









原文:https://arxiv.org/abs/1912.04958
代码(官方tf版):https://github.com/NVlabs/stylegan2
代码(非官方Pytorch版):https://github.com/rosinality/stylegan2-pytorch
前言
StyleGAN v2在v1的基础上进行修改。主要解决了水滴伪影问题,进一步提高了图像的生成质量。成为人脸生成领域的新SOTA。另外舍弃了渐变网络结构,改为固定的网络训练。
论文核心
- 修复了v1中存在的水滴伪影
v1中所有特征图中都存在类似水滴的伪影,从64x64分辨率开始。作者认为原始的AdaIN摧毁了层与层间传递的信息。特征图创造出强烈的信号(伪影)为了防止被摧毁。 - 解决相位问题
渐进生成器导致。逐渐增长的生成器似乎对细节有强烈的偏好。当牙齿或眼睛等特征在图像上平滑移动时,它们可能会停留在原位 - PPL成为正则化项
实现更容易的生成器反转 - 更大的容量
更大的模型进一步提高生成质量
模型和方法
1. 新的网络结构
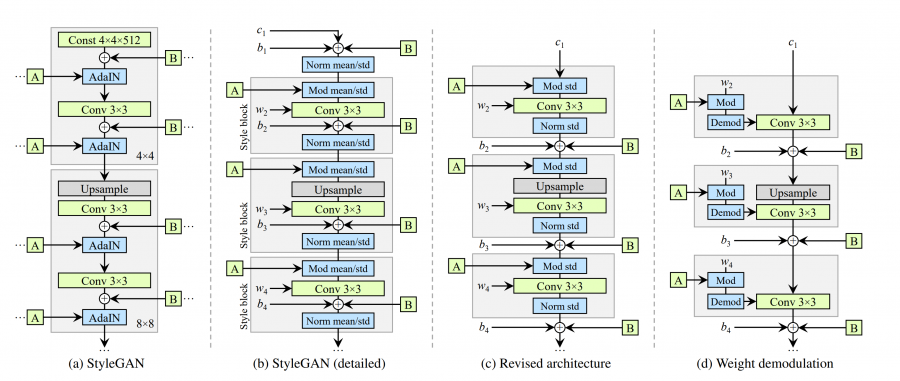
a. StyleGAN原版
b. StyleGAN拆分AdaIN模块:实例归一化和style调制
c. 作者去掉对均值的操作(归一化和调制)。修改添加噪声【B】的位置。
d. 从对特征图的修改,改为对卷积权重的修改。归一化改为demodulation。
2. Weight demodulation
对特征图的一系列操作改为对权重的操作。特征图只经过卷积处理并添加噪声。该方法在保留完全可控性的同时消除了伪影。
缩放特征图改为缩放卷积权重(mod):
w
i
j
k
′
=
s
i
⋅
w
i
j
k
w _ { i j k } ^ { \prime } = s _ { i } \cdot w _ { i j k }
wijk′=si⋅wijk
s
i
s _ { i }
si是第
i
i
i个输入特征图的缩放比例。
经过缩放和卷积后,输出激活的标准差为:
σ
i
=
∑
i
,
k
w
i
j
k
′
2
\sigma _ { i } = \sqrt { \sum _ { i , k } w _ { i j k } ^ { \prime } { } ^ { 2 } }
σi=i,k∑wijk′2
demod权重,旨在使输出恢复到单位标准差:
w
i
j
k
′
′
=
w
i
j
k
′
/
∑
i
,
k
w
i
j
k
′
2
+
ϵ
w_{i j k}^{\prime \prime}= w _ { i j k } ^ { \prime } { } / \sqrt {\sum _ { i , k } w _ { i j k } ^ { \prime } { } ^ { 2 }+\epsilon}
wijk′′=wijk′/i,k∑wijk′2+ϵ
加一个
ϵ
\epsilon
ϵ避免分母为0。
尽管这种方式与Instance Norm在数学上并非完全等价,但是weight demodulation同其它normalization 方法一样,使得输出特征图有着standard的unit和deviation。
3. 图像质量与生成器平滑度
通过实验发现,感知路径长度(PPL)分数低则生成图像的质量高。作者假设在训练过程中,由于判别器会对残破的图像进行惩罚,因此生成器改进的最直接方法是有效地拉伸产生良好图像的潜在空间,这将导致劣质图像被压缩到较小的变化快速的潜在空间中。虽然这可以在短期内提高平均输出质量,但累积的失真会损害训练状态,进而损害最终图像质量。所以将PPL作为正则项加到生成器上。
延迟正则化
每16个batch执行一次R1和路径长度正则化,大大降低计算成本和内存用量,而对结果无影响。
路径长度正则化
无论
w
w
w或图像空间方向如何,这些渐变应具有接近等长度,即小位移产生相同大小的变化。表示从潜在空间到图像空间的映射是良好的。
路径长度正则化不但提高了图片的生成质量,而且使得生成器更平滑,生成的图片反转回latent code更容易了。
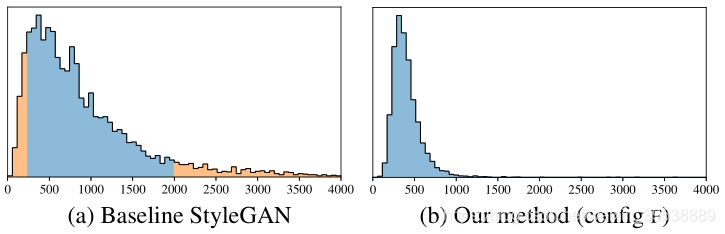
StyleGAN2(config F)极大地改善了PPL的分布,使之更加紧凑。
但是,结构化程度低于人脸FFHQ的LSUN Car数据集中的FID和PPL之间存在平衡。PPL降低反而导致FID升高。如下图config D所示。
4. 渐进式增长修正
作者们认为问题在于,在逐步增长的过程中,每个分辨率都会瞬间用作输出分辨率,迫使其生成最大频率细节,然后导致受过训练的网络在中间层具有过高的频率,从而损害了位移不变性。
在生成方法的背景下,Skip connections,残差网络和分层方法也被证明是非常成功的。三种生成器(虚线上方)和判别器体系结构如下图。Up和Down分别表示双线性上和下采样。 在残差网络中,这些还包括1×1卷积以调整特征图的channel数。tRGB和fRGB在RGB和高维每像素数据之间转换。 Config E和F中使用的体系结构以绿色突出显示。
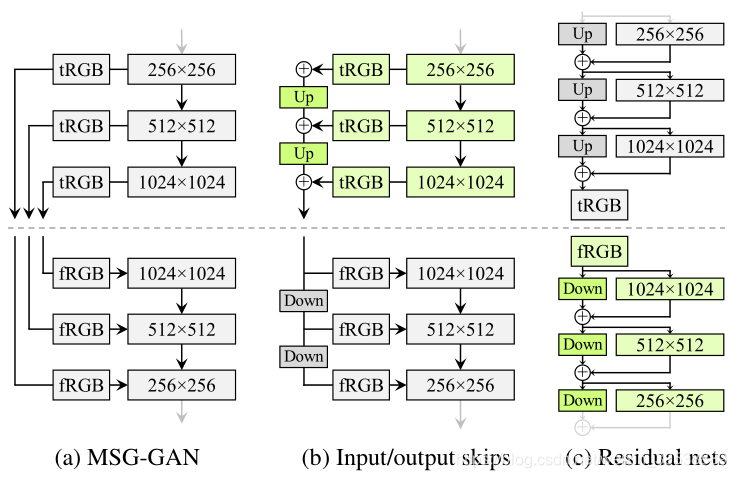

