






介绍
Apache Spark是数据处理框架中最热门,规模最大的开源项目之一,它具有丰富的高级API,可用于Scala,Python,Java和R等编程语言。
Spark提供了一个很棒的Python API,称为PySpark。这使Python程序员可以与Spark框架进行交互-允许您大规模处理数据并使用分布式文件系统上的对象。
在Mac上安装Spark(本地)
第一步:安装Brew
如果已经安装过了brew,可以跳过此步骤 :
1. 在Mac上打开终端(terminal)
2. 输入下面的命令。
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
3.点击回车继续,或按任何其他键放弃。
4.它可能要求sudo特权。如果发生这种情况,需要输入管理员密码,然后再次点击回车。
第二步:安装Anaconda
在同一终端中,只需输入:
$ brew cask install anaconda
第三步:安装PySpark
1. 终端类型
$ brew install apache-spark
2. 如果看到以下错误消息,
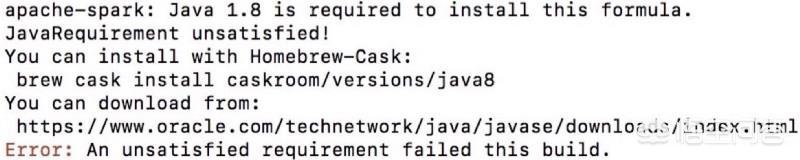
请执行
$ brew cask install caskroom/versions/java8
来安装Java8,如果已安装,则不会看到此错误。
3.在终端上输入,检查pyspark是否正确安装。
$ pyspark
如果您看到以下内容,则表明它已正确安装:
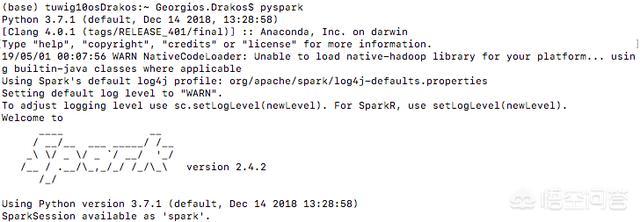
使用PySpark准备打开Jupyter笔记本
本节假定PySpark已正确安装,并且在终端上键入时没有出现错误
$ pyspark
在这一步,我将介绍您必须执行的步骤,以创建使用SparkContext自动初始化的Jupyter Notebook。为了为您的终端会话创建全局配置文件,您将需要创建或修改.bash_profile或.bashrc文件。在这里,我将使用.bash_profile作为示例
1. 检查您的系统中是否有.bash_profile $ ls -a,如果没有,请使用创建一个
$ touch ~/.bash_profile
2. 通过运行查找Spark路径
$ brew info apache-spark
3.如果您已经有一个.bash_profile,请执行
$ vim ~/.bash_profile
打开它,按”i“进行插入,然后将以下代码粘贴到任何位置(请勿删除文件中的任何内容):
export SPARK_PATH=(path found above by running brew info apache-spark)
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
#For python 3, You have to add the line below or you will get an error#
export PYSPARK_PYTHON=python3
alias snotebook='$SPARK_PATH/bin/pyspark --master local[2]'
4.按ESC退出插入模式,输入:wq以退出VIM。您可以在此处完善更多的VIM命令。
5.通过$ source ~/.bash_profile在Jupyter Notebook中使用PySpark的最喜欢的方式刷新终端配置文件是通过安装findSpark软件包,该软件包使我可以在代码中使用Spark Context。
findSpark包并非特定于Jupyter Notebook,您也可以在自己喜欢的IDE中使用此技巧。
通过在终端上运行以下命令来安装findspark
$ pip install findspark
启动常规的Jupyter Notebook,
$ pyspark
然后运行以下命令:
# useful to have this code snippet to avoid getting an error in case forgeting
# to close spark
try:
spark.stop()
except:
pass
# Using findspark to find automatically the spark folder
import findspark
findspark.init()
# import python libraries
import random
# initialize
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
num_samples = 100000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = spark.sparkContext.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
输出应为:
3.14179228
启动SparkSession
SparkSession是Spark功能的主要切入点:它表示与Spark集群的连接,您可以使用它来创建RDD并在该集群上广播变量。当您使用Spark时,一切都以此SparkSession开始和结束。请注意,SparkSession是Spark 2.0的一项新功能,可最大程度地减少要记住或构造的概念数量。(在Spark 2.0.0之前,三个主要的连接对象是SparkContext,SqlContext和HiveContext)。
在交互式环境中,已经在名为spark的变量中为您创建了SparkSession。为了保持一致性,在自己的应用程序中创建名称时应使用该名称。
您可以通过生成器模式创建一个新的SparkSession,该生成器模式使用“流利的接口”样式的编码通过将方法链接在一起来构建新对象。可以传递Spark属性,如以下示例所示:
from pyspark.sql import SparkSession
spark = SparkSession
.builder
.master("local[*]")
.config("spark.driver.cores















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









