







Table.AddFuzzyClusterColumn是Power Query的表函数之一,它可以对数据进行模糊匹配并分组,从而规范数据源中的数据,什么意思呢?
一个简单的例子,比如地名“北京”,在数据源中它可能是“北京”,“北京市”,“Beijing”甚至“北平”,而该函数需要解决的,就是由数据录入不规范,数据本身的标准不统一等原因导致的这种数据杂乱的问题。
为解决此问题,多数情况下,简单替换的方法显然不切实际,而该M函数可以使其规范化,这在数据清洗中特别实用。
幸运的是,自PowerBI Desktop上次更新(2020年8月)以来,已增加了对该函数的支持,下文讲解其具体用法。
基本用法
对于基本用法,我想引用文档中的举例的数据进行说明。首先我们有一个简单的表,里面包含英文城市温哥华和西雅图(如下),你可以留意到其中的单词大小写不一,且存在拼写错误(如seattl):

现在,我们回到Table.AddFuzzyClusterColumn函数,其用法如下:
Table.AddFuzzyClusterColumn()因此,针对以上数据,添加步骤,编写M语句如下:
#"Changed Type", "Location", "Location_Cleaned" )= Table.AddFuzzyClusterColumn(
这样,我们就可以得到如下结果,数据得到完美规范:
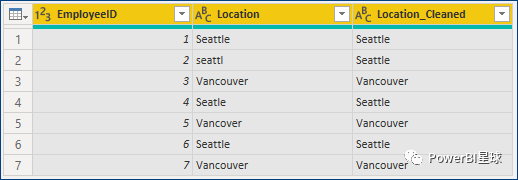
是不是很厉害!
上面只是基本的用法,利用该函数的可选参数,还有更强大的功能。
进阶用法
在进阶用法中,会在基本用法的基础上讲解参数的原理和使用方法,此外,处理的数据也改为文档中未涉及的中文文本。
首先利用以下M语句模拟一个火车站站名不规范的简易数据表:
--------let DATA = Table.FromRecords( { [ID = 1, Location = "北京西站"], [ID = 2, Location = "北京西站"], [ID = 3, Location = "广州东站"], [ID = 4, Location = "广州东站"], [ID = 5, Location = "广州东火车站"], [ID = 6, Location = "西九龙站"], [ID = 7, Location = "西九龙站"], [ID = 8, Location = "西九龙火车站"], [ID = 9, Location = "香港西九龙站"], [ID = 10, Location = "HK West Kowloon Railway Station"] }, type table [ID = nullable number, Location = nullable text] ) in DATA--------数据如下,当然你也可以手动先做好这个数据:

按上文使用Table.AddFuzzyClusterColumn的方式,此处使用第一个可选参数【Culture】。
文档对该参数的定义是“允许根据区域性特定规则对记录进行分组”,其实就是该函数默认处理对象是英文字符,如果是其他语言,就应该使用Culture指明要处理的语言。
于是编写M代码如下:
= Table.AddFuzzyClusterColumn(DATA,//源表名 "Location", "Location_Cleaned", [Culture="cn-ZH"])
这样我们得到如下效果:

现在北京西站这个名称得到了规范,空格问题得到处理。
但如何处理“广州东站zhan”这种混杂了拼音的记录呢?答案是使用强大的【Threshold】参数。
Threshold参数的范围为0到1.0,默认值是0.8,数值为1代表原数据不做任何处理,其越低代表其在纠正数据时,对数据本身的容错率越高。
此处将该参数设定为0.6后就解决了此问题。
注:此处你还可以增加IgnoreSpace= true参数显式地忽略空格。
= Table.AddFuzzyClusterColumn( DATA, "Location", "Location_Cleaned", [ Culture="cn-ZH", Threshold=0.6 ] )
效果如下:

到此我们发现以上方法,还未能解决表中第六行至第十行的命名杂乱问题,PQ没有足够的依据去智能地给他们归类,因为PQ并不清楚西九龙是香港的一个地名,当然更不可能了解"HKWest Kowloon Railway Station"的含义。
为解决此问题,该函数引入了【TransformationTable】参数,这将允许我们自定义一个转换表,以使得PQ可以按照转换表的定义来规范数据,从而彻底解决此类问题。
首先,定义转换表TRANS_TABLE:
转换表如下:{ [From = "西九龙站", To = "香港西九龙站"], [From = "西九龙火车站", To = "香港西九龙站"], [From = "HK West Kowloon Railway Station", To = "香港西九龙站"] }, type table [From = nullable text, To = nullable text] )= Table.FromRecords(
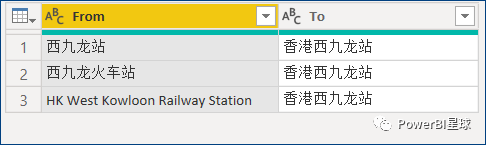
然后参数中引用该表:
= Table.AddFuzzyClusterColumn(
DATA,
"Location",
"Location_Cleaned",
[
Culture="cn-ZH",
Threshold=0.6,
TransformationTable=TRANS_TABLE
]
)
这样我们就完美地解决了问题。效果如下:

总结
Table.AddFuzzyClusterColumn函数在数据源不规范时十分有用,掌握它的用法就可以轻松处理这类问题,但对于企业BI解决方案而言,通过ETL等方式从源头上解决数据杂乱的问题才是最规范的做法。
知识链接

小必老师新书《Excel人力资源实战宝典》即将上架。
该书全书彩印,从人力资源管理中的招聘,培训,员工关系,绩效,薪酬,假期与考勤,薪酬与福利,人力资源规划各个模块出发,学入浅出地讲解Excel操作,公式函数,数据透视表,图表,Power Query的应用,绝对是你工作中的好帮手。集多年实际经验,案例丰富,题材新颖,HR职场必备。















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









