







线性表
我们可以这样定义线性表的抽象类,类中的每个函数都是纯虚函数,在实现数据结构时需要去完成每一个纯虚函数。
- 线性表的抽象类少了创建操作,因为这可以用每个类的构造函数来完成。
- 线性表的操作没有修改某元素的值。
- 线性表抽象类用了虚析构函数,为了防止内存泄漏,把申请的内存由具体的实现类析构掉。
template <class elemType>
class list {
public:
// 清除
virtual void clear() = 0;
// 长度
virtual int length() const = 0;
// 插入
virtual void insert(int i, const elemType &x) = 0;
// 删除
virtual void remove(int i) = 0;
// 搜索
virtual int search(const elemType &x) const = 0;
// 访问
virtual elemType visit(int i) const = 0;
// 遍历
virtual void traverse() const = 0;
// 析构
virtual ~list() {};
};
顺序表
线性表的实现
由于逻辑顺序和物理顺序保持了一致,所以定位访问性能高
适合于,静态的线性访问的线性表。
template <class elemType>
class seqList: public list<elemType>
{
private:
elemType *data;
int currentLength;
int maxSize;
void doubleSpace();
public:
seqList(int initSize = 10);
~seqList(){delete []data};
void clear(){currentLength=0;}
}
// insert
template <class elemType>
void seqList<elemType>::insert(int i, const elemType &x){
if(currentLength == maxSize)
doubleSpace();
for(int j = currentLength; j>i; j--)
data[j] = data[j-1];
data[i] = x;
++currentLength;
}
// doubleSpace
template <class elemType>
void seqList<elemType>::doubleSpace() {
// 保存指向原来空间的指针
elemType *tmp = data;
// 重新申请空间
maxSize *= 2;
data = new elemType[maxSize];
// 拷贝原有数据
for (int i = 0; i < currentLength; ++i)
data[i] = tmp[i];
// 清除原来申请的空间
delete [] tmp;
}
// delete
template <class elemType>
void seqList<elemType>::remove(int i) {
// 后面所有元素前移,表长减1
for (int j = i; j < currentLength - 1; j++)
data[j] = data[j+1] ;
--currentLength;
}
单链表
为了实现查找链表长度,定义了currnetLength;
struct / class :struct的成员变量默认都是共有的,class相反;
在sLinkList的成员变量定义中,定义了一个struct的node节点,因为成员变量是私有的node不会被访问到;
node定义中,初始化了head节点。
单链表有一个head头节点,用来指向第一个元素;
clear():
p,q两个指针,删除之前将当前节点的 next赋给q,如果没有next就赋q为Null,并删除内容,直到p也为null。
insert():
利用私有的成员函数move(i-1)找到前一个元素的地址,然后 pos->next = new node(x, pos->next);
move():
双链表
每个元素记住了前后两个元素的位置;定义了head和tail节点
insert():
先找到要插入位置的元素,move(i);
new node()会自动创建head,tmp = new node(x,pos->head, pos);
pos->prev->next = tmp;
pos->prev = tmp;
remove():
单双链表的删除的时间复杂度?
