







梁敬彬梁敬弘兄弟出品
引言
DeepSeek的横空出世引爆国内大模型热潮,但乱象也随之浮现。
老胡:自从采纳了两位老师的建议,引入大模型技术后,我们团队的编程和运维效率就得到大幅提升,工作变得轻松多了(详见链接:《A+B=C》,《DBA—>DBA²》,《AI✖️数据= ∞》 )。但最近也有烦心事,家中孩子即将高考,数学成绩不佳,让我有些焦虑。
小涂:您在工作中运用AI得心应手,为什么不试着在孩子的教育上也用用呢?现在网上很多自媒体都在说,DeepSeek的能力远超学校老师,能在高考各科中取得满分。甚至有人说教育界要变天了,只要孩子们跟着DeepSeek学,人人都能考上清华北大。老胡,您得抓紧机会啊。

⓵全军覆没——大模型征战高考数学卷
弘老师:一个月前,我刚用大模型测试了2024年的高考数学I卷,我让DeepSeek、通义千问、豆包、Kimi、文心一言、GPT-o3、Claude-3.5-Sonnet这七款大模型分别参与解答,你们猜结果如何?
小涂:全部满分?
弘老师:全军覆没!表现最好的大模型离及格线还差十多分,还没考生的平均分高。

小涂:这么差?这跟我们看到的信息差距也太大了!
彬老师:很惊讶吧?你们可以自己试试,就会发现弘老师所言不虚。现在很多自媒体为了吸引眼球、博取流量,往往未经验证就急于追逐热点,发表意见,导致以讹传讹,误导大众。有趣的是,如果你问这些大模型考2024年数学高考卷能考多少分时,它们大多觉得自己能拿135分以上。下图中DeepSeek对高考数学各题型分数比例显然是错误,一般人就难以识别出来。
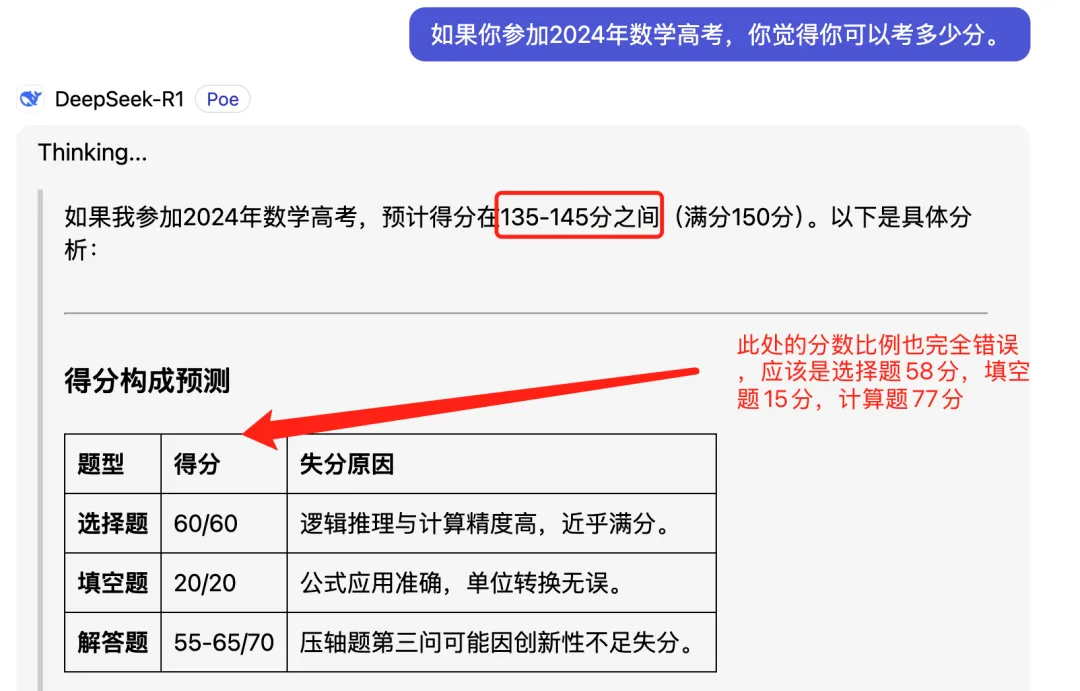
有的甚至认为自己能拿满分。总之,个个自信满满。
老胡:哈,AI们自我感觉这么好,看来这种自信也在以讹传讹上助推波助澜了,真是不可思议!
弘老师:更不可思议的是,一个月前的测试结果和今天的抽样测试相比,DeepSeek的准确率突然暴涨,已经接近满分了。不过,其他大模型的表现依然很糟。
老胡:为啥?DeepSeek忽然变聪明了?
弘老师:这应该是因为DeepSeek依据2024系列高考题,对模型进行了微调。不过,当我对题目稍做调整后,就会发现DeepSeek又开始出错了。
小涂:这么神奇,说明什么?DeepSeek并没有真正的掌握,只是记住了答案?
弘老师:大模型“记住答案”其实就是更新参数的过程,你这么理解也算对。斯坦福大学曾发表了相关论文《Putnam-AXIOM: A Functional and Static Benchmark for Measuring Higher Level Mathematical Reasoning》,指出,当题目稍作变换,准确率则会大幅下降。有兴趣的朋友可以下载阅读,深入了解。

小涂:啊,水这么深啊!
彬老师:其实,不止是高考,就连小学3年级以下的奥数题,各大模型的正确率也基本只能维持在50%左右,大家可以自行验证。但是你看下图,一位主播正眉飞色舞地分享如何用DeepsSeek教孩子学数学,还让DeepsSeek来出相似题目来考孩子,这样做,瞎出题的概率极高,很可能适得其反。

弘老师:或许,未来DeepSeek真可以达到数学无所不知的水平,但至少当下是不行的。这里需要引起注意的是,为什么错误认知可以广泛传播?本质上是因为大多数人无法判断真伪,就好比这位主播,如果她是一位数学老师,或许很快就会发现大模型解题中存在的错误了。
小涂:啊…我也刷到过大量类似这样的视频啊,而且我还真信了,以后我再也不用DeepSeek了。
彬老师:千万不要从一个极端到另一个极端。从目前来看,至少对于语文、英语、历史等文科类知识而言,大模型还是非常强的。当然,正确的问法也能更容易得到正确答案,这一点后续可以专门展开来说。
现如今,多数人对AI大模型的认知不足,仍然以高考数学为例,我来考考大家,如果用同一款大模型多次测试同一道数学题,你们觉得每次解题的答案会保持一致吗?
老胡:肯定一致啊,不然岂不是一会儿对一会儿错?
弘老师:其实未必,真可能时对时错,这取决于三大因素。
小涂:哪三大因素?
未完待续…
警惕!对AI大模型的错误认知正在误导你⓶三大因素——保障模型推理质量的关键
公众号:收获不止数据库
系列回顾



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











