





和图像分割中将损失函数分为基于分布,基于区域以及基于边界的损失函数不一样,目标检测经常可以认为由2类最基础的损失,分类损失和回归损失而组成。
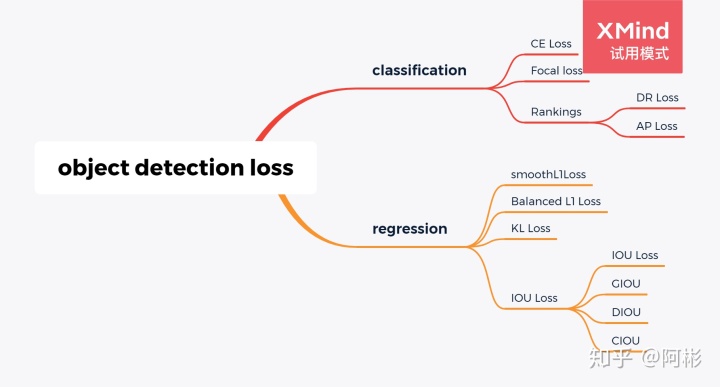
更多相关总结,可参阅
https://github.com/senbinyu/Computer_Vision_Literaturesgithub.com分类损失
- CE loss,交叉熵损失
交叉熵损失,二分类损失(binary CE loss)是它的一种极端情况. 在机器学习部分就有介绍它。
如下图所示,y是真实标签,a是预测标签,一般可通过sigmoid,softmax得到,x是样本,n是样本数目,和对数似然等价。
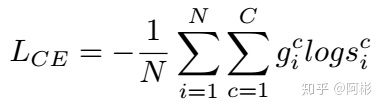
- focal loss,
用改变loss的方式来缓解样本的不平衡,因为改变loss只影响train部分的过程和时间,而对推断时间影响甚小,容易拓展。
focal loss就是把CE里的p替换为pt,当预测正确的时候,pt接近1,在FL(pt)中,其系数$(1-p_t)^gamma$越小(只要$gamma>0$);简而言之,就是简单的样例比重越小,难的样例比重相对变大
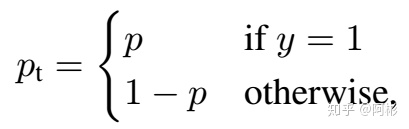
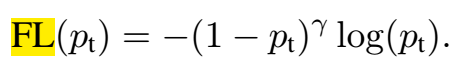
- Rankings类型的损失
在这有两类,DR(Distributional Ranking) Loss和AP Loss
- DR Loss, 分布排序损失, Qian et al., 2020, [DR loss: Improving object detection by distributional ranking](https://openaccess.thecvf.com/content_CVPR_2020/papers/Qian_DR_Loss_Improving_Object_Detection_by_Distributional_Ranking_CVPR_2020_paper.pdf)
DR loss的研究背景和focal loss一样,one-stage方法中样本不平衡。它进行分布的转换以及用ranking作为loss。将分类问题转换为排序问题,从而避免了正负样本不平衡的问题。同时针对排序,提出了排序的损失函数DR loss。具体流程可参考:张凯:2019 DR loss(样本不平衡问题)目标检测论文阅读

- AP Loss, Chen et al., 2019, [Towards Accurate One-Stage Object Detection with AP-Loss](https://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Towards_Accurate_One-Stage_Object_Detection_With_AP-Loss_CVPR_2019_paper.pdf)
AP loss也是解决one-stage方法中样本不平衡问题,同时也和DR loss类似,是一种排序loss。将单级检测器中的分类任务替换为排序任务,并采用平均精度损失(AP-loss)来处理排序问题。由于AP-loss的不可微性和非凸性,使得APloss不能直接优化。因此,本文开发了一种新的优化算法,它将感知器学习中的错误驱动更新方案和深度网络中的反向传播机制无缝地结合在一起。具体可参见:感知算法论文(九):Towards Accurate One-Stage Object Detection with AP-Loss

回归损失
