





问题描述
在视频结构化和人脸识别项目中前端视频流源源不断地进入深度学习模型,目标检测后得到的图片需要存储在硬盘中用于检索回溯。经小编统计,在W市100路人脸识别视频流一天的图片抓拍量大约为15万,如果将如此多的图片直接存在硬盘或某些存储盘阵中,存储机的索引节点将随着时间推移逐渐占满,检索的速度越来越慢,另外图片的删除也成为一个头疼的问题。经项目实践,1000路视频流截取的图片在一月内足以让我司1PB的储存系统的索引节点瘫痪。
造成这一问题的原因并不是图片占据的存储空间大,而是图片量多,也就是小文件数量太多,占用的文件索引过多。
为了解决这一问题,我司资深架构师,亲自操刀写了一个小文件存储系统,小编研究了一番为大家揭秘一下。
海量图片存储实现
开始之前需要对视频处理中的一些术语做一下简单描述。在项目中每一个摄像头都是有唯一编号的,称为camera_id。连续的视频流要进行目标识别,需要对视频进行抽帧处理,一般的项目中1秒抽一帧就足够啦,当然如果你计算资源足够多,你可以随便抽,多多益善。抽帧时刻的时间戳记为frame_timestamp。对于每一帧中的不同目标(也就是识别出的人车物等)也有唯一的编号,记为track_id。因此,视频流中的图片就能通过“camera_id+frame_timstamp+track_id”组成的字符串唯一标识,一般camera_id为18位长度String,frame_timstamp为10位的Unix时间戳,track_id一般为一直自增的整数,这里我们假定给它预留了10位。这样,就能将“cameraid_frametimstamp_trackid”这样一个长度为40的String定义为每张图片的唯一ID。视频流中截取的object图片一般为50K左右,称为抓拍图片。
既然图片以小文件形式存储会占用索引节点,计算机中所用东西都是二进制字节码,那就将小文件合并成大文件字节码再进行存储,以此来解决小文件存储难的问题,项目中我们每小时将图片合并一次。同时,为了索引图片,我们需要将图片的索引信息记录在另一个文件中进行后续图片检索。
存储和检索流程如下图所示:
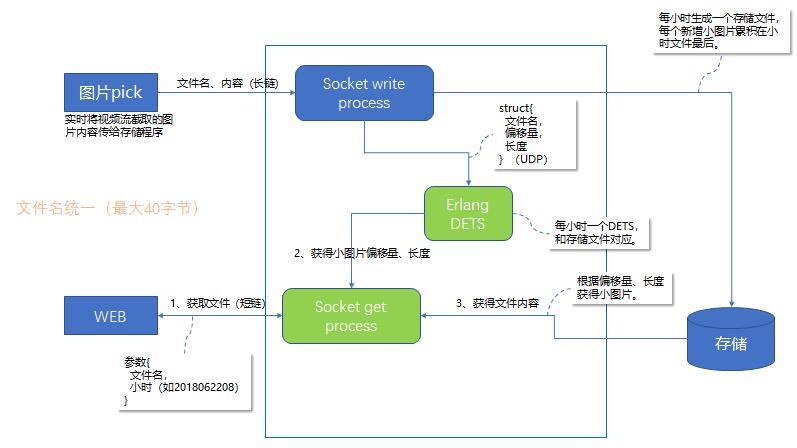
如上图,视频流图片截取节点截取的图片经部署在该机器的程序通过socket长链接不间断传输给存储节点图片存储程序,传输的内容包括图片文件名和内容。存储程序在收到内容后,通过高并发erlang存储程序,将图片内容以字节码形式写入文件名类似2018091209.block的文件,同时将图片文件名、block文件中偏移量、长度信息记录在2018091209.det文件中。两文件以日期+24小时时间格式作为文件名,每小时生个一组图片内容+索引内容的图片存储。在小编参与项目中,图片pick用python实现,图片内容和索引文件写入用C+erlang实现。
在图片索引阶段,通过前端web向java后台发送http请求来获取图片。前端web请求的http形式为http://ip:port/ cameraid+frametimstamp+trackid.jpg。java后台收到请求后,通过socket将请求发送给存储程序,存储程序对请求图片的cameraid+frametimstamp+trackid文件名进行解析,根据frame_timestamp计算出该图片存储的block和det对应文件名,根据det中的图片索引信息在block中取出对应的图片信息发送给java后端,java后端通过http请求回传给前端页面。
该存储方案通过合并小文件、增加统一索引将分散的小文件以每小时一个content、一个索引文件的形式进行重组,并通过反解析进行文件索引。原来一小时数以万计的小文件,通过这种存储方式每小时只生成两个存储文件,从而减少了存储系统索引节点的占用。
本篇内容在本人个人公众号上也已发布,欢迎关注本人微信公众号“勤菜鸟”。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









