





作者:黄天元,复旦大学博士在读,热爱数据科学与开源工具(R),致力于利用数据科学迅速积累行业经验优势和科学知识发现,涉猎内容包括但不限于信息计量、机器学习、数据可视化、应用统计建模、知识图谱等,著有《R语言数据高效处理指南》(《R语言数据高效处理指南》(黄天元)【摘要 书评 试读】- 京东图书,《R语言数据高效处理指南》(黄天元)【简介_书评_在线阅读】 - 当当图书)。知乎专栏:R语言数据挖掘。邮箱:huang.tian-yuan@qq.com.欢迎合作交流。
ARIMA,全称Autoregressive Integrated Moving Average model,差分整合移动平均自回归模型,或称整合移动平均自回归模型,时间序列分析经典预测方法之一,涉及平稳、差分、自回归、滑动平均等多个基本概念,感兴趣请移步Chapter 8 ARIMA models | Forecasting: Principles and Practice。这里仅对预测流程的实现进行讲解,这也并不是一个简单的过程,包括:
1、可视化观察看是否有异常值;
2、如果需要的话,对数据进行转化,让时间序列平稳;
3、如果仍然不平稳,使用差分法(一阶差分、二阶差分...)让其平稳;
4、差分后,用ACF/PACF图对其进行定阶;
5、选出一系列的模型,然后使用AICc等标准对其效果进行评估,选出最优模型;
6、对模型进行残差分析,查看残差是否为白噪音;
7、如果是白噪音,可以结束建模过程,利用模型进行预测。
在8.7 ARIMA modelling in R | Forecasting: Principles and Practice中提供了一个流程图供参考:
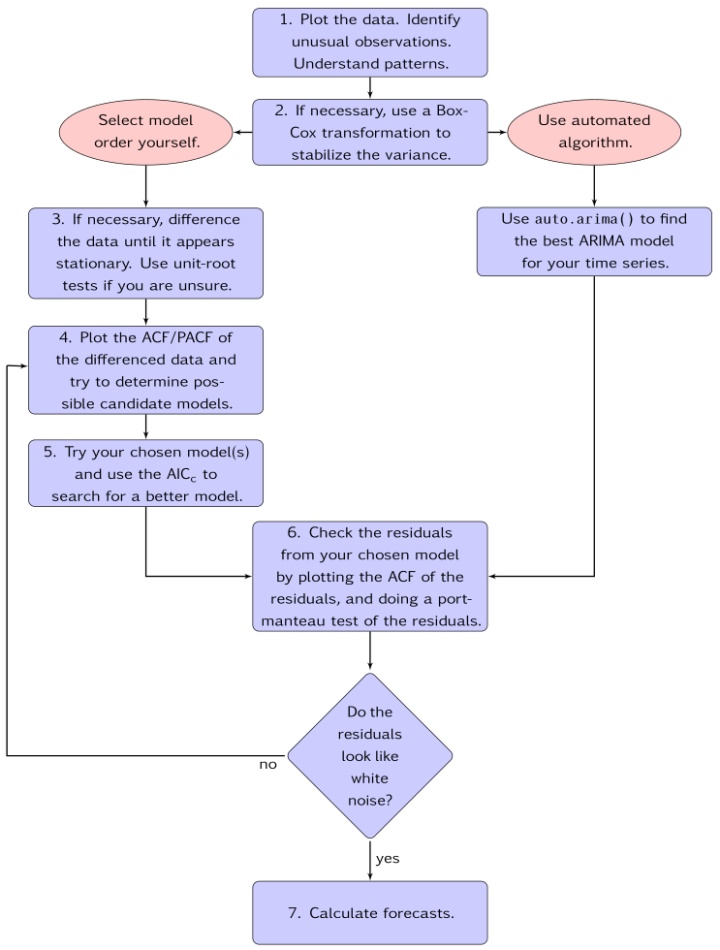
千言万语汇成一句话,使用auto.arima。尽管自动化工具总是有一定的风险,但是其实人为定阶不仅费时费力,也容易引入人为误差。下面给出一个实际的例子:
library(fpp2)
cement <- window(qcement, start=1988)
train <- window(cement, end=c(2007,4))
(fit.arima <- auto.arima(train))
#> Series: train
#> ARIMA(1,0,1)(2,1,1)[4] with drift
#>
#> Coefficients:
#> ar1 ma1 sar1 sar2 sma1 drift
#> 0.889 -0.237 0.081 -0.235 -0.898 0.010
#> s.e. 0.084 0.133 0.157 0.139 0.178 0.003
#>
#> sigma^2 estimated as 0.0115: log likelihood=61.47
#> AIC=-109 AICc=-107.3 BIC=-92.63
checkresiduals(fit.arima)
#>
#> Ljung-Box test
#>
#> data: Residuals from ARIMA(1,0,1)(2,1,1)[4] with drift
#> Q* = 3.3, df = 3, p-value = 0.3
#>
#> Model df: 6. Total lags used: 9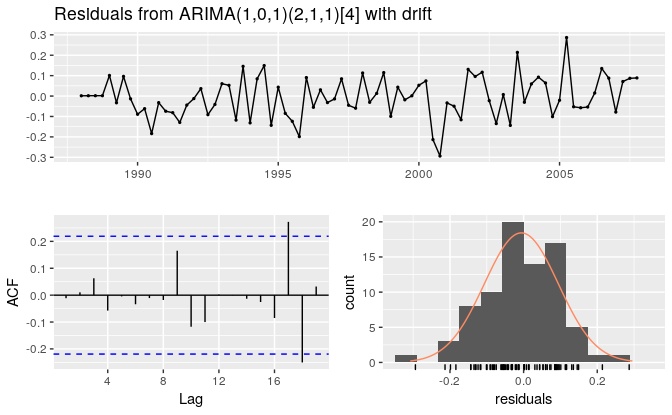
# 进行预测
a1 <- fit.arima %>% forecast(h = 4*(2013-2007)+1) %>%
accuracy(qcement)
a1[,c("RMSE","MAE","MAPE","MASE")]
#> RMSE MAE MAPE MASE
#> Training set 0.1001 0.07989 4.372 0.5458
#> Test set 0.1996 0.16882 7.719 1.1534无论是拟合、残差诊断、模型预测还是效果评估,基本都是一步到位。ARIMA和ETS都是时间序列分析中的有效工具,在实践中经常将两者进行比较。
这里基本把ARIMA的黑箱使用模式介绍了一下,但是要活的具体的模型参数,还需要对原理进行一定的了解(参考Chapter 8 ARIMA models | Forecasting: Principles and Practice中的各个公式并了解参数的含义)。非常感谢forecast包的作者,把auto.arima带给了我们,让很多需要一步一步人工验证选择的东西实现了自动化,相信这会是未来应用统计学的一大趋势。














 1672
1672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









