






结合策略
假定集成包含T个基学习器,其中h_i在示例x上的输出为h_i(x).
对于数值型的输出,最常见的结合策略是averaging.分为simple averaging 和 weighted averaging. 对于分类任务,最常见的结合策略是voting. 当训练数据很多时,一种更为强大的结合策略是使用学习法,即通过另一个学习器来结合。Stacking是学习法的典型代表。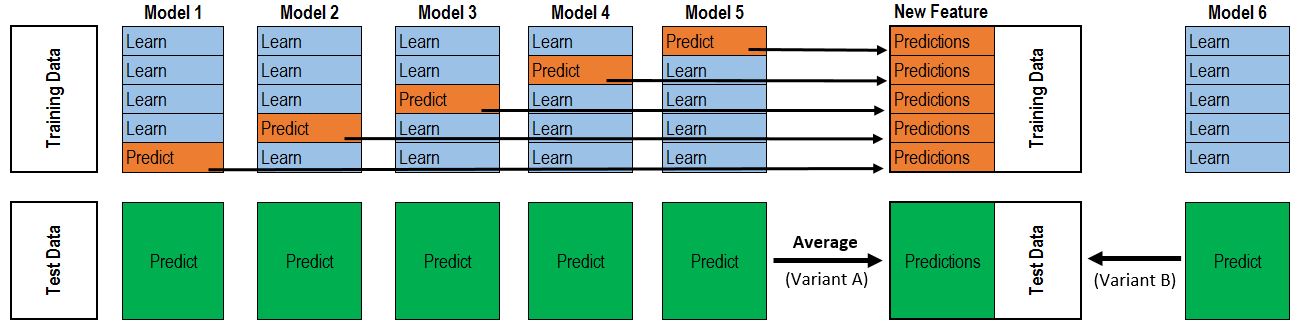
对于每一轮的 5-fold,Model都要做满5次的训练和预测。分别为model1-model5
Titanic 例子:
Train Data有890行。(请对应图中的上层部分)
每1次的fold,都会生成 713行 小train, 178行 小test。我们用Model_i来训练 713行的小train,然后预测 178行 小test。预测的结果是长度为 178 的预测值。
这样的动作走5次! 长度为178 的预测值 X 5 = 890 预测值,刚好和Train data长度吻合。这个890预测值是Model 1-5产生的,我们先存着,因为,一会让它将是第二层模型的训练来源。
重点:这一步产生的预测值我们可以转成 890 X 1 (890 行,1列),记作 P1 (大写P)
接着说 Test Data 有 418 行。(请对应图中的下层部分,对对对,绿绿的那些框框)
每1次的fold,713行 小train训练出来的Model _i要去预测我们全部的Test Data(全部!因为Test Data没有加入5-fold,所以每次都是全部!)。此时,Model _i的预测结果是长度为418的预测值。
这样的动作走5次!我们可以得到一个 5 X 418 的预测值矩阵。然后我们根据行来就平均值,最后得到一个 1 X 418 的平均预测值。
重点:这一步产生的预测值我们可以转成 418 X 1 (418行,1列),记作 p1 (小写p)
走到这里,你的第一层的某个model就完成了他的使命
代码如下
















 9196
9196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









