







1. 回顾
话说L老师坐高铁去北京参加DTCC大会,不经意间推动了12306车内换座业务上线后(参考链接:12306业务系统升级也能被普通人推动?),收到了许多朋友的留言。有人告诉我,他们切身体验到了该业务带来的便利,如下。

还有人告知我,人民日报和首都之窗等许多官媒也都发出相关新闻。
这些留言中,最技术的是来自我远在加拿大的好友,世界顶尖数据库开发专家newkid。他提出了一个有趣又实用的话题:车内换座如何实现最优分配,确保乘客在旅途中换座次数最少。为此我们在ITPUB上开了技术贴。
一番思考后,我大致明白如何实现,正准备去论坛分享思路,却发现newkid不仅写出了解题思路,连代码也一并完成了,高手就是高手!
接下来本文将分析最优换座的需求和实现逻辑,并给大家带来newkid的精妙SQL!
2. 最少换座次数的需求分析
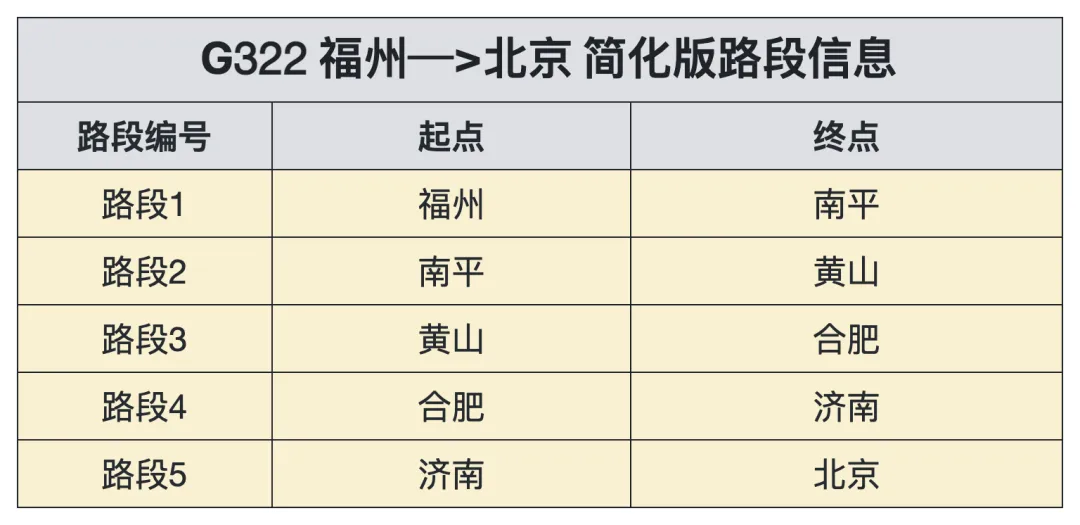
如何能使换座的次数最少?还是以福州到北京为例,在简化为仅有五个路段的情况下,需要找到最少换座次数的方案。以下是各个路段的信息。
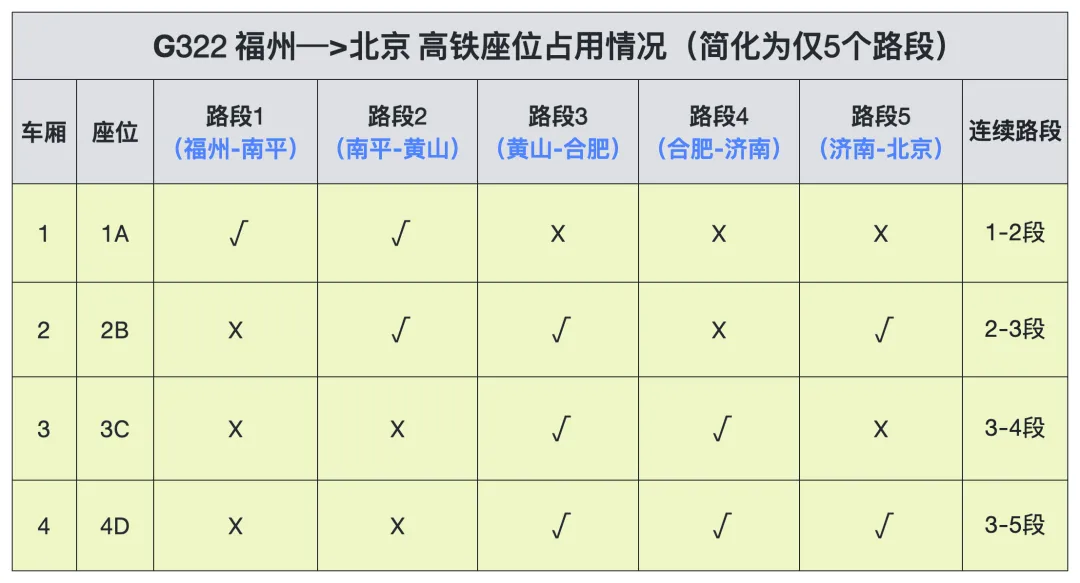
建立TRAIN_SEATS表,构造数据,插入四个座位(1车1A,2车2B,3车3C,4车4D)在五个路段(1,2,3,4,5)的记录座位被占用情况(AVAILABLE为可用,OCCUPIED为被占用),具体建表及构造数据如下。
CREATE TABLE TRAIN_SEATS (
SEAT_ID NUMBER PRIMARY KEY,
TRAIN_ID VARCHAR2(10),
CAR_NO NUMBER,
SEAT_NO VARCHAR2(3),
SEGMENT NUMBER,
STATUS VARCHAR2(10)
);
INSERT INTO TRAIN_SEATS VALUES (1, 'G322', 1, '1A', 1, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (2, 'G322', 1, '1A', 2, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (3, 'G322', 1, '1A', 3, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (4, 'G322', 1, '1A', 4, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (5, 'G322', 1, '1A', 5, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (6, 'G322', 2, '2B', 1, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (7, 'G322', 2, '2B', 2, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (8, 'G322', 2, '2B', 3, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (9, 