






前段时间我们谈到了Pod以及各种控制器,通过它们可以完成各类应用程序在Kubernetes上的部署。那么接下来就有个新问题了,当部署完成后,这些应用程序所提供的功能是如何被Kubernetes集群内部的其他Pod或外部所访问呢?难道是这样....

在前面我们曾提到过Pod是有IP地址的,咦~看上去问题迎刃而解了,直接访问Pod的IP地址不就行了吗?OK,OK,那么我们先来做一个简单的测试,用科学的方法来验证一下这个方案。采用控制器Deployment来部署一个Nginx的应用程序,yaml如下:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-app labels: testapp: nginx-appspec: replicas: 1 selector: matchLabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - image: nginx:1.11.9-alpine name: nginx-app-con部署成功后,可以看到Pod的status为Running,Pod的IP地址为10.244.1.23

接下来,我们来模拟Kubernets集群中其他Pod对该Nginx应用程序的访问。随便起一个Pod,
kubectl run test --image=busybox --command sleep 3600当该Pod正常运行后,我们通过该Pod来访问Nginx服务,因为所使用的busybox镜像中没有curl指令,所以我用wget来访问该Nginx服务。结果是OK的,确实可以通过Pod的IP地址来访问。

看来问题就这么解决了,so easy。。。

但真的就这么简单吗?这会不会是一个圈套?没错,少年,你的直觉很对,这就是个圈套,通过Pod IP来访问是很有问题的,很危险的,很违背社会主义核心价值观的。。。

首先,Kubernetes从未对Pod承诺“不离不弃”,因此不会去保证每个Pod的健壮性。这是因为Pod中的容器,会因为各种各样的原因发生故障,进而“呼吸不能自理”,那么此时Kubernetes就通过各种控制器的机制来动态的创建和销毁Pod,从而来保证应用整体的健壮性,也就是说“Pod可以死,团战不能输”。但随着Pod的创建或销毁,Pod的IP地址是会发生变化的,上一个时刻的Pod,也许在下一秒就成为了“最熟悉的陌生人”。
让我们继续刚才的实验,将Nginx的pod删除掉,那么根据前面我们学到的知识,我们可以很轻松的知道Deployment控制器会通过循环控制机制来observer这个Nginx的Pod对象,一旦发现实际状态(Pod被删除了,没有了)与预期状态(1个副本数)不一致,就会采取行动,重新创建一个Nginx Pod,我们来看看实际的效果。

不出所料,新的Pod被创建出来了,但Pod的IP却发生了变化,所以从这里就能看出通过Pod IP来访问应用程序所提供的功能或服务的方案是不可取的,客户端或者前端也很难做到踪Pod IP地址的变化。而且这里的Deployment中只设置了一个副本数,如果副本数量有10个,20个,100个,1000个,这就不仅要考虑如何跟踪地址的变化,还要考虑如在这些Pod之间去做负载均衡。我的天呐!你能想象出这画面是有多美吗?

看来问题很严重,毕竟违背了“核心价值观”,有点瑟瑟发抖了,咋办?别怕,今天来看看Kubernetes中另一个极为重要的对象---Service,只要有了它,Pod IP随便你变,副本数多少都没问题。来看看官方对于Service的定义,
An abstract way to expose an application running on a set of Pods as a network service. Also, defines a logical set of Pods and a policy by which to access them.The set of Pods targeted by a Service is usually determined by a selector.
https://kubernetes.io/docs/concepts/services-networking/service/
总结一下:
Service是应用服务的抽象,是对一组提供相同功能的Pods的抽象,并提供一个入口;
Service从逻辑上代表了一组pod,具体是那些pod则是由Selector通过label来挑选;
Service有自己的IP address,且保持不变
Kubernetes负责建立和维护Service与Pod的对应关系.

