last_day
#用于判断天数
if reduce.days == 1:
path = '/word_recording_project/every_day_word/'+log_time+'.csv'
day_1_path.append(path)
elif reduce.days == 2:
path = '/word_recording_project/every_day_word/' + log_time+'.csv'
day_2_path.append(path)
elif reduce.days == 4:
path = '/word_recording_project/every_day_word/' + log_time+'.csv'
day_4_path.append(path)
elif reduce.days == 7:
path = '/word_recording_project/every_day_word/' + log_time+'.csv'
day_7_path.append(path)
elif reduce.days == 15:
path = '/word_recording_project/every_day_word/' + log_time+'.csv'
day_15_path.append(path)
#列表收集完路径后还需要去重
day_1_path = list(set(day_1_path))
day_2_path = list(set(day_2_path))
day_4_path = list(set(day_4_path))
day_7_path = list(set(day_7_path))
day_15_path = list(set(day_15_path))
return day_1_path,day_2_path,day_4_path,day_7_path,day_15_path
#负责当天的推进5 min 30 min 12小时
def today_word_count():
today_path = every_day_word_path
print('今日要推送的地址是: ',today_path)
time_stamp = time.strftime("%Y-%m-%d", time.localtime())
subject = '艾宾浩斯 '+time_stamp+' 第一次单词提醒'
mail_send_fuc(today_path,subject)
time.sleep(300)#5min提醒
mail_send_fuc(today_path,subject)
time.sleep(1500)#30min提醒
mail_send_fuc(today_path,subject)
time.sleep(41400)#12小时提醒
mail_send_fuc(today_path,subject)
mail_send_project.py
邮件发送,输入邮件主题和对应的附件路径直接发送,注意使用的时候修改一下对应的一些变量。
import smtplib
from email.header import Header
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
#从word.csv文件传入文件everyday文件路径就可以直接发送邮件
# everyday_file_path = '2020-02-02.csv'
#函数功能:传入附件路径,邮件的主题发送邮件并返回发送状态
def mail_send_fuc(everyday_file_path,subject):
message = MIMEMultipart()
msg_from = '***********' # 发送方邮箱地址。
password = '***************' # 发送方QQ邮箱授权码,不是QQ邮箱密码。
msg_to = '*************'
msg_to_1 = '******************' # 收件人邮箱地址。
message = MIMEMultipart()
message['From'] = msg_from # 发送者
message['To'] = msg_to # 接收者
# 邮件标题
message['Subject'] = Header(subject, 'utf-8')
# 邮件正文内容
message.attach(MIMEText('艾宾浩斯根据你的遗忘曲线提醒单词'.center(20,'+'), 'plain', 'utf-8'))
#打开文件
part = MIMEApplication(open(everyday_file_path, 'rb').read())
part.add_header('Content-Disposition', 'attachment', filename=everyday_file_path)
message.attach(part)#添加文件
try:
client = smtplib.SMTP_SSL('smtp.qq.com', smtplib.SMTP_SSL_PORT)
print("连接到邮件服务器成功")
client.login(msg_from, password)
print("登录成功")
client.sendmail(msg_from, msg_to, message.as_string())
print("发送成功")
except smtplib.SMTPException as e:
print("发送邮件异常")
finally:
client.quit()
# mail_send_fuc(everyday_file_path)
main_code.py
调用所有模块和函数,将之组合起来实现最终的功能。项目在调用的时候也只需要调用main_dode.py就可以了。
import pandas as pd
import numpy as np
import os
import time
import random
from every_day_count_pro import *
#总的执行函数包括写入word.csv日志的功能
if __name__ == '__main__':
day_1_paths, day_2_paths, day_4_paths, day_7_paths, day_15_paths = read_log_remind()
today_word_count()
time.sleep(3600)
#1小时后再复习昨天的知识
if len(day_1_paths) != False:
for day_1_path in day_1_paths:
subject = '1 天前的单词复习'.center(20,'=')
mail_send_fuc(day_1_path,subject)
time.sleep(900)
if len(day_2_paths) != False:
for day_2_path in day_2_paths:
subject = '2 天前的单词复习'.center(20,'=')
mail_send_fuc(day_2_path,subject)
time.sleep(900)
if len(day_4_paths) != False:
for day_4_path in day_4_paths:
subject = '4 天前的单词复习'.center(20,'=')
mail_send_fuc(day_4_path,subject)
time.sleep(900)
if len(day_7_paths) != False:
for day_7_path in day_7_paths:
subject = '4 天前的单词复习'.center(20,'=')
mail_send_fuc(day_7_path,subject)
time.sleep(900)
if len(day_15_paths) != False:
for day_15_path in day_15_paths:
subject = '15 天前的单词复习'.center(20,'=')
mail_send_fuc(day_15_path,subject)
项目到这里就算开发完成啦,注意这里面的dataframe数据的操作真的非常高效,但是坑也很多希望有需要的同学一定要认真看。┑( ̄Д  ̄)┍
服务器定时任务部署
这一部分一定要修改好代码里面对应的路径,还是那句话centos7里面的绝对路径的问题。
编辑crontab配置这一步详细解释可以看这里:
crontab -e
编写配置文件
当打开配置文件的时候,我们可以看到类似的配置代码。每一行都代表一个定时任务 , 我们要做的就是新添加一行配置代码。
重启服务
service crond restart
最终就完成啦
欢迎留言交流学习,有什么疑问也可以交流,如果聊的开心还可以多一个朋友。















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









