







1.spark安装(本次启动一个worker)
首先安装spark
打开apache spark官网下载页点这里
选择spark版本下载,这里我选spark 2.0.2
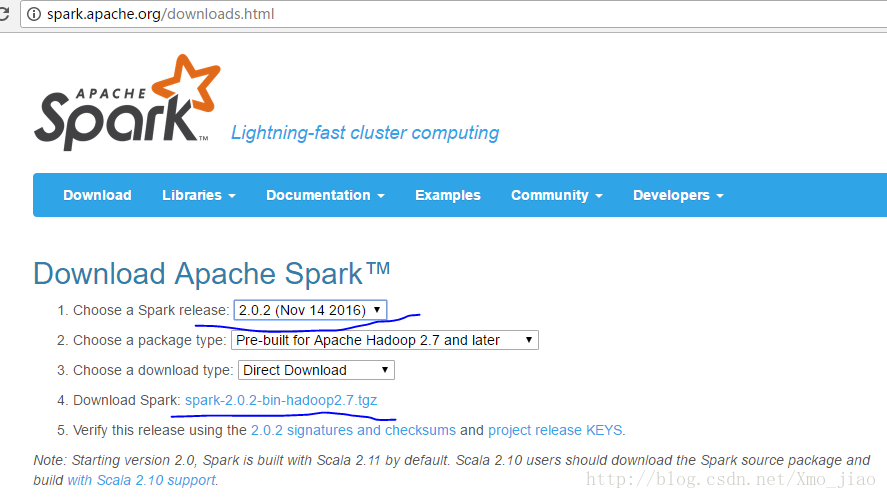
在linux系统中使用wget下载,wget是一种从网络上自动下载文件的自由工具,支持断点下载,很好用。没有此工具ubuntu,请使用一下语句安装
apt-get install wget
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz然后解压在安装目录
tar -axvf spark-2.0.2-bin-hadoop2.7.tgz重新命名安装目录文件名,便于记忆使用
mv spark-2.0.2-bin-hadoop2.7 spark
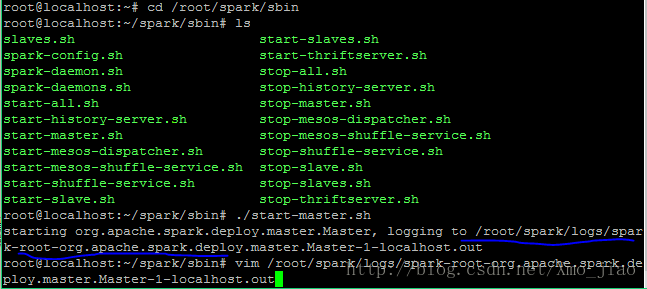
cd /root/spark/sbin接着启动spark master 和一个slave(work).一下第一条指令在安装目录启动spark master,第二条指令是进入启动日志中,为了找到spark UI中的地址,截图如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









