








生成对抗网络中一种基于样式的生成器结构
原文:https://arxiv.org/abs/1812.04948
代码(官方tf版):https://github.com/NVlabs/stylegan
代码(非官方Pytorch版):https://github.com/rosinality/style-based-gan-pytorch
文章目录
前言
学习StyleGAN之前推荐先学习Progressive GAN,因为前者是在后者的基础上改进的算法。Progressive GAN使用渐变的生成器进行渐进式训练,以生成1024x1024的图像。
论文核心
- 借鉴风格迁移,提出新的生成器结构:
实现自动且无监督地分离高级属性(姿态,身份)和随机变化(头发,雀斑)
可直观地,按特定尺度控制合成 - 更高的生成质量,插值性能的提升,更好的解耦能力
通过映射网络将latent code z映射到中间的隐空间W。输入潜在空间Z必须遵循训练数据的概率密度,这会导致某种程度的不可避免的纠缠,而中间潜在空间W不受限制。 - 两种新的量化隐空间解耦程度的方法
感知路径长度和线性可分性。证明了新的生成器相较于传统生成器允许更线性、更解耦地表示不同的变化因素。 - FFHQ人脸数据集,真正的1024x1024分辨率大规模人脸数据集,70000张
模型和方法
基于样式的生成器结构

- Z Z Z到 W W W的全连接mapping network f f f,高学习率会带来不稳定, λ ′ = 0.01 λ \lambda' = 0.01\lambda λ′=0.01λ
- 输入改为常数,latent code用作style控制
- 自适应实例归一化(AdaIN)
- 通过加入噪声为图片添加随机细节
Style控制
8层全连接网络,每层channel都是512。每个AdaIN模块对应一个全连接层A,将 w w w转为 y = ( y s , y b ) y=(y_s,y_b) y=(ys,yb),进行实例归一化。
自适应实例归一化(AdaIN)
此前的风格迁移方法,一种网络只对应一种风格,速度很慢。基于AdaIN可以“self modulate” the generator快速实现任意图像风格的转换。

L
=
L
c
+
λ
L
s
L
c
=
∥
f
(
c
)
−
f
(
t
)
∥
2
L
s
=
∑
i
=
1
L
∥
μ
(
f
i
(
t
)
)
−
μ
(
f
i
(
s
)
)
∥
2
+
∑
i
=
1
L
∥
σ
(
f
i
(
t
)
)
−
σ
(
f
i
(
s
)
)
∥
2
\mathcal{L}=\mathcal{L}_{c}+\lambda \mathcal{L}_{s} \quad \mathcal{L}_{c}=\left\|f\left(c\right)-f\left(t\right)\right\|_{2} \\ \mathcal{L}_{s}=\sum_{i=1}^{L}\left\|\mu\left(f_{i}\left(t\right)\right)-\mu\left(f_{i}\left(s\right)\right)\right\|_{2}+\sum_{i=1}^{L}\left\|\sigma\left(f_{i}\left(t\right)\right)-\sigma\left(f_{i}\left(s\right)\right)\right\|_{2} \\
L=Lc+λLsLc=∥f(c)−f(t)∥2Ls=i=1∑L∥μ(fi(t))−μ(fi(s))∥2+i=1∑L∥σ(fi(t))−σ(fi(s))∥2
AdaIN
(
x
i
,
y
)
=
σ
(
y
)
(
x
i
−
μ
(
x
i
)
σ
(
x
i
)
)
+
μ
(
y
)
\operatorname{AdaIN}(x_i, y)=\sigma(y)\left(\frac{x_i-\mu(x_i)}{\sigma(x_i)}\right)+\mu(y)
AdaIN(xi,y)=σ(y)(σ(xi)xi−μ(xi))+μ(y)
特征图的均值和方差中带有图像的风格信息。所以在这一层中,特征图减去自己的均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,以实现转换的目的。与图中不同的是,StyleGAN的风格不是由图像的得到的,而是
w
w
w生成的。
样式混合,混合正则化