栈
可以看成是特殊的线性表;
规定只能在栈顶删除,
创建一个栈,create();
push() pop删除栈顶元素 inEmpty() top()查看栈顶;
顺序栈
连续空间栈,0为栈底,空栈top_p=-1;
链接栈
由于栈的操作都是在栈顶进行的,因此用单链表就足够了,而且不需要头结点,因为对栈来讲只需要考虑栈顶元素的插入删除。从栈的基本运算的实现方便性考虑,可将单链表的头指针指向栈顶。
所有的操作都在栈顶,所以O(1);
队列
先进先出,没啥好说的
顺序队列
循环队列
依旧一个front和一个rear,牺牲一个单元规定front指向的单元不能存储队列元素,队列满的条件是:(rear+1)%MaxSize == front。
链接队列
- 采用不带头结点的单链表
- 单链表的表头作为队头,单链表的表尾作为队尾
- 同时记录头尾结点的位置。
字符串
将每个 a i a_i ai 看成一个元素,则字符串可以看成一个线性表。
字符串存储
-
顺序存储
-
用
字符数组
存储字符串。
- C语言的处理方式:固定大小的数组(可以调用cstring库,处理字符串)
- C++的处理方式:动态改变数组大小(使用string类)
-
缺点:插入子串、删除子串的时间性能差。
