







随着高考分数公布,填报大学和专业成了各位家长最重要的事情,这两天有好几位亲戚朋友咨询专业填报的事情,发现了一个网站内容不错,提供了各个学校各个专业的最低分数线和最低录取名次,网站链接在这里,这个就是计算机类专业在浙江招生的情况,专业可以换掉。
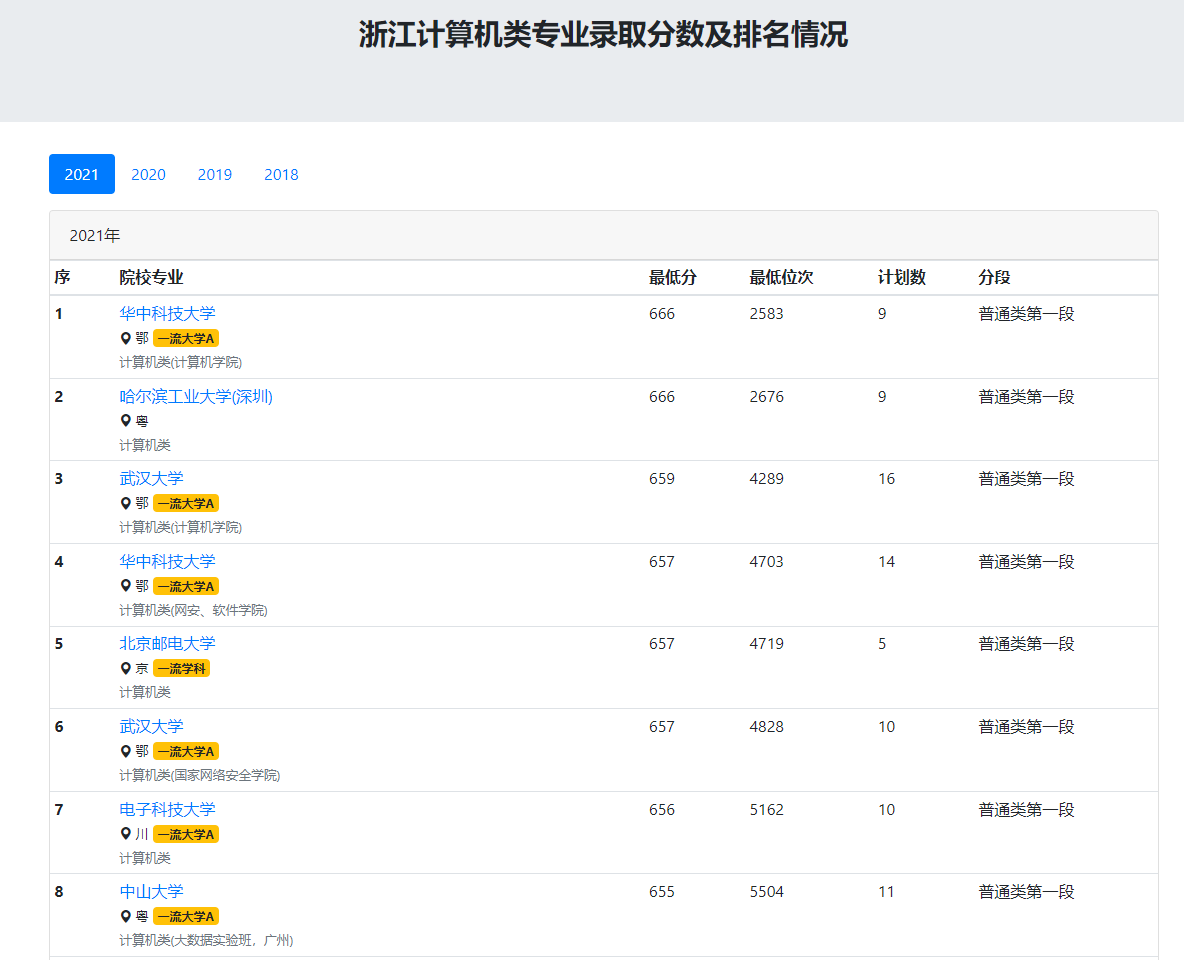
这个页面的内容还是很简单的,但是他的分页(不同年份)通过get请求没法体现,应该是用前后端分离的模式开发的,所以通过网页请求来爬虫可能不太容易实现,所以使用了selenium进行自动化提取,并自动化跳转页面。
代码如下:
from selenium import webdriver
import time
import pandas as pd
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(r'C:\Users\HP\Downloads\chromedriver_win32\chromedriver.exe')
#time.sleep(5)
driver.get("https://www.zjut.cc/zhuanye/fsx-0809-33.html")
# time.sleep(15)
# url = driver.find_element_by_xpath("/html/body/div/div/section/main/div/div[4]/div/div[1]/div/div/div[3]/table/tbody/tr[1]")
# url = driver.find_element_by_xpath("/html/body/div/div/section/main/div/div[4]/div/div[1]/div/div/div[3]/table/tbody/tr[1]/td[2]/div")
# scqy = driver.find_element_by_xpath("/html/body/div/div/section/main/div/div[4]/div/div[1]/div/div/div[3]/table/tbody/tr[1]/td[2]/div").text
vehicles = []
res = []
for j in range(4):
schools = []
if j < 2:
for i in range(100):
series = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[1]/div/div[2]/table/tbody/tr[{}]/th".format(1+i)).text
school_name = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[1]/div/div[2]/table/tbody/tr[{}]/td[1]/a".format(1+i)).text
major = driver.find_element_by_xpath('//*[@id="pills-2021"]/div/div[2]/table/tbody/tr[{}]/td[1]/small[2]'.format(1+i)).text
min_score = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[1]/div/div[2]/table/tbody/tr[{}]/td[2]".format(1+i)).text
min_rank = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[1]/div/div[2]/table/tbody/tr[{}]/td[3]".format(1+i)).text
plan = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[1]/div/div[2]/table/tbody/tr[{}]/td[4]".format(1+i)).text
schools.append([series, school_name, major, min_score, min_rank, plan])
else:
for i in range(100):
series = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[3]/div/div[2]/table/tbody/tr[{}]/th".format(1+i)).text
school_name = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[3]/div/div[2]/table/tbody/tr[{}]/td[1]/a".format(1+i)).text
major = driver.find_element_by_xpath('//*[@id="pills-2021"]/div/div[2]/table/tbody/tr[{}]/td[1]/small[2]'.format(1+i)).text
min_score = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[3]/div/div[2]/table/tbody/tr[{}]/td[2]".format(1+i)).text
min_rank = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[3]/div/div[2]/table/tbody/tr[{}]/td[3]".format(1+i)).text
plan = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/div/div[3]/div/div[2]/table/tbody/tr[{}]/td[4]".format(1+i)).text
schools.append([series, school_name, major, min_score, min_rank, plan])
df = pd.DataFrame(schools, columns=['排序', '院校', '专业', '最低分', '最低排名', '计划招录人数'])
df.to_excel("%d.xlsx" % (-j + 2021), index=False)
# res.append(schools)
a = driver.find_element_by_xpath("/html/body/div[3]/div[1]/div/ul/li[{}]/a".format(1+j))
driver.execute_script("arguments[0].click();", a)
time.sleep(3)
可以看出来,绝大多数用的xpath,但也有一些细节需要解释,等空了再来解释。















 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