'G322', 2, '2B', 4, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (10, 'G322', 2, '2B', 5, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (11, 'G322', 3, '3C', 1, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (12, 'G322', 3, '3C', 2, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (13, 'G322', 3, '3C', 3, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (14, 'G322', 3, '3C', 4, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (15, 'G322', 3, '3C', 5, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (16, 'G322', 4, '4D', 1, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (17, 'G322', 4, '4D', 2, 'OCCUPIED');
INSERT INTO TRAIN_SEATS VALUES (18, 'G322', 4, '4D', 3, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (19, 'G322', 4, '4D', 4, 'AVAILABLE');
INSERT INTO TRAIN_SEATS VALUES (20, 'G322', 4, '4D', 5, 'AVAILABLE');
构造的基本数据用表格可用直观的展示如下:
根据座位可用情况列出车内换乘的方案,有方案ABCD…多种组合,如下。
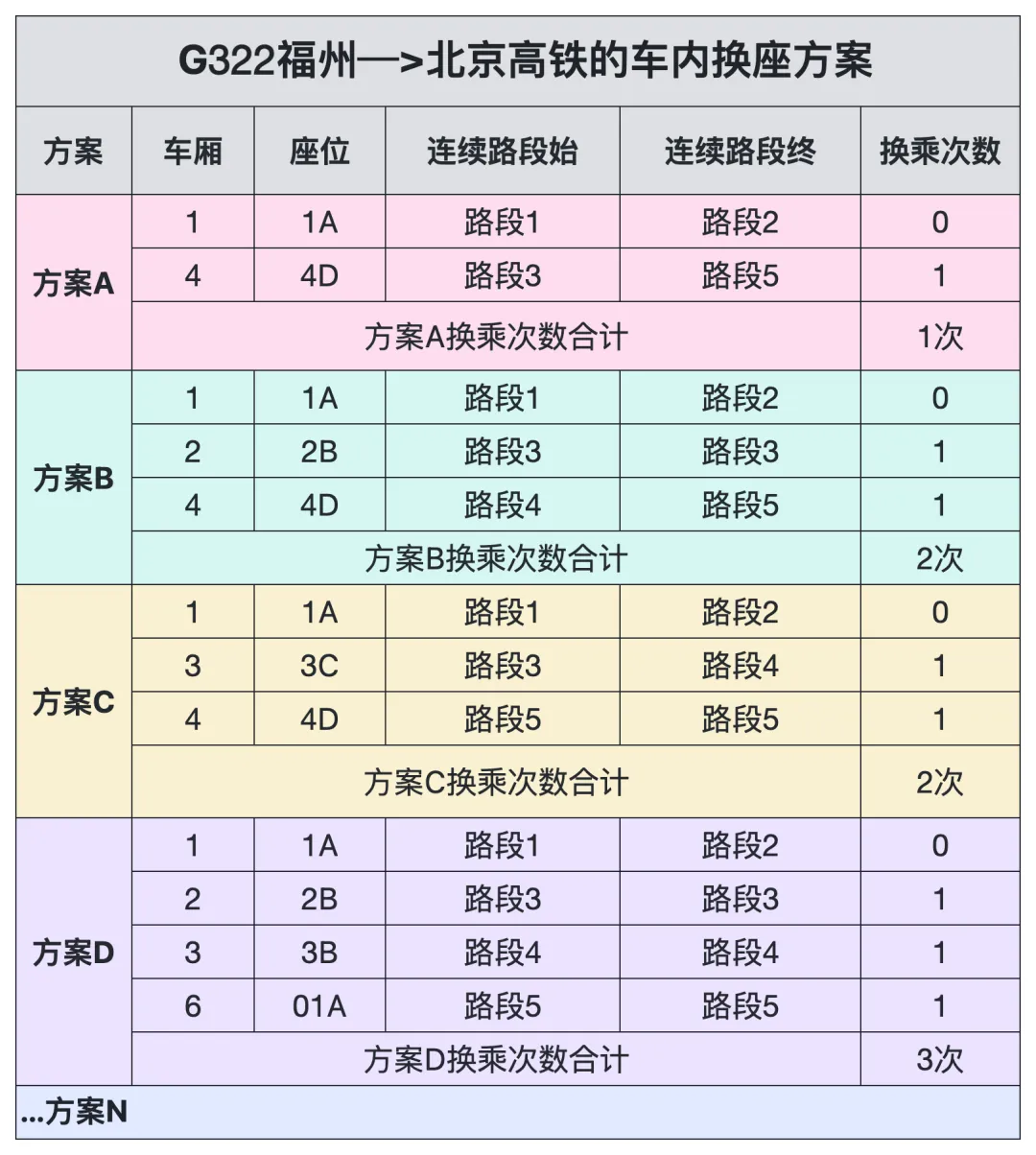
表格这么一列,结论出来了:方案A仅需1次换座,方案B和C需2次,方案D需3次。方案A为最佳换座方案。
看到这可能会有人会说,这很简单,一眼就看明白了。其实,你只是看懂了需求而已,实现起来可不容易。接下来要做的,就是告诉计算机一个它能识别的算法。
3. 最少换座次数的关键算法
首先,找出所有连续可用的座位段。比如,1车1A可以连续坐1-2段,2车2B可以连续坐2-3段,3车3C可以连续坐3-4段,4车4D可以连续做3-5段。
对于每个起始段,只保留能坐得最远的那个座位。为什么?因为如果有两个座位都能从某一段开始,那么选择能坐得更远的那个显然更好。
从第一段起,不断选择能接上的且坐得最远的下一个座位,直到覆盖全程。
这个方法之所以有效,是因为不存在这样的情况:选择坐得更短的座位反而能得到更好的结果。即使是连续路段的座位,你也可以在中间换到其他座位。比如,如果座位A可以坐1,2,3,4段,座位B可以坐3,4,5,6段,那么在3或4换座位都不会影响最终的换座次数。
4. 最少换座次数的算法的SQL实现