回归损失在这里更多的是对应与bounding box的回归。
- MSE, RMSE,同样在机器学习中也会用来做回归损失。
常用在回归任务中,MSE的特点是光滑连续,可导,方便用于梯度下降。因为MSE是模型预测值 f(x) 与样本真实值 y 之间距离平方的平均值,故离得越远,误差越大,即受离群点的影响较大
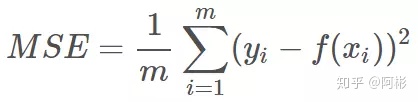
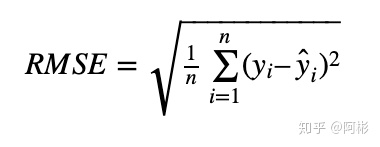
- Smooth L1 loss,
特殊的,smoothL1Loss是huber loss中的delta=1时的情况。这个损失函数用在了faster RCNN中,用于定位框的回归损失。
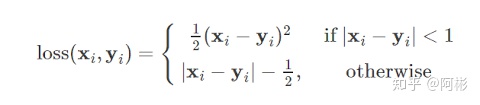
- balanced L1 Loss,
墨仆:目标检测中的loss
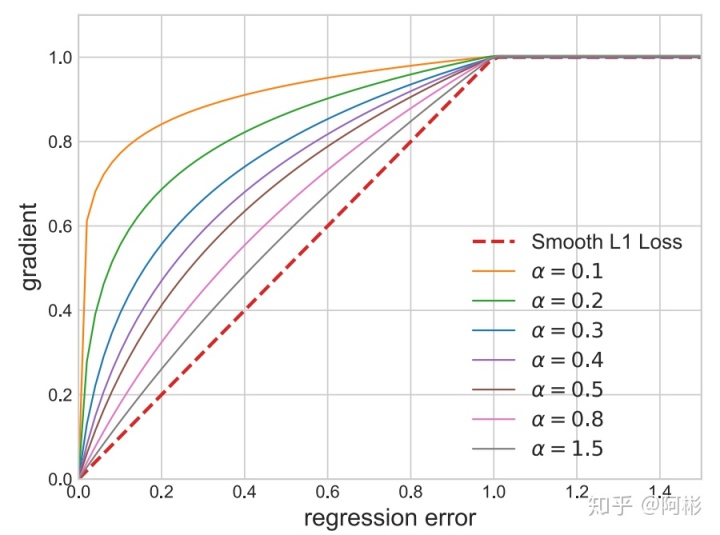
用在了Libra RCNN中,基于smoothL1Loss的改进。作者发现平均每个easy sample对梯度的贡献为hard sample的30%,相当于作者在找一个平衡的点,能让easy和hard的sample所占的梯度贡献差不多,因此引入了这个balancedL1Loss,其在接近于0的时候飞速下降,而在接近于1的时候缓慢上升,而不至于向smoothL1Loss那样只有中间regression error为1的时候有个突变,由此让他变得更加平衡,如下图所示。
文章:Pang et al., 2019, [Libra R-CNN: Towards Balanced Learning for Object Detection](https://openaccess.thecvf.com/content_CVPR_2019/papers/Pang_Libra_R-CNN_Towards_Balanced_Learning_for_Object_Detection_CVPR_2019_paper.pdf)
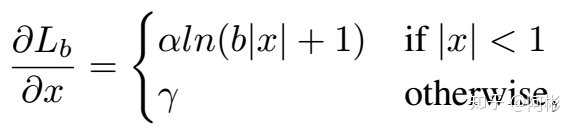
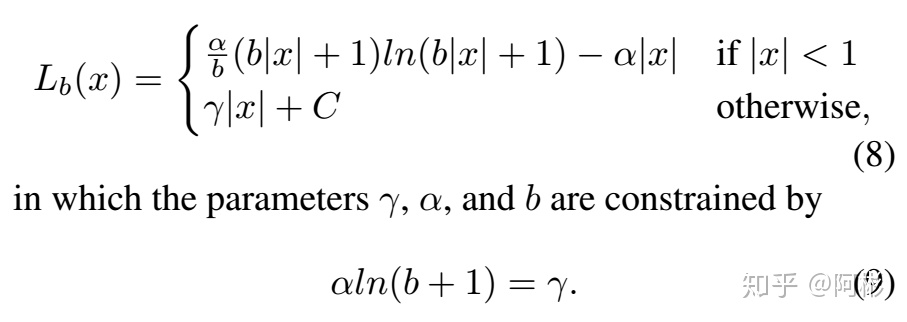
- KL Loss, He et al., 2019, [Bounding Box Regression with Uncertainty for Accurate Object Detection](https://openaccess.thecvf.com/content_CVPR_2019/papers/He_Bounding_Box_Regression_With_Uncertainty_for_Accurate_Object_Detection_CVPR_2019_paper.pdf)
这篇文章是为了解决边界不确定的box的regression问题(不被模糊样例造成大的loss干扰). 文章预测坐标(x1,y1,x2,y2)的偏移值,对于每个偏移值,假设预测值服从高斯分布,标准值为狄拉克函数(即偏移一直为0),计算这两个分布的距离(这里用KL散度表示距离)作为损失函数。参考smooth L1 loss,也分为|xg-xe|<=1和>1的两段,如下所示:

- region-based loss,基于区域的损失函数,IOU类
以上是针对样本分布的回归损失,后来发现基于区域的损失在回归框的任务中,起到了很好的效果,因此用基于框的回归损失函数来进行回归预测。具体可以看以下提供的实例,详细介绍了IOU的系列发展。
随后,我将基于YOLO系列给出的损失函数作为实例,因为它包括了多数情况。
YOLO系列的损失包括三个部分: 回归框loss, 置信度loss, 分类loss.