为了进一步鼓励样式进行本地化(减小不同层之间样式的相关性),作者采用混合正则化。运行两个潜码
z
1
z_1
z1,
z
2
z_2
z2通过映射网络,并具有相应的
w
1
w_1
w1,
w
2
w_2
w2控制样式,以便
w
1
w_1
w1在交叉点之前应用,
w
2
w_2
w2在交叉点之后应用。这种正则化技术可以防止网络假设相邻的样式是相关的。
覆盖与粗糙空间分辨率相对应的图层样式( 4 2 − 8 2 4^2 - 8^2 42−82),从源头复制高级属性,如姿势,通用发型,面部形状和眼镜,同时所有颜色(眼睛,头发,灯光)和保留目标的更精细的面部特征。 如果我们改为复制中间层( 1 6 2 − 3 2 2 16^2 - 32^2 162−322)的样式,我们会继承较小比例的面部特征,发型,从源头打开/关闭的眼睛,同时保留来自目标的姿势,一般面部形状和眼镜。 最后,复制与精细分辨率( 6 4 2 − 102 4 2 64^2 - 1024^2 642−10242)相对应的样式主要带来来自源的颜色方案和微结构。
随机变化

传统生成器,仅在网络开始部分输入随机向量。效率低,极易产生重复的模式。
添加噪声,增加图片丰富性,如(b)。但从标准差(c)可以看出,随机仅出现在头发和领子处,没有改变脸部高级特征。
由于噪声缺乏关联,很容易产生差异,所以无法用来控制整体特征。容易被判别器惩罚。

