






目录:
一、得到要爬取的url
二、拿到网页源码
三、得到各省份分数链接
上一章我们讨论了xpath的简单使用,这次我们就来实际应用一下xpath,看看它使用有多方便。
最近高考结束,各省分数线也陆续公布了,咱们今天就来爬取各省的高考分数线。看看每个省份的学生成绩如何。
一、得到要爬取的url
url地址如下:
url = 'https://gaokao.eol.cn/news/'二、拿到网页源码
进行简单的get请求,唯一需要注意的是要带上请求头。还要注意乱码的问题。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
shengfen = response.text三、得到各省份分数链接
通过网页解析,其中的各省分数线链接均在网页源码中,这次使用xpath的方法获取到。
先将字符串转化为Element对象。
element = etree.HTML(shengfen)
可以发现,信息是在一个class属性为list的大标签下,再往下一级的class属性为fline的标签下的a标签。这样可写出代码如下:
links = element.xpath('//fline/a/@href')
content = element.xpath('//fline/a/text()')以下是运行后获取到的部分结果:
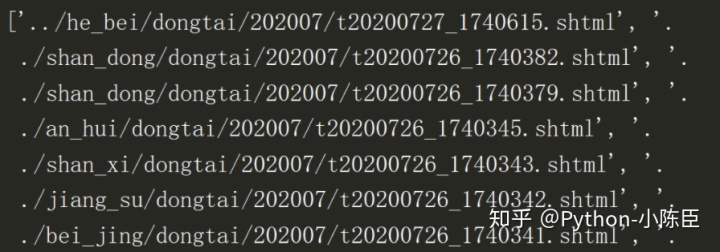

我们发现各省的链接均不完整,需要进行相应的修改。
可以得知,下面才是完整的链接:
https://gaokao.eol.cn/shan_dong/dongtai/202007/t20200726_1740379.shtml我们需要将每条链接前面的点替换为https://gaokao.eol.cn再加上后面的部分,这一步可以使用正则表达式的替换功能。在前面导入re模块。
for i in links:
links_xiugai = re.sub('..|.','https://gaokao.eol.cn',i)
print(links_xiugai)现在各省url都修改完成了,我们就来进行各自的请求。以山东省分数线为例,进行分析。

经过结构分析,发现文本信息都在p标签中,这样可写出如下代码:
shandongsheng_url = 'https://gaokao.eol.cn/shan_dong/dongtai/202007/t20200726_1740379.shtml'
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
# 请求url
res = requests.get(shandongsheng_url,headers=header)
res.encoding = 'utf-8'
shandong = res.text
# 获取文本信息
element = etree.HTML(shandong)
biaoti = element.xpath('//p[@style="text-align: center;"]/b/text()')
wenben = element.xpath('//div[@class="TRS_Editor"]/p/text()')
print(biaoti)
print(wenben)我们得到了山东省的分数情况如下:
标题

文本信息

至此,我们的高考分数线信息就爬取到了,至于后面的数据统计分析,后面再接着聊。用xpath方法获取信息是不是很方便呢?我觉得这比正则表达式好用多了,只需要把文档当成一个结构树就行了,按照结构来找数据。
第一篇:Python入门要点,环境搭建、安装配置、第三方库导入方法详细过程!建议收藏
第二篇:Python爬虫新手入门(一)了解爬虫!
第三篇:Python爬虫新手入门(二)爬虫的请求模块!
第四篇:Python爬虫新手入门(三)爬虫之正则表达式介绍!
第五篇:Python爬虫新手入门(四)爬虫之正则表达式实战(爬取图片)
第六篇:Python爬虫新手入门(五)爬虫之xpath与lxml库的使用!
最近在知乎创建了一个新的Python技术圈子,在里面每天都会分享好玩有趣的Python知识,你如果对Python这门技术感兴趣的可以加入哦!交个朋友
Python技术 - 知乎www.zhihu.com















 6865
6865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