1. 从最重要的部分开始: 回归框loss.
- 从 v1 to v3, 回归框loss更像是MSE,v1是(x-x')^2 + (y-y')^2,而对w和h分别取平方根做差,再求平方,用以消除一些物体大小不均带来的不利。
- v2和v3则利用(2 - w * h)[(x-x')^2 + (y-y')^2 + (w-w')^2 + (h-h')^2], 将框大小的影响放在前面作为系数,连x和y部分也一块考虑了进去。
- v4作者认为v1-v3建立的类MSE损失是不合理的。因为MSE的四者是需要解耦独⽴的,但实际上这四者并不独⽴,应该需要⼀个损失函数能捕捉到它们之间的相互关系。因此引入了IOU系列。经过其验证,GIOU,DIOU, CIOU,最终作者发现CIOU效果最好。注意,使用的时候是他们的loss,应该是1-IOUs,因为IOU越大表示重合越好,而loss是越小越好,因此前面加1-,令其和平常使用规则一致。
- v5作者采用了GIOU,具体还需要等他论文出现。
下面介绍一下IOU系列:
这里有篇博客文章参考:Error:IoU、GIoU、DIoU、CIoU损失函数的那点事儿
- IOU, A与B交集 / A与B并集,在这一般是ground truth和predict box之间的相交面积/他们的并面积
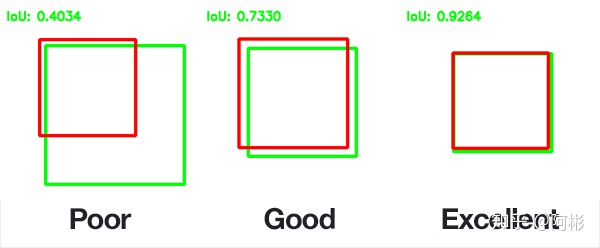
- GIOU, Rezatofighi et al., 2019, Stanford University, [Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression](Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression)
GIOU,针对IOU只是一个比值,IoU无法区分两个对象之间不同的对齐方式,因此引入了GIOU。下图中的A_c是两个框的最小闭包区域面积(通俗理解:同时包含了预测框和真实框的最小框的面积),减去两个框的并集,即通过计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重即可得到GIoU。
GIoU是IoU的下界,在两个框无限重合的情况下,IoU=GIoU=1;
IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标;
与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
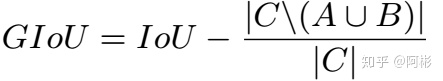