所以我们不难看出,这Service对象不就是个前端么,无论后端的Pods如何变化,都不会影响对前端的访问。概念是很简单,配置和使用也很简单,但其背后的实现要比马刺2017-2018赛季的战术复杂得多,因此这里先按下不表。

还是用上面的例子我们来看看如何来创建Service。一种是用指令,另一种是用yaml,这里采用指令来创建:
kubectl expose deployment nginx-app --port=80 --name=nginx-fe很简单,够直白(我不会告诉你这个指令能帮助你完成一道试题)。其含义就是把nginx-app这个Deployment暴露出去,并指明Service暴露在clusterIP上的端口是80,名称为nginx-fe。我们仍然通过test的这个Pod作为客户端去去访问,但此时访问的地址是Service的clusterIP

“没有一丝丝防备,也没有一丝顾虑“,就这么出现在Kubernetes的世界里,通过Service的clusterIP也能访问到Nginx服务。接下来,再看看这个Service和后端Pod的关联关系,上面提到过Serivce是由selector通过label来选择后端Pod的,我们通过指令来看看,如下:

这里稍微有点不同,由于刚才我们是直接expose deployment,所以Serivce通过labels选择了对应的Deployment,然后Deployment在根据label来选择Pod,但原理上都是Selector根据labels来选择。
此时,我们再次把Pod删一下,看看还是否能正常访问,如下:

仍然可以正常访问,再来看看发生了什么变化,如下:
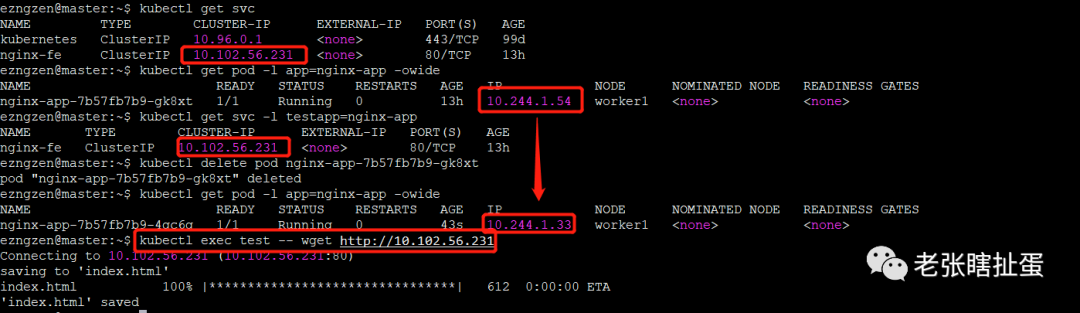
除了后端Pod的IP地址发生了变化,一切都没有变,刚好印证了前面所讲的内容,“任你后方瞎胡闹,前方依旧静悄悄”。这个就是Service对象所起到的作用。相信此刻的你,对于Service已经有了一个基本的认知,但这只是开头,让我们继续掰扯。

