







腾讯课堂 | Python网络爬虫与文本分析
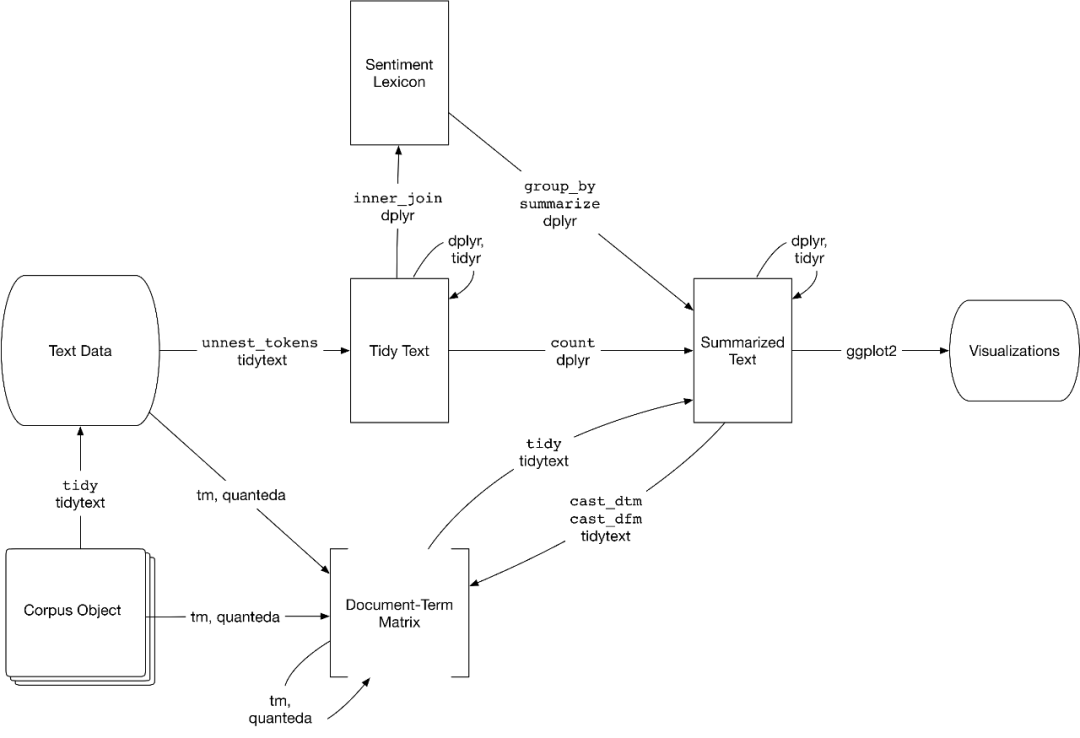
TidyTextPy
前天我分享了 tidytext | 耳目一新的R-style文本分析库
但是tidytext不够完善,我在tidytext基础上增加了情感词典,可以进行情感计算,为了区别前者,将其命名为tidytextpy。
大家有时间又有兴趣,可以多接触下R语言,在文本分析及可视化方面,R的能力也不弱。
安装
pip install tidytextpy
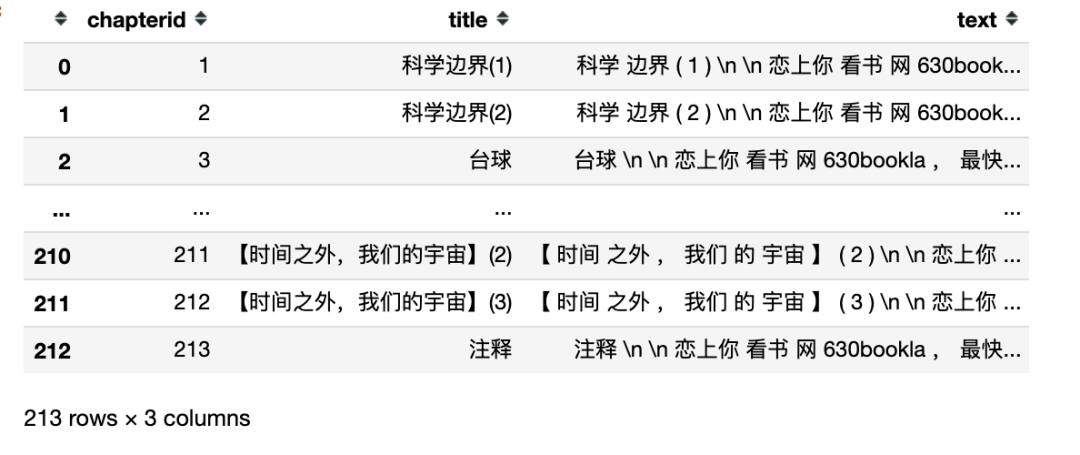
实验数据
这里使用中文科幻小说《三体》为例子,含注释共213章,使用正则表达式构建三体小说数据集,该数据集涵
- chapterid 第几章
- title 章(节)标题
- text 每章节的文本内容(分词后以空格间隔的文本,形态类似英文)
import pandas as pd
import jieba
import re
pd.set_option('display.max_rows', 6)
raw_texts = open('三体.txt', encoding='utf-8').read()
texts = re.split('第\d+章', raw_texts)
texts = [text for text in texts if text]
#中文多了下面一行代码(构造用空格间隔的字符串)
texts = [' '.join(jieba.lcut(text)) for text in texts if text]
titles = re.findall('第\d+章 (.*?)\n', raw_texts)
data = {
'chapterid': list(range(1, len(titles)+1)),
'title': titles,
'text': texts}
df = pd.DataFrame(data)
df

tidytextpy库
- get_stopwords 停用词表
- get_sentiments 情感词典
- unnest_tokens 分词函数
- bind_tf_idf 计算tf-idf
停用词表
get_stopwords(language) 获取对应语言的停用词表,目前仅支持chinese和english两种语言
from tidytextpy import get_stopwords
cn_stps = get_stopwords('chinese')
#前20个中文的停用词
cn_stps[:20]
['、',
'。',
'〈',
'〉',
'《',
'》',
'一',
'一些',
'一何',
'一切',
'一则',
'一方面',
'一旦',
'一来',
'一样',
'一般',
'一转眼',
'七',
'万一',
'三']
en_stps = get_stopwords()
#前20个英文文的停用词
en_stps[:20]
['i',
'me',
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