写法1(用上Oracle SQL新特性的measures写法)
WITH available AS (
SELECT *
FROM train_seats
WHERE train_id = 'G322'
AND status = 'AVAILABLE'
-- 如果对旅程路段有要求就写在这里
-- AND segment BETWEEN 开始 AND 结束
),
s AS (
-- 这个子查询找出从每个段出发能够坐得最远的那些座位, 假设路段segment都是连续的正整数
SELECT *
FROM (
SELECT t.*
, ROW_NUMBER() OVER (PARTITION BY first_segment ORDER BY cnt DESC) rn
-- 每个段只需留下能坐得最长的一个座位
FROM available
MATCH_RECOGNIZE (
-- 识别出每张票最多能连续坐几段
PARTITION BY car_no, seat_no
ORDER BY segment
MEASURES
MIN(segment) AS first_segment,
MAX(segment) AS last_segment,
COUNT(*) AS cnt
ONE ROW PER MATCH
PATTERN (strt a*)
DEFINE a AS segment = PREV(segment) + 1
) t
)
WHERE rn = 1
-- 这个筛选过后数据已经很少了,每个路段最多留下一行数据,递归的工作量很少
),
t(last_segment, path, rn) AS (
-- 执行递归SQL,利用上述结果拼出完整的行程
SELECT last_segment,
'段'|| first_segment || ':' || car_no || '车:' || seat_no AS path,
1 AS rn
FROM s
WHERE first_segment = 1
-- 假设旅程开始段从1开始,也可以修改
UNION ALL
SELECT s.last_segment,
t.path || '->'|| '段'|| first_segment || ':'|| s.car_no || '车:'|| s.seat_no,
ROW_NUMBER() OVER (ORDER BY s.last_segment DESC) rn
-- 那些拼上去的座位按终点路段排序找出最远的
FROM t, s
WHERE t.rn = 1
-- 只需留下能够走得最远的那一个座位
AND s.first_segment <= t.last_segment + 1
AND s.last_segment > t.last_segment
)
SELECT path
FROM t
WHERE rn = 1
AND last_segment = 5
-- 终点路段为5,可以根据需求修改
;
写法2(传统的通用SQL写法)
WITH available AS (
SELECT train_seats.*,
segment - ROW_NUMBER() OVER (PARTITION BY car_no, seat_no ORDER BY segment) AS grp_id
-- 连续序号的差值作为分组依据
FROM train_seats