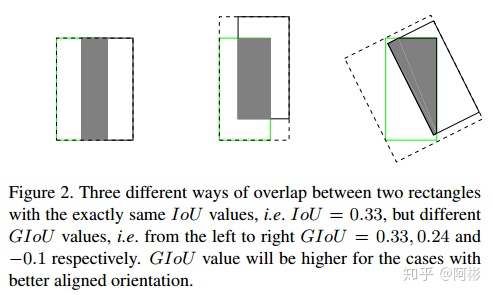
- DIOU,Zheng et al., 2019, Tianjin University, [Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression](https://arxiv.org/pdf/1911.08287.pdf)
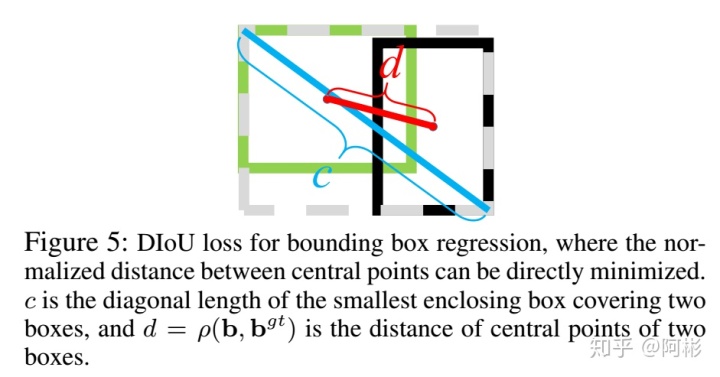
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题. 如下图所示,b和b^{gt}是预测的中心和ground truth的中心坐标,rho是指这两点之间的欧氏距离,c是两个框的闭包区域面积的对角线的距离。
DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
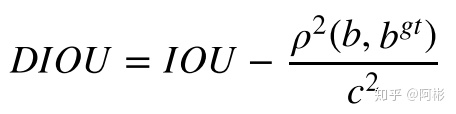
- CIOU, Zheng et al., 2019, Tianjin University, [Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression](https://arxiv.org/pdf/1911.08287.pdf)
虽然DIOU考虑了两中心的距离,但是没有考虑到⻓宽⽐。⼀个好的预测框,应该和 ground truth 的⻓宽⽐尽量保持⼀致。因此有了CIOU,在DIOU基础上加入了惩罚项。如下图是其CIOU loss,前面有了1-。而nu是衡量长宽比的相似性。
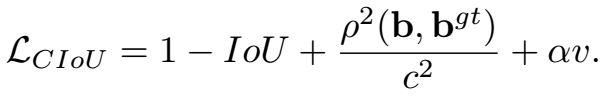
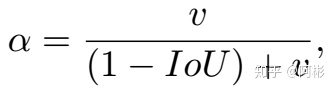
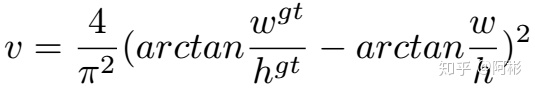
2. 置信度损失和分类Loss.
这里给出v1-v3的损失函数,可以看出,v1-v2中置信度误差和分类误差均使用的是MSE;
从v2到v3, 不同的地⽅在于,对于类别和置信度的损失使⽤交叉熵。
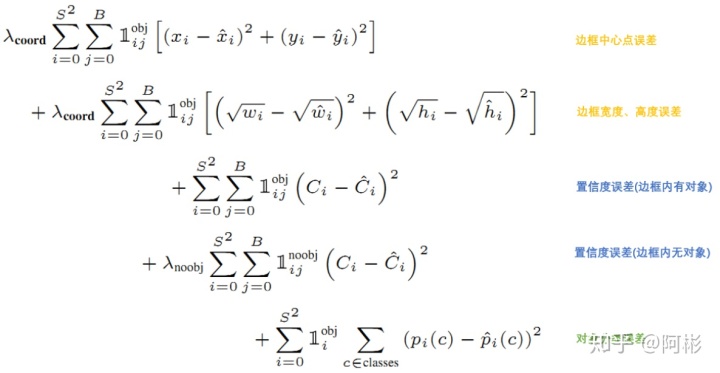
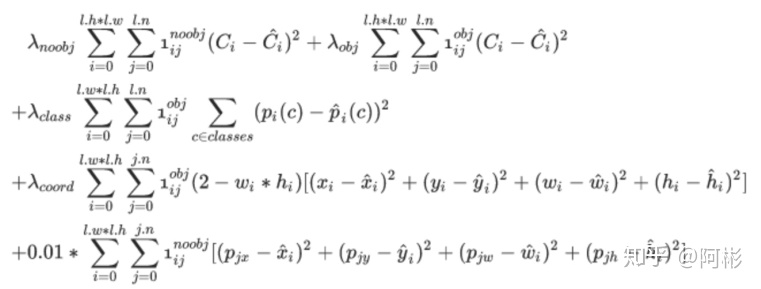

而v4相比于v3就在于回归框loss上,最终使用的是如前所述的CIOU。















 3442
3442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









