





zap日志框架-性能篇(3)
zap日志框架分了三篇来讲解:使用篇 ,源码篇,性能篇。
我们在github上可以看到如下测试结果:
msg+10个fields的情况
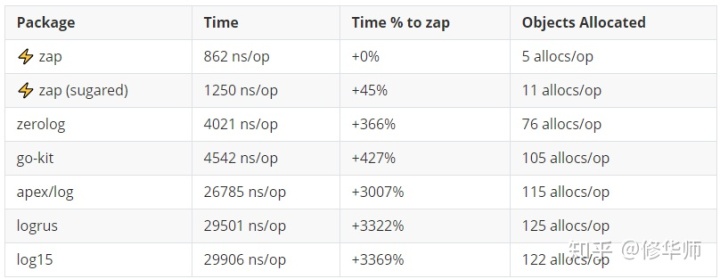
可以看到,在此基准测试下,zap是远远领先于其他的日志框架。那是什么原因让zap有如此优异的性能呢,我相信很多读者和我一样,按捺不住的想一探究竟。
对象池
pool能有效的减少Objects Allocated,减少GC。
CheckedEntry
CheckedEntry含有Entry,[]Core属性,每次打印日志都需要调用CheckedEntry的Write方法,因此使用的频率非常高
//获取并组装CheckedEntry 对象
func (ce *CheckedEntry) AddCore(ent Entry, core Core) *CheckedEntry {
if ce == nil {
ce = getCheckedEntry()
ce.Entry = ent
}
ce.cores = append(ce.cores, core)
return ce
}
//对Pool中获取CheckedEntry对象
func getCheckedEntry() *CheckedEntry {
ce := _cePool.Get().(*CheckedEntry)
ce.reset()
return ce
}
以下对象池的定义,需要注意的是:zap预分配了4个长度的Core空间,面对Core数量的不确定的性,可以有效的防止slice的内存复制
var (
_cePool = sync.Pool{New: func() interface{} {
return &CheckedEntry{
cores: make([]Core, 4),
}
}}
)
Buffer
Buffer是一个byte slice封装。还自带一个Pool,用于Free(内部也是调用的对象池的Put回收操作)。
type Buffer struct {
bs []byte
pool Pool
}
type Pool struct {
p *sync.Pool
}
// NewPool constructs a new Pool.
func NewPool() Pool {
return Pool{p: &sync.Pool{
New: func() interface{} {
return &Buffer{bs: make([]byte, 0, _size)}
},
}}
}
Buffer在zap中有两处用到:
一个是EntryCaller,用于输出调用者的path信息;
一个是jsonEncoder,用于日志编码,输出json或者console个数的日志
上面的两个Pool都和输出日志有关,所以说zap在输出日志的时候,做到了尽量减少对象分配,这一点非常值得我们借鉴,我们是否也可以在高使用频率的对象上使用Pool来提高效率,减少GC,进而尽量减少STW的频率和时间
encoder
如果要讲对象编码成json格式,最容易想到的就是:json.Marshal(v interface{}),这是go库自带的,使用起来非常简单,但通过源码发现,json的编码都是通过反射来实现的,如下:
func (e *encodeState) marshal(v interface{}, opts encOpts) (err error) {
defer func() {
if r := recover(); r != nil {
if je, ok := r.(jsonError); ok {
err = je.error
} else {
panic(r)
}
}
}()
e.reflectValue(reflect.ValueOf(v), opts)
return nil
}
反射虽然好用,但是对效率不太友好,这就是zap为什么要自建encoder原因,那我们来看下encoder的代码片段,看看encoder是怎么实现json的拼装的
//根据Field的类型,做对应的Add操作,这里并不是通过反射来实现的
func (f Field) AddTo(enc ObjectEncoder) {
var err error
switch f.Type {
case ArrayMarshalerType:
err = enc.AddArray(f.Key, f.Interface.(ArrayMarshaler))
case ObjectMarshalerType:
err = enc.AddObject(f.Key, f.Interface.(ObjectMarshaler))
case BinaryType:
enc.AddBinary(f.Key, f.Interface.([]byte))
case BoolType:
enc.AddBool(f.Key, f.Integer == 1)
case ByteStringType:
enc.AddByteString(f.Key, f.Interface.([]byte))
……
}
func (enc *jsonEncoder) AddBinary(key string, val []byte) {
enc.AddString(key, base64.StdEncoding.EncodeToString(val))
}
func (enc *jsonEncoder) AddString(key, val string) {
enc.addKey(key)
enc.AppendString(val)
}
//拼接json的Key
func (enc *jsonEncoder) addKey(key string) {
enc.addElementSeparator()
enc.buf.AppendByte('"')
enc.safeAddString(key)
enc.buf.AppendByte('"')
enc.buf.AppendByte(':')
if enc.spaced {
enc.buf.AppendByte(' ')
}
}
//拼接json的value
func (enc *jsonEncoder) AppendString(val string) {
enc.addElementSeparator()
enc.buf.AppendByte('"')
enc.safeAddString(val)
enc.buf.AppendByte('"')
}
写时复制
写时复制,简单的理解就是:在读的时候,多个对象共享一个内存区,只有在写的时候,才会新开辟一个内存空间,赋予要写的对象,这样就不会与原来的对象发生冲突。
如果不采用写时复制,就需要加锁,加锁相对于重新分配内存,更加损耗性能。我们看看zap有哪些地方做了写时复制:统一用的clone方法
加入Option属性,复制log对象
func (log *Logger) WithOptions(opts ...Option) *Logger {
c := log.clone()
for _, opt := range opts {
opt.apply(c)
}
return c
}加入Field对象,复制log对象
func (log *Logger) With(fields ...Field) *Logger {
if len(fields) == 0 {
return log
}
l := log.clone()
l.core = l.core.With(fields)
return l
}
加入Field对象,复制Core对象
func (c *ioCore) With(fields []Field) Core {
clone := c.clone()
addFields(clone.enc, fields)
return clone
}
复制Encoder对象
func (c *ioCore) clone() *ioCore {
return &ioCore{
LevelEnabler: c.LevelEnabler,
enc: c.enc.Clone(),
out: c.out,
}
}
就不一一列举了,我们可以自行进行全局搜索clone()方法,找到结果
结语
zap 在性能上做了非常精细的考量,有如下方面
- 对象池,对象复用
- 自建encoder
- 写时复制,避免加锁
不仅如此,zap的解耦设计也值得我们借鉴,具体可以参考 源码篇
相关阅读
zap日志框架-使用篇(1)
zap日志框架-源码篇(2)















 2854
2854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









