





1.UDP概述2. UDP的报文格式2.1 UDP首部格式2.2 UDP检验和计算方法
1.UDP概述
UDP只在IP的数据报服务之上增加了很少一点的功能:复用分用、差错检测
特点:
(1)UDP是无连接的,即发送数据之前不需要建立连接,因此减少了开销和发送数据之前的时延。
(2)UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的连接状态表(这里面有很多参数)
(3)UDP是面向报文的。
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
接收方的UDP,对IP层交上来的UDP用户数据报,去除首部后就原封不动地交付上层的应用进程。
(4)UDP没有拥塞控制,因此网络出现的拥塞不会使源主机的发送速率降低。这对某些实时应用很重要。很多的实时应用(如IP电话、实时视频会议等)要求源主机以恒定的速率发送数据,并且允许在网络发生拥塞时丢失一些数据,但却不允许数据有太大的时延。UDP正好适合这种要求。
(5)UDP支持一对一、一对多、多对一和多对多的交互通信。
(6)UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短得多。
虽然某些实时应用需要使用没有拥塞控制的UDP,但当很多的源主机同时都向网络发送高速率的实时视频流时,网络就有可能发生拥塞,结果大家都无法正常接收。因此,不使用拥塞控制功能的UDP有可能回引起网络产生严重的拥塞问题。所以,有些使用UDP的实时应用,需要对UDP进行适当的改进,在不影响应用的实时性的前提下,增加一些提高可靠性的措施,如采用前向纠错或重传已丢失的报文。
2. UDP的报文格式
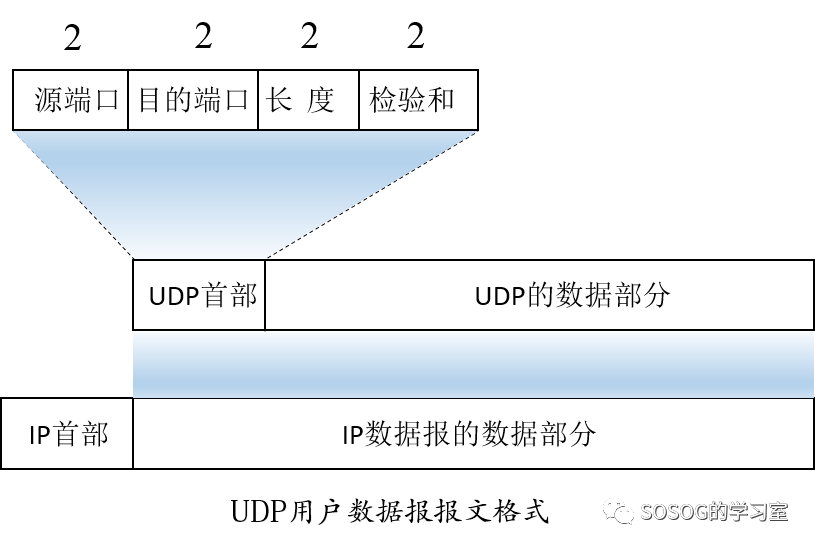
2.1 UDP首部格式
UDP有两个字段:数据字段和首部字段。
首部:8字节,四个字段组成,每个字段的长度都是两个字节。
(1)源端口号:在需要对方回信时选用,不需要时可用全0。
(2)目的端口号:在终点交付报文时必须使用。
(3)长度:UDP用户数据报的长度,其最小值是8(仅有首部)
(4)检验和:检测UDP用户数据报在传输过程中是否有错。有错就丢弃。
如果接收方UDP发现收到的报文中的目的端口号不正确(即不存在对应于该端口号的应用进程),就丢弃该报文,并有网际控制协议ICMP发送“端口不可达”差错报文给发送方。traceroute就是让发送的UDP用户数据报故意使用一个非法的UDP端口,结果ICMP就返回“端口不可达”差错报文,因而达到了测试的目的。