(a)噪音适用于所有层
(b)没有噪音,无法生成细节
(c)仅有精细层的噪音(
6
4
2
−
102
4
2
64^2 - 1024^2
642−10242),大分辨率带来更多细节变化
(d)仅粗糙层的噪音(
4
2
−
3
2
2
4^2 - 32^2
42−322),小分辨率细节的尺寸更大,很好理解
隐变量解耦
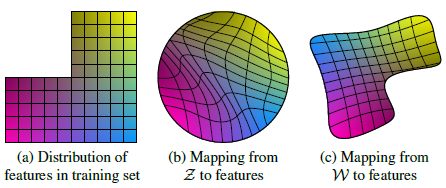
由于隐空间与图像特征之间的纠缠,对于隐空间(b)的插值会产生在生成图片中产生非线性的变化,出现(a)中不存在的特征。具有两个因素的示例(图像特征,例如,男性气质和头发长度)。(a)左上角空缺,组合几乎不存在(例如,长发男性)。(b)强制从Z到图像特征的映射变为弯曲,消除组合的可能性,以防止对无效组合进行采样。(c)然而,从
Z
Z
Z到
W
W
W的学习映射能够“消除”大部分翘曲。线性的映射对提升生成质量有益。
两种新的量化解耦的方法
其他量化解缠的指标需要编码器网络将输入图像映射到编码。这两种新方法都不需要编码器,所以对于任何数据集和生成器都是可计算的。
感知路径长度(Perceptual path length)
测量在潜在空间中执行插值时图像的变化程度,来了解隐空间到图像特征之间的纠缠度。
使用两个VGG16提取特征的加权差异来表示一对图像间的感知距离。
将潜在空间插值路径细分为线性段,每个段上的感知差异的总和就是感知路径长度。
使用100000个样本,分别计算
z
z
z和
w
w
w的PPL。由于
z
z
z已经归一化,所以对
z
z
z使用球面插值 slerp,而对
w
w
w使用线性插值 lerp。评估为裁剪后仅包含面部的图像。
l
Z
=
E
[
1
ϵ
2
d
(
G
(
slerp
(
z
1
,
z
2
;
t
)
)
,
G
(
slerp
(
z
1
,
z
2
;
t
+
ϵ
)
)
)
]
,
\begin{aligned} l_{\mathcal{Z}}=\mathbb{E}\left[\frac{1}{\epsilon^{2}} d\left(G\left(\operatorname{slerp}\left(\mathbf{z}_{1}, \mathbf{z}_{2} ; t\right)\right)\right.\right.,\\ \left.\left.G\left(\operatorname{slerp}\left(\mathbf{z}_{1}, \mathbf{z}_{2} ; t+\epsilon\right)\right)\right)\right], \end{aligned}
lZ=E[ϵ21d(G(slerp(z1,z2;t)),G(slerp(z1,z2;t+ϵ)))],
其中
z
1
,
z
2
∼
P
(
z
)
z_1,z_2\sim P(z)
z1,z2∼P(z),
t
∼
U
(
0
,
1
)
t\sim U(0,1)
t∼U(0,1),
G
G
G是生成器,
ϵ
=
1
0
−
4
{\epsilon} = 10 ^ { - 4 }
ϵ=10−4,
d
d
d为VGG测距。
d
d
d是自然二次所以除以
ϵ
2
{\epsilon^{2}}
ϵ2抵消对细分粒度不必要依赖。
l
W
=
E
[
1
ϵ
2
d
(
g
(
lerp
(
f
(
z
1
)
,
f
(
z
2
)
;
t
)
)
,
g
(
lerp
(
f
(
z
1
)
,
f
(
z
2
)
;
t
+
ϵ
)
)
)
]
,
\begin{aligned} l_{\mathcal{W}}=\mathbb{E}\left[\frac{1}{\epsilon^{2}} d\left(g\left(\operatorname{lerp}\left({f(\mathbf{z}_{1})}, f(\mathbf{z}_{2}) ; t\right)\right)\right.\right.,\\ \left.\left.g\left(\operatorname{lerp}\left({f(\mathbf{z}_{1})}, f(\mathbf{z}_{2}); t+\epsilon\right)\right)\right)\right], \end{aligned}
lW=E[ϵ21d(g(lerp(f(z1),f(z2);t)),g(lerp(f(z1),f(z2);t+ϵ)))],
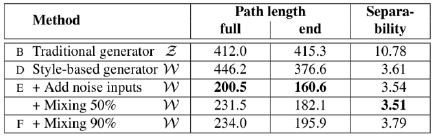
从表格我们可以看出config E:增加噪声后PPL明显减小。Config B优于D作者认为全路径PPL略偏向
z
z
z。由于
w
w
w路径上的插值向量可能没有对应的
z
z
z,即没被训练过,从而生成差效果。
端点PPL,即
t
∈
{
0
,
1
}
t \in \{0,1 \}
t∈{0,1},config D优于B。
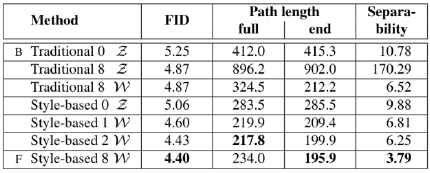
加入映射网络,FID和
w
w
w的PPL都更小了,并且深的映射网络带来更好结果。
在StyleGAN v2中,作者将PPL作为正则项加入到损失函数中。
线性可分性(linear separability)
如果隐空间与图像特征足够解耦,那么隐空间中存在线性超平面,可以二分类两种特征。
首先基于CelebA-HQ数据集,训练40种特征的分类器。然后用生成器生成200000张图像,用训练的分类器分类,去掉置信度最低的一半,得到隐变量和标签已知的100000张图像。对每个属性,用线性SVM拟合预测
z
z
z的类别,判断
z
z
z是否足够线性。线性关系用
X
X
X和
Y
Y
Y的分布差异衡量。
exp
(
∑
i
H
(
Y
i
∣
X
i
)
\operatorname { exp } ( \sum _ { i } H ( Y _ { i } | X _ { i } )
exp(i∑H(Yi∣Xi)
X
X
X为SVM预测的类别,
Y
Y
Y为分类器预测的类别
从上表最右列可以看出,增加mapping network的深度确实有助于提高
w
w
w的线性可分性。映射网络对传统生成器有同样的提升,具备通用性。
总结
关键点:
- 结合AdaIN模块
- 使用中间隐变量w实现映射关系的解耦
- 通过随机噪声进一步提升图像细节,丰富多样性
创新点:
- 加入可通用的映射网络
- 样式混合,使用两个中层隐变量生成一张图像,扩大 W W W的训练空间
- 感知路径长度
- 线性可分性
启发:
- 损失函数、模型结构、隐变量分布、数据集,每一项对于生成式模型都很关键。
- 解耦 - 让映射空间更线性的思想
参考
- https://zhuanlan.zhihu.com/p/63230738
- https://blog.csdn.net/weixin_43013761/article/details/100973679
- https://blog.csdn.net/lynlindasy/article/details/89555201
- http://www.gwylab.com/pdf/Note_StyleGAN.pdf














 2623
2623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