由上表可以看出使用skips连接的生成器PPL最小。使用残差网络的判别器对FID有利。
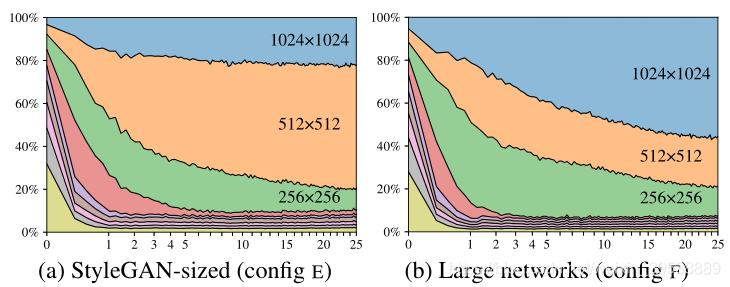
我们可以看到,从一开始,网络就专注于低分辨率图像,并随着训练的进行逐渐将其注意力转移到较大分辨率上。在(a)中,生成器基本上输出512x512图像,并对1024x1024进行一些细微锐化。而在(b)中,较大的网络更多地关注高分辨率细节。通过将两个网络的最高分辨率层中的特征图的数量加倍来进行测试。这使行为更加符合预期:图(b)显示了贡献的显著增加。
总结
关键点:
- 使用Weight demodulation代替AdaIN
- 发现PPL与生成图像质量的关系
- 去除渐进式网络
创新点:
- Weight demodulation
- Path length regularization
- 在生成器和判别其中采用不同的网络结构
启发:
- Normalization可能带来不好的结果
- 复杂的渐进网络看起来很酷,但往往复杂的东西更容易出错
- 把评价指标直接用作正则项,lazy正则化
参考
- https://blog.csdn.net/g11d111/article/details/109187245

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