注意:虽然UDP之间的通信要用到端口号,但由于UDP的通信是无连接的,因此不需要使用套接字socket
2.2 UDP检验和计算方法
UDP的校验和不是必须的,如果不使用校验和,那么将校验和字段设置为0,而如果校验和的计算结果恰好为0,那么校验和置为全1。
在计算检验和时,要在UDP用户数据报之前增加12个字节的伪首部。并不是UDP用户数据报真正的首部。只是在计算检验和时,临时添加在UDP用户数据报前,得到一个临时的UDP用户数据报。检验和就是按照这个临时的UDP用户数据报来计算的。
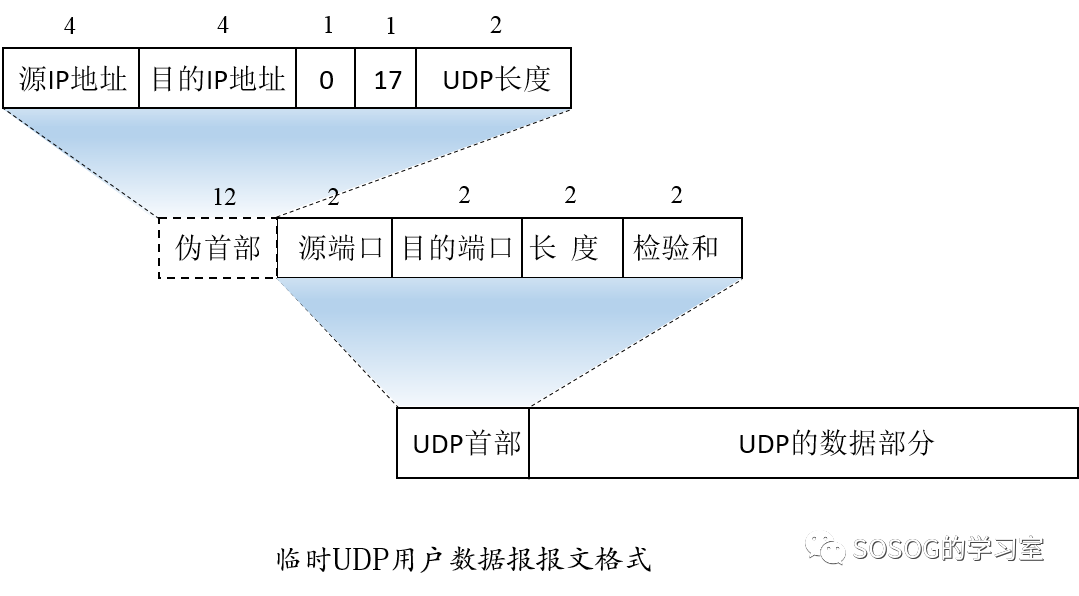
UDP计算检验和的方法和计算IP数据报首部检验和的方法相似。但不同的是:IP数据报的检验和只检验IP数据报的首部,但UDP的检验和是把首部和数据部分一起都检验。
发送方:先把全0放入检验和字段。再把伪首部以及UDP用户数据报看成是由许多16位的串连接起来的。若UDP用户数据报的数据部分不是偶数个字节,则要填入一个全0字节(但此字节不发送)。然后按二进制反码计算出这些16位字的和。将此和的二进制反码写入检验和字段后,就发送这样的UDP用户数据报。
接收方:把收到的UDP用户数据报连同伪首部(以及可能的填充全0字节)一起,按二进制反码求这些16位串的和。当无差错时其结果应该为全1。否则就表明有差错出现,接收方就应该丢弃这个UDP用户数据报(也可以上交给应用层,但附上差错警告)。
其实本质上来说这个计算原理还是不难的,就是一个二进制反码求和运算,具体来说就是:
其中10中的1加到了下一列去,如果是最高列的1+1,那么得到的10留下0,1移到最低列,与最低位再做一次二进制加法即可。
检验和,既检查了UDP用户数据报又检查了IP数据报的源IP地址和目的IP地址(伪首部)
注:UDP的校验和不是必需的,如果不使用校验和,那么将校验和字段设置为0,而如果校验和的计算结果恰好为0,那么将校验和置为全1。
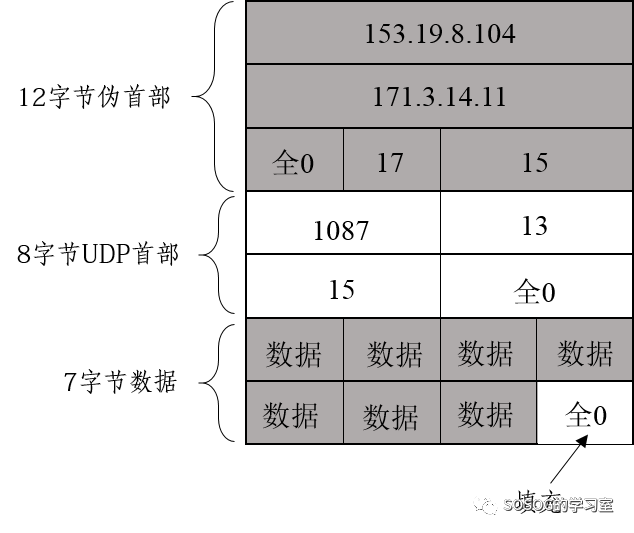
例如有如下UDP检验报文(加上伪首部后的UDP报文)
具体计算方法有两种:二进制反码加法和十六进制算法
