






安装scala
https://www.scala-lang.org/download/

sbt方式: https://www.scala-sbt.org/1.x/docs/sbt-by-example.html
- build.sbt
(scala版本和spark版本需保持一致,如都是2.11或都是2.12...)
name := "lrDemo"
version := "0.1"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-mllib_2.11" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-sql_2.11" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.4.3"
// 需要1.8的jdkname := "lrDemo"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" % "spark-core_2.12" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-mllib_2.12" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-sql_2.12" % "2.4.3"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.12" % "2.4.3"
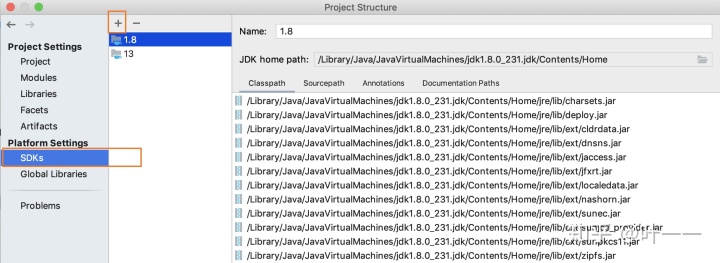
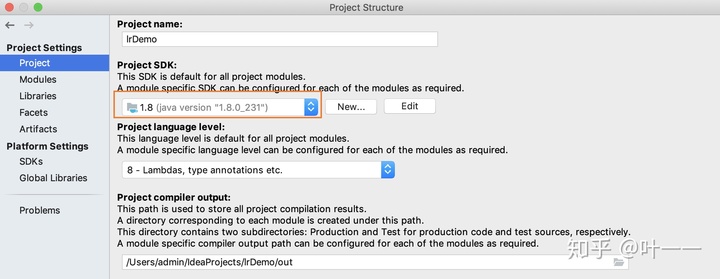
// 可用1.8或11或13的jdk- Intellij IDEA中更换jdk版本
- lrDemo.scala (以LogisticRegression为例)
package hxj.program.sparkDemo
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object lrDemo {
def NowDate(): String = {
val df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
df.format(new Date())
}
def main(args: Array[String]): Unit = {
本地测试
// val spark = SparkSession.builder().master("local[2]").getOrCreate()
// val sampleHDFS_train = "file:///Users/admin/IdeaProjects/lrDemo/data/input_demo"
// val sampleHDFS_test = "file:///Users/admin/IdeaProjects/lrDemo/data/input_demo"
// val outputHDFS = "file:///Users/admin/IdeaProjects/lrDemo/output"
val spark = SparkSession.builder().getOrCreate()
val sc = spark.sparkContext // 不同形式风格的sc
println("The url to track the job: http://bx-namenode-02:8088/proxy/" + sc.applicationId)
val sampleHDFS_train = args(0)
val sampleHDFS_test = args(1)
val outputHDFS = args(2)
val featureLst = Array("feature1", "feature2", "feature3")
val colLst = Array("uid", "label", "feature1", "feature2", "feature3")
//读取hdfs上数据,将RDD转为DataFrame
println("step 1 ", NowDate())
val schemaSample = StructType(colLst.map(column => StructField(column, StringType, true)))
// 训练数据
val sampleRDD_train = sc.textFile(sampleHDFS_train)
val rowSample_train: RDD[Row] = sampleRDD_train.map(_.split("t"))
.map(line => Row(line(0), line(1), line(2), line(3), line(4)))
var sampleDataFrame_train= spark.createDataFrame(rowSample_train, schemaSample)
// 测试数据
val sampleRDD_test = sc.textFile(sampleHDFS_test)
val rowSample_test: RDD[Row] = sampleRDD_test.map(_.split("t"))
.map(line => Row(line(0), line(1), line(2), line(3), line(4)))
var sampleDataFrame_test= spark.createDataFrame(rowSample_test, schemaSample)
// 转换数据类型
for (colName <- colLst) {
if (colName != "uid"){
sampleDataFrame_test = sampleDataFrame_test.withColumn(colName, col(colName).cast(DoubleType))
sampleDataFrame_train = sampleDataFrame_train.withColumn(colName, col(colName).cast(DoubleType))
}
}
/训练
println("step 2 ", NowDate())
val vectorAssembler: VectorAssembler = new VectorAssembler().setInputCols(featureLst).setOutputCol("features")
val lrModel = new LogisticRegression().setLabelCol("label").setFeaturesCol("features").setRegParam(0.01).setMaxIter(100)
val pipeline = new Pipeline().setStages(Array(vectorAssembler, lrModel))
val model = pipeline.fit(sampleDataFrame_train)
///预测,保存结果///
println("step 3 ", NowDate())
val labelsAndPreds = model.transform(sampleDataFrame_test)
.select("uid", "label", "prediction")
labelsAndPreds.show()
labelsAndPreds.write.mode("overwrite").csv(outputHDFS + "/target/output")
}
}
打jar包
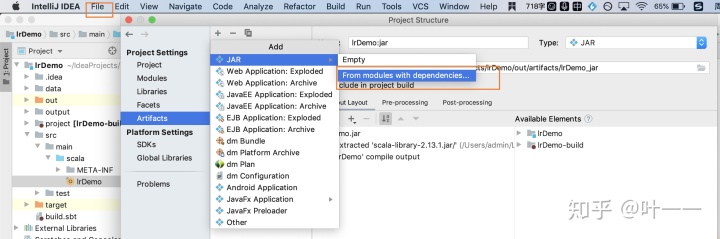
注:若打的jar包一直提示“找不到主类”:新建一个project,只print个helloWorld 打包,成功后 再修改build.sbt和代码(不确定原因。。感觉是IDEA的bug。。。)
- spark-submit
SPARK_PATH=/user/spark/spark
YARN_QUEUE=
DEPLOY_MODE=cluster
DEPLOY_MODE=client
input_path_train=hdfs:///user/huangxiaojuan/program/sparkDemo/input/train
input_path_test=hdfs:///user/huangxiaojuan/program/sparkDemo/input/test
output_path=hdfs:///user/huangxiaojuan/program/sparkDemo/scala_lrDemo
hadoop fs -rmr $output_path
${SPARK_PATH}/bin/spark-submit
--master yarn
--name "scala_lrDemo"
--queue ${YARN_QUEUE}
--deploy-mode ${DEPLOY_MODE}
--driver-memory 4g
--driver-cores 2
--executor-memory 12g
--executor-cores 4
--num-executors 6
--jars lrDemo.jar
--conf spark.default.parallelism=20
--conf spark.executor.memoryOverhead=4g
--conf spark.driver.memoryOverhead=2g
--conf spark.yarn.maxAppAttempts=3
--conf spark.yarn.submit.waitAppCompletion=true
--class hxj.program.sparkDemo.lrDemo ./lrDemo.jar $input_path_train $input_path_test $output_path查看日志:yarn logs -applicationId application_xxxxxxxx_xxxxx
杀掉任务:yarn application -kill application_xxxxxxxx_xxxxx
pyspark 参考:
叶一一:pyspark入门 | spark-submit 提交pyspark任务zhuanlan.zhihu.com














 2128
2128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









