






这篇文章发自2020年的ICML,脑洞很大!一行代码??!
Flooding
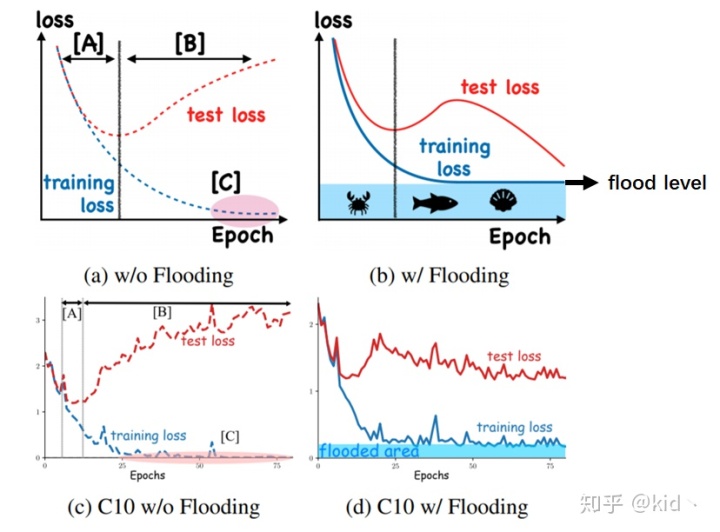
上图可以大致描述整篇文章干了一件啥事。先看左边一列,是一个正常的训练过程,对于阶段A,随着training loss的降低,test loss也会 跟着降低;但是到阶段B后,我们继续在训练集上训练,会让test loss上升。
右边一列是本文提出的 flooding 方法,当training loss大于一个阈值(flood level)时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行“random walk”,并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent!
一个简单的理解是,这和early stop类的方法类似,防止参数被优化到一个不好的极小值出不来。

本文也是十分的“嚣张”,直接在文章introduction部分贴出了pytorch代码,仅仅增加了一行代码,真是好气!整个的损失从
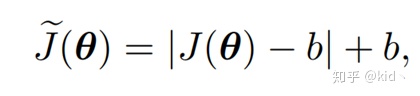
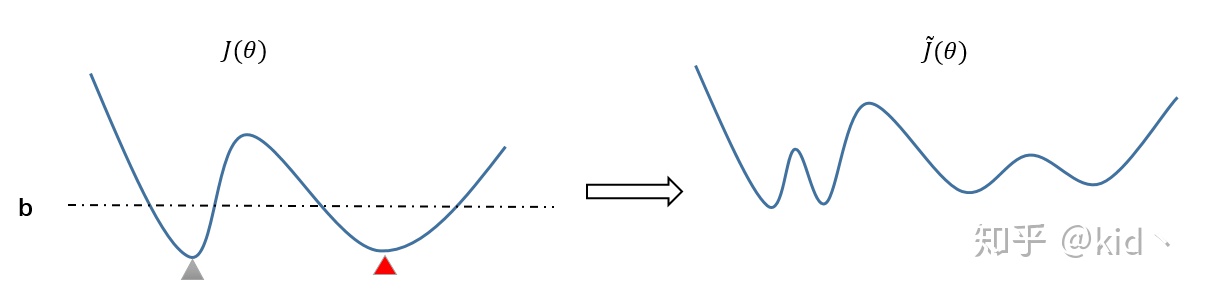
接下来是自己的一些思考,假设我们的损失
另外,假设虚线代表
可以发现,整个目标多了很多极小值,二维平面的情况则是多了一圈极小值,是否可以说右边的损失要比左边的损失更加“平坦”,然后泛化能力会越好。

接下来是我的一些分析,首先是前面提到的灰色三角形和红色三角形两个极小值点,分别由上述两个损失代替,右边的损失比左边的损失看起来更“平坦”。
我们从对抗样本的角度来理解,蓝色的笑脸代表正常被分对的样本,对抗样本是通过优化样本使得损失变大,从而让模型对该样本分错(黄色的难过脸)。
直观来看,越平坦的损失会让对抗样本的生成越困难(
其实,一般的鲁棒性和泛化性也如此,一般的鲁棒性是指模型对样本进行一些诸如高斯模糊、椒盐噪声等等鲁棒。
换句话说,对样本进行一定的扰动(
换句话说,对于一个未见过的样本
最后我们再来从svm的角度来思考这个问题。对于一个线性可分的二分类问题,有无数条分类面能将其分开,而svm是去挑选能满足“最大间隔”的分类器。
从另一个角度来理解是,越平坦的损失,是不是能越尽可能的将不同类给分开,因为样本进行些许扰动,损失的变化不会太大,相当于进行细微扰动后的样本不会跑到分类面的另一边去!
上述的分析存在着一个问题是,横坐标应该是参数
感谢关注和点赞,欢迎分享给更多人~
文章转载自知乎@ Kid,已授权。
温馨提示:新智元主页新增“实用贴合集”,含AI技术教程、开源工具、书籍及视频下载等,欢迎大家参与。














 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