二进制版 1001 1001 0001 0011 //伪首部源IP地址前16位————153.19 0000 1000 0110 1000 //伪首部源IP地址后16位————8.104 1010 1011 0000 0011 //伪首部目的IP地址前16位————171.3 0000 1110 0000 1011 //伪首部目的IP地址后16位————14.11 0000 0000 0001 0001 //伪首部UDP协议字段代表号17,前面8位是填充0————0和17 0000 0000 0000 1111 //伪首部UDP长度字段————15 0000 0100 0011 1111 //UDP头部源IP地址对应的进程端口号————1087 0000 0000 0000 1101 //UDP头部目的IP地址对应的进程端口号————13 0000 0000 0000 1111 //UDP头部UDP长度字段————15 0000 0000 0000 0000 //UDP头部UDP检验和————0 0101 0100 0100 0101 //数据字段 0101 0011 0101 0100 //数据字段 0100 1001 0100 1110 //数据字段 0100 0111 0000 0000 //数据字段+填充0字段 十六进制版 9913 //伪首部源IP地址前16位 0868 //伪首部源IP地址后16位 AB03 //伪首部目的IP地址前16位 0E0B //伪首部目的IP地址后16位 0011 //伪首部UDP协议字段代表号17,前面8位是填充0 000F //伪首部UDP长度字段 043F //UDP头部源IP地址对应的进程端口号 000D //UDP头部目的IP地址对应的进程端口号 000F //UDP头部UDP长度字段 0000 //UDP头部UDP检验和 5445 //数据字段 5354 //数据字段 494E //数据字段 4700 //数据字段+填充0字段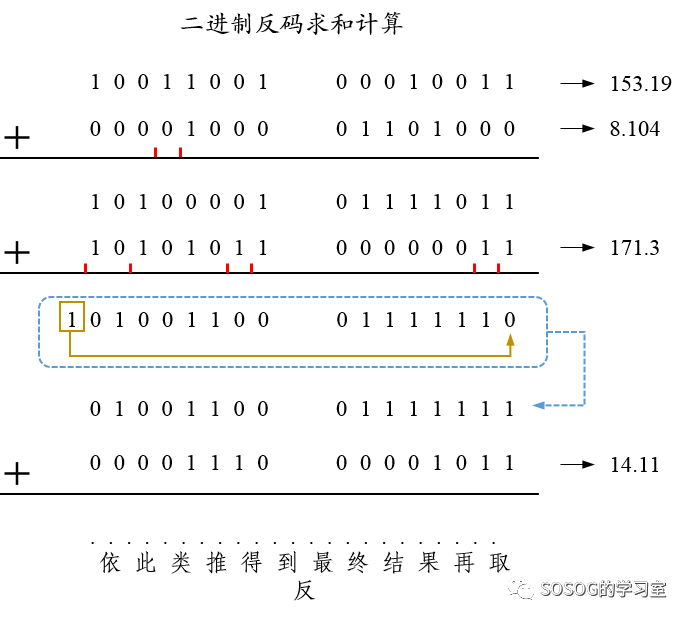
在二进制版中,不可以直接从右边第一列开始做竖式相加。
正确的做法是:
(1) 让第一行和第二行做二进制反码运算。 根据上述的规则,当碰到1+1=10时,在左邻侧一列下面写个小1(类似以前做十进制进位加法),然后侧列进行二进制反码运算得出一个数,如果没有进位,就继续与刚才的进位做二进制反码运算,如果有进位,则先把进位的小1写在相邻高侧列的下方,取个位来与其相加。有进位的只有1+1=10的情况,0不论加什么进位都不会有进位,而如果第一次计算没有进位时,只有产生1的情况下才会有进位,总而言之,对于每一列,都只会有至多一次的进位,所以不用担心进位会跨列的问题。这样子做要注意的就是不要写错数字了,比如我自己在写这张纸之前已经打过两次草稿了,然而还是会写错。 对于高位有1的情况,就是把1挪到最低位,再做一次二进制反码计算,本质来说就是取补码。