在Kubernetes中,Service有四种类型:
clusterIP 默认类型,k8s会自动分配一个仅cluster内部可以访问的虚拟IP
NodePort 在clusterIP上为service在每台机器上绑定一个端口,通过:NodePort来访问
LB,在NodePort基础上,借助cloud provide创建一个外部的LB,并将请求转发到:NodePort
ExternalName, 将服务通过DNS CNAME记录方式转发到指定的域名(通过spec.externalName设置)
在上面的所使用的expose指令中,我并没有指定type这个参数,因此Kubernetes就会使用默认类型,也就是clusterIP,这种类型的Service只能被集群内部所访问,如果要让外部也能访问到就需要使用到NodePort或LB,至于ExternalName也是用于内部的访问,通常用在跨Namespace的场景下通过name访问。CKA备考的话,建议掌握clusterIP和NodePort。
仍然以上一条指令为例,我带上了参数--port,但这个port还很有讲究,如下:
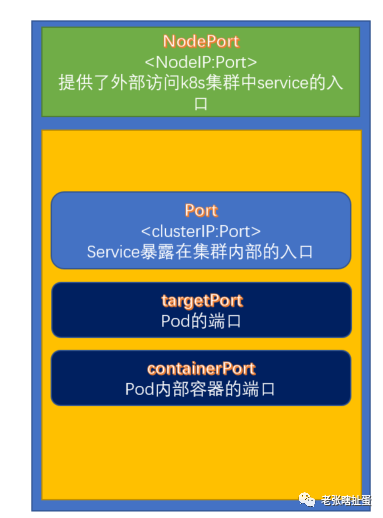
所以当你写yaml或者用指令的时候一定要分清楚这些Port,千万别弄混了,他们的含义不通,用法也不通,有的是在pod.spec.containers.port下定义,有的是在service.spec.ports下定义。具体如下:
Port 是Kubernetes内部访问Service的端口,通过clusterIP:Port来访问
noePort 是外部访问Kuberenets中Service的端口,暴露在node上的,通过NodeIP:nodePort来访问
targetPort 是Pod上的端口,从Port或者nodePort进来的流量最终都会流入到后端Pod的上的端口
containerPort 是Pod中容器的端口
hosPort 是容器所暴露的端口直接映射到主机端口
为了更好的让各位理解,我再啰嗦一下,举几个例子,如下:
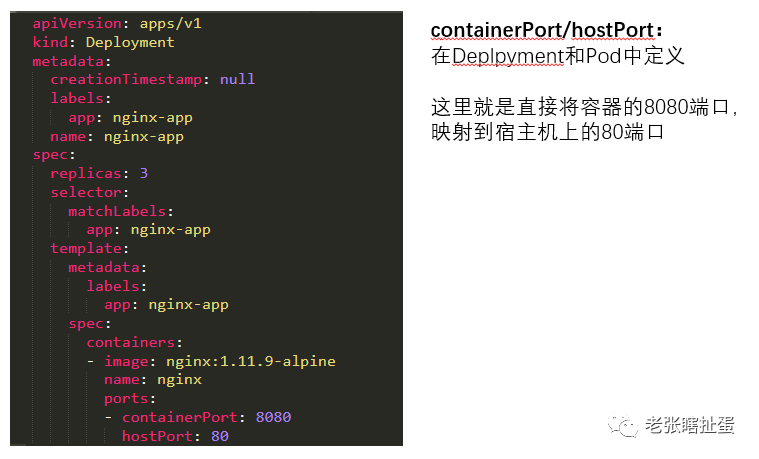


这三个例子熟练掌握后,恭喜你,又掌握了几道CKA试题。
另外,还有一点Service和Pod都会被分配DNS A记录:
对clusterIP的Service来说,A记录格式为...svc.cluster.local
对Pod来说,A记录格式为...pod.cluster.local
另外clusterIP还可以设置为None,即headless service,记录格式也是...svc.cluster.local,但会返回所有被代理的Pod的地址集合
这个也要掌握,知道怎么要去dig Service/Pod,这样又到手了一分。
其实谈到Service这个概念,是很难避免去谈到负载啊,kube-proxy等等,限于篇幅,本文尽量弱化了这些部分,更加注重考试要掌握的内容,所以还是以后再单独开一篇来谈谈。但这些内容又是属于不吐不快,如鲠在喉的那种,因此折中一下,列一下我觉得比较重要的tips,有兴趣的童鞋可以上网找资料了解一下,
kube-proxy是负责service的实现,实现了内部从pod到service和外部node port向service的访问;
kube-proxy支持三种模式,目前在用的是iptables(默认)以及ipvs,而userspace已经在Kubernets 1.2后就淘汰了;
ipvs的效率要比iptables高;
无论是iptables,还是ipvs,流程上都是kube-proxy依据service和endpoints的消息,来创建iptables规则或者ipvs规则;
由于Iptables是针对本地的,所以每个节点上都要运行kube-proxy;
service 提供的是round robin方式的负载均衡。这负载均衡的方式是通过iptables实现的
仅仅通过Kubernets内置的这四种Service类型,不足以满足生产环境的需要,所以Kuberentes还提供了Ingress的方式;
只有处于running,且就绪检查通过的pod,才会出现在service的endpoints list里,否则Kuberentes会自动的删除掉;
clusterIP是ping不通的,因为它不对应任何一个网络设备,而是iptbales/ipvs的规则,仅仅作为入口而已
本文的例子好好练习一下,对于CKA备考好处多多。另外,如果打算近期考试的童鞋,最好再9月1日之前完成考试,因为CKA即将迎来更新,具体的内容可以上官网去查阅。

好了,就到这里,下期再见!














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