-
-
链接存储
-
用
单链表
存储字符串。
- 缺点:空间问题,1个字符1个字节,1个指针可能要占4个字节
-
用块状链表存储字符串。
-
块状链表的概念和操作
概念: 块状链表的每个结点存放字符串中一段连续的字符,而不是单个字符。

- 优点:提高了空间的利用率
- 缺点:插入和删除时会引起数据的大量移动
- 改进方法:允许节点有一定的空闲空间(空间换时间)
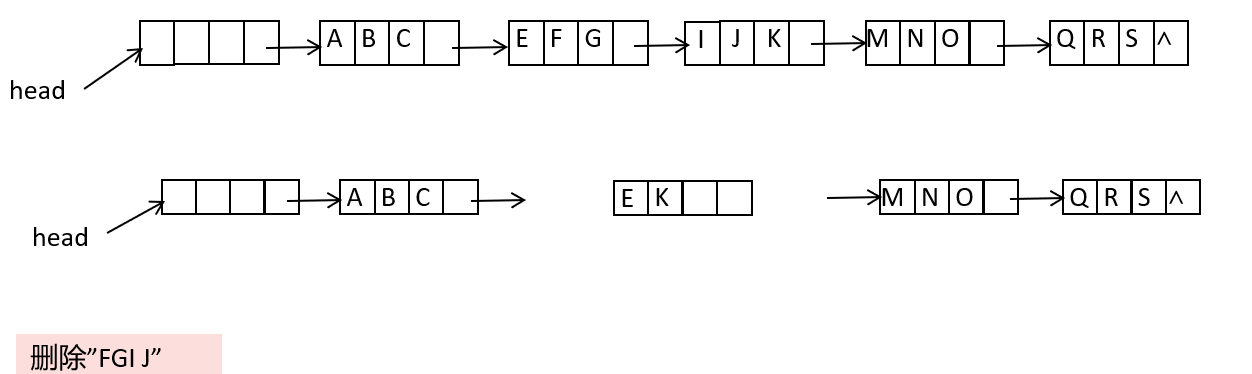
块状链表删除:
- 分裂起始和终止结点
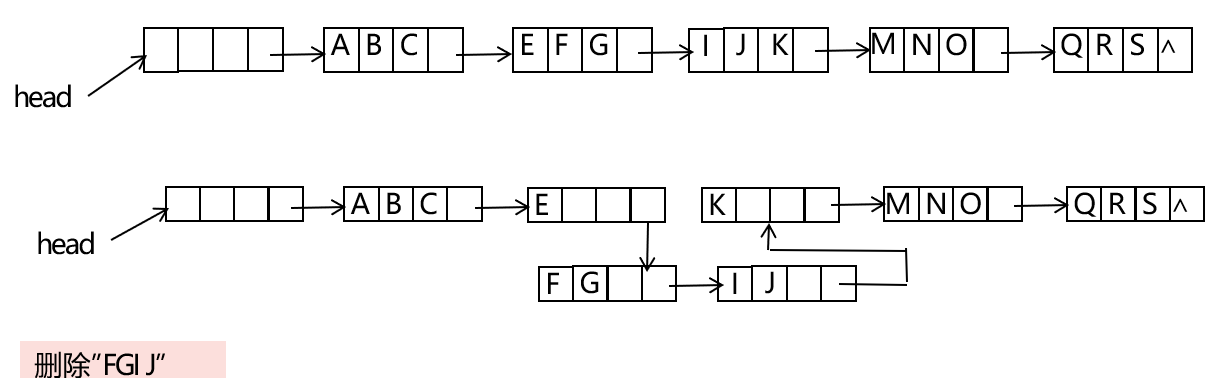
- 删除中间结点
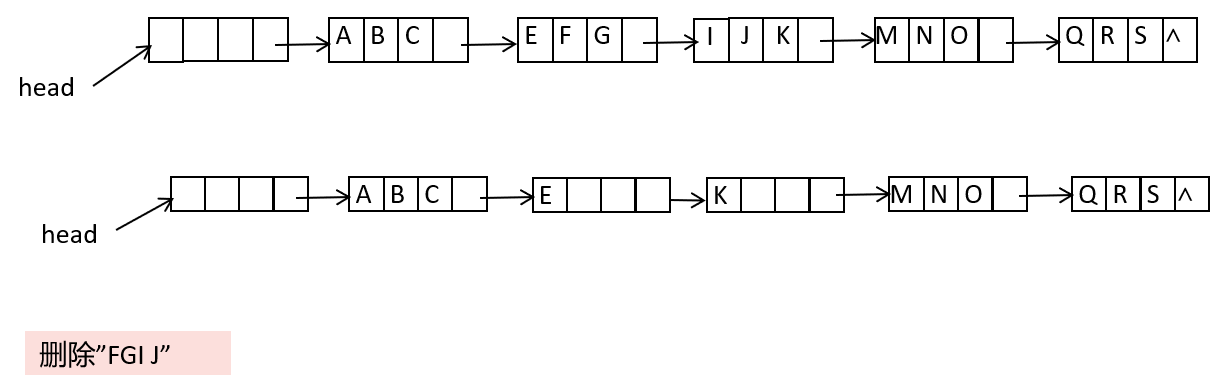
- 归并起始和终止结点
块状链表插入:
- 分裂节点
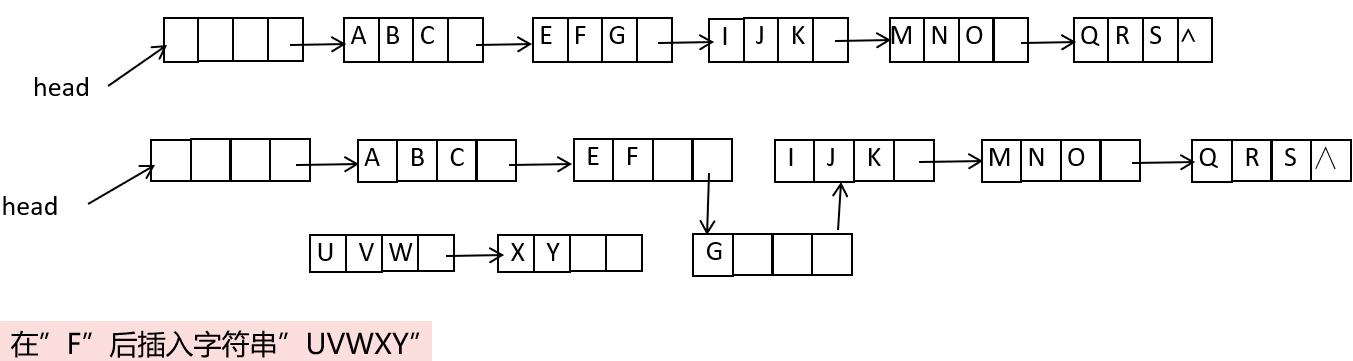
- 插入子串
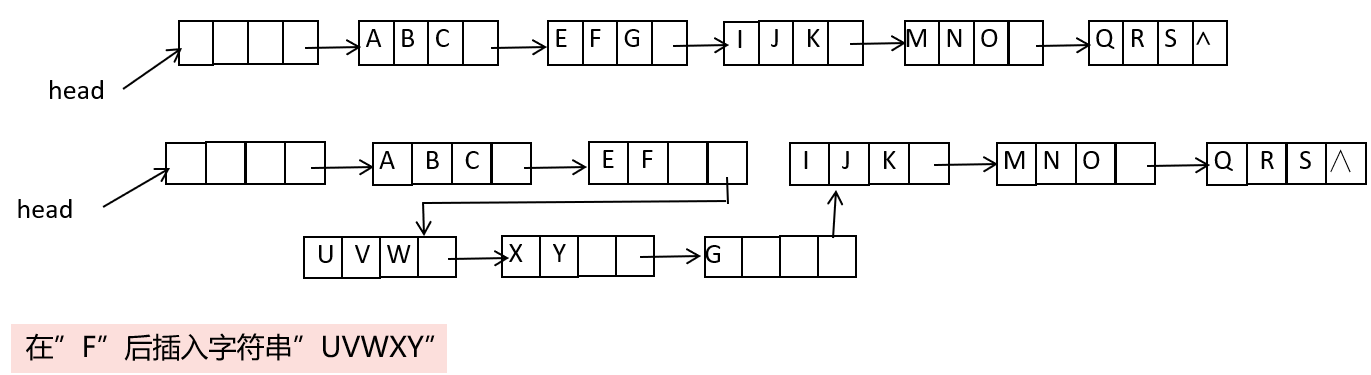
- 归并结点
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