(2) 将第一行和第二行的结果与第三行做二进制反码计算,以此类推。
(3) 运算结果取反,得到校验和。
在十六进制版中,运算量会大大减小,主要的计算步骤如下:
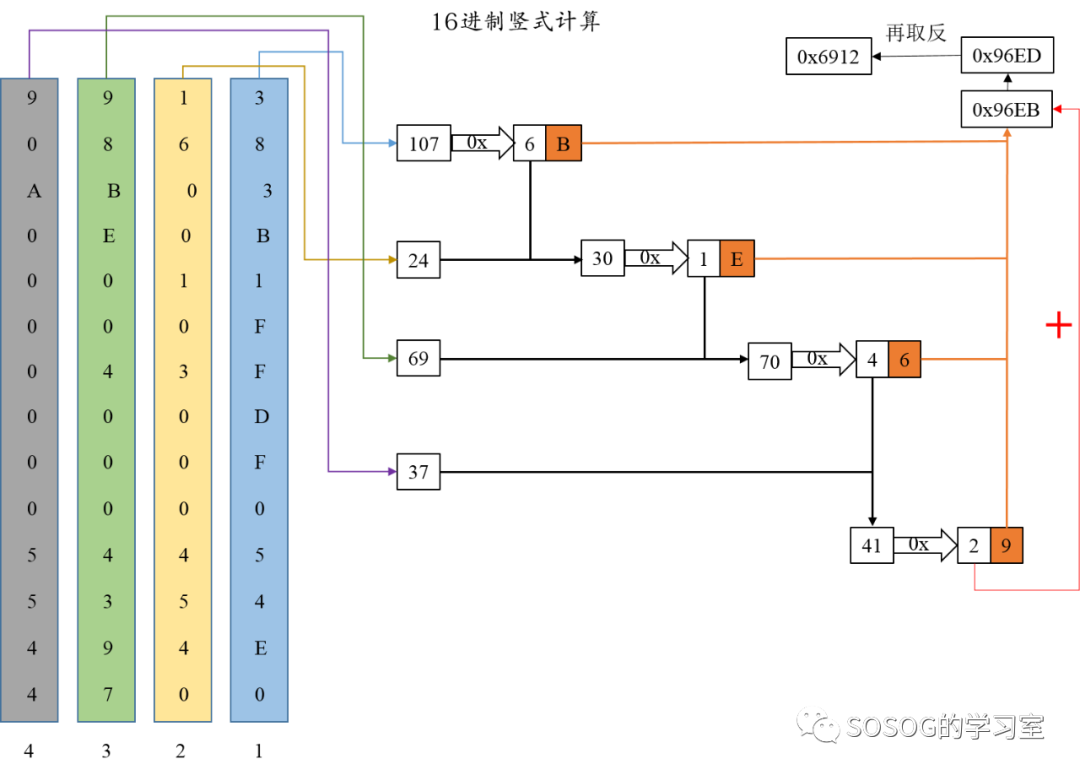
(1) 从右边第一列开始,按照十进制来计算第一列的值。在这里第一列算出来是107,转换为16进制就是0x6B。
(2) 根据算出来的结果分成两部分,左边的4位化成十进制6,作为下一列进位时加的数,右边4位化成16进制B,作为第一列的结果。
(3) 十进制计算第二列的结果,加上第一列得到的进位得到第二列的一个十进制数字,化为二进制,根据第二步来进行判断,依次类推。在这里第二列算到的是24,加上6就是30,化为8位二进制就是00011110,也就是1E,第二列的结果为1,第三列的十进制进位为1。接着可以算到第三列的结果为6,十进制进位为4。
(4) 最高位算出最后的十进制结果后,化为二进制时,右边4位作为最终结果,左边4位移入下一列,用上一步得到的结果0x96EB,加上0010b,得到最后结果。最后能得到结果为0x96ED。
(5) 结果取反,得到校验码。 校验码为0x6912。
UDP用户数据报的差错处理机制:发现差错,就丢弃UDP用户数据报,或者不丢弃,但要附加差错提醒。
eg:一个应用程序用UDP,到了IP层将数据报再划分为4个数据报片发送出去。结果前两个数据报片丢失,后两个到达目的站。过了一段时间应用程序重传UDP,而IP层仍然划分为4个数据报片来传送。结果这次前两个到达目的站而后两个丢失。问:在目的能否将这两次传输的4个数据报片组装成为完整的数据报?假定目的站第一次收到的后两个数据报片仍然保存在目的站的缓存中。
答:不行。重传时,IP数据报的标识字段会有另一个标识符。仅当标识符相同的IP数据报片才能组装成一个IP数据报。前两个IP数据报片的标识符与后两个IP数据报片的标识符不同,因此不能组装成一个IP数据报。所以成功接收必须保证所有的数据报片都成功接收,只要有一个不成功就必须向上层(一般是运输层,因为IP层没有重传的功能)通知重传数据。















 9111
9111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









