






声明:转自https://blog.csdn.net/TIME_LEAF/article/details/83443908
混淆矩阵的分析直接参考https://blog.csdn.net/guomutian911/article/details/78396399
个人感觉写的简洁明了的一篇博文,适合初学。
一、混淆矩阵的评价指标
记录一下,在学习用SVM分类时,需要对分类结果进行评价,光有正确率是不够的,所以就使用了混淆矩阵。原理的话,很多博客上都有,但为了便于理解程序,就简单讲一下。
结合程序,我们的类别是(-1,1),在Matlab中,类别是按照值的大小排的,即-1在前。但为了更加直观明了,解释理论的时候依然是1为正类。
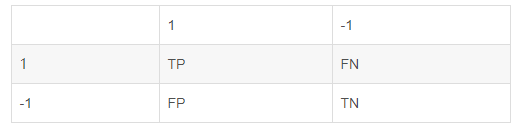
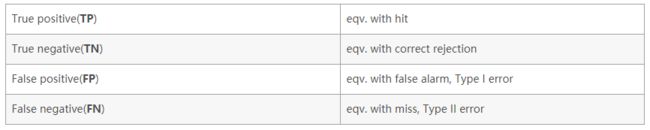
TP:真正,“T”,分类正确,“P”,预测为正
FP:假正,“F”,分类错误,“P”,预测为正
FN:假负,“F”,分类错误,“N”,预测为负
TN:真负,“T”,分类正确,“N”,预测为负
评价指标:
Precision 精确率:被正确分类的正样本数占所有被分成正样本数的比例
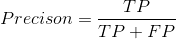
Recall 召回率:被正确分类的正样本数占正样本总数的比例
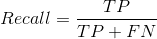
F1值:基于精确率和召回率的调和平均值
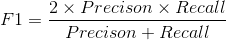
根据公式,我们可以写出代码:
clc
clear all
% 真实类别
real_label = [1, 1, -1, -1, -1];
% 预测类别
predict_label = [1, 1, -1, -1, 1];
% 利用“confusionmat”可以直接产生混淆矩阵,不过-1在前,1在后
[A,~] = confusionmat(real_label,predict_label);
% 计算-1类的评价值
c1_precise = A(1,1)/(A(1,1) + A(2,1));
c1_recall = A(1,1)/(A(1,1) + A(1,2));
c1_F1 = 2 * c1_precise * c1_recall/(c1_precise + c1_recall);
% 计算1类的评价值
c2_precise = A(2,2)/(A(1,2) + A(2,2));
c2_recall = A(2,2)/(A(2,1) + A(2,2));
c2_F1 = 2 * c2_precise * c2_recall/(c2_precise + c2_recall);
二、混淆矩阵的分析
假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示:
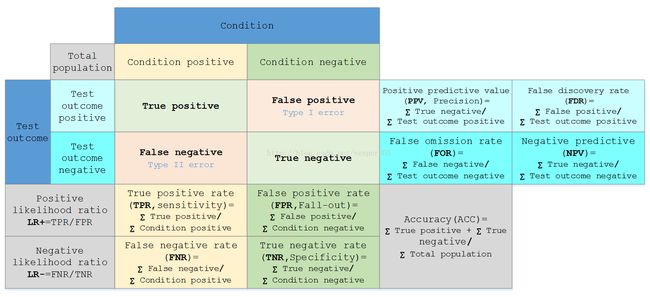 公式陈列、定义如下:
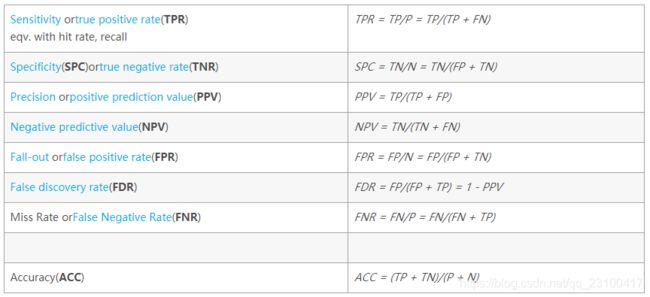
公式陈列、定义如下:















 2036
2036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