WHERE train_id = 'G322'
AND status = 'AVAILABLE'
-- 如果对旅程路段有要求就写在这里
-- AND segment BETWEEN 开始 AND 结束
),
s AS (
-- 这个子查询找出从每个段出发能够坐得最远的那些座位, 假设路段segment都是连续的正整数
SELECT * FROM (
SELECT car_no, seat_no,
MIN(segment) AS first_segment,
MAX(segment) AS last_segment,
COUNT(*) AS cnt,
ROW_NUMBER() OVER ( PARTITION BY MIN(segment) ORDER BY COUNT(*) DESC) rn
-- 每个段只需留下能坐得最长的一个座位
FROM available
GROUP BY car_no, seat_no, grp_id
)
WHERE rn = 1
-- 这个筛选过后数据已经很少了,每个路段最多留下一行数据,递归的工作量很少
)
SELECT* FROM (
SELECT SYS_CONNECT_BY_PATH ('段'|| first_segment || ':'|| car_no || '车:'|| seat_no, '->') AS path,
LEVEL AS change_count
FROM s
WHERE last_segment = 5
-- 终点路段为5,可以根据需求修改
START WITH first_segment = 1
CONNECT BY first_segment <= PRIOR last_segment + 1 AND last_segment > PRIOR last_segment
ORDER BY LEVEL
)
WHERE ROWNUM = 1;
这里需要注意的一些细节:
如何识别连续的数据段:写法1使用了MATCH_RECOGNIZE,这是一个强大的工具,可以用来发现数据中的模式。当然了,也可用ROW_NUMBER()的差额来求连续段,其原理是构造一个从1开始的连续序号,用这个序号和目标列进行相减,如果目标列是连续的话,这个差值就是一个恒定的数;假如目标列有断点,那么这个差值就会变成另外一个数字。用这个差值来进行分组就可以得到连续段。
如何构建最优路径:使用递归查询来构建最优路径,这种方法可以处理任意长度的旅程。
如何提高效率:首先找出了每个起始段能坐到的最远位置,这大大减少了后续处理的工作量。
如何使解决方案具有灵活性:这个方案可以轻松适应不同的旅程长度和座位情况,只需要修改几个参数就可以了。
至此,我们不仅学到了如何解决这个具体问题,还学到了如何用SQL来解决复杂的业务逻辑问题。这再次证明,掌握好数据库技术,可以在很多看似与数据库无关的场景中发挥重要作用。
5. 结语
从L老师的那次福州到北京的旅程开始,我们经历了"车内换座是否可能",“如何实现车内换座”,再到现在的"如何优化车内换座"。这个过程体现了技术人应有的思维方式:永远不满足于现状,总是在寻求更好的解决方案。

全文完
三分钟讲述个人感悟——感恩,回馈
公众号:收获不止数据库



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











