





介绍
在你的工作面试中,这个问题被问了多少次?对我来说超过 10 次,我想把这个问题说得非常清楚,以节省每个人的时间。
HashMap 如何在 Java 中工作
HashMap 是一个基于散列表的键值对容器。它通常充当一个二进制哈希表,但是当 bins 变得太大时,它们就会被转换成 TreeNodes 的 bins。
一个典型的 HashMap 看起来是这样的:
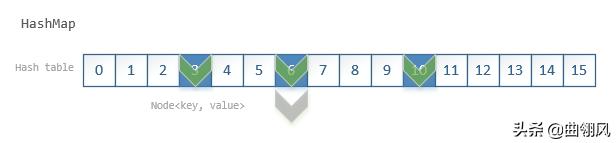
哈希表
该表充当索引,在第一次使用时初始化,例如 put(key, value)。默认容量为16。 假设我们初始化了一个 map:Map map = new HashMap<>(),我们现在想要 map.put(user1, "emai-add"),首先要识别表中的位置。Node 应该放在哪个单元格?
在哈希表中标识索引

在 Java 1.8 的实现中,是通过 hashCode() 的高 16 位异或低 16 位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在 bucket 的 n 比较小的时候,也能保证考虑到高低 bit 都参与到 hash 的计算中,同时不会有太大的开销。

节点
如果 table[index] 为空,我们可以直接 put 一个 Node(key, value) ,例如:

如果单元格已经被占用,检查节点并更新/插入新节点:
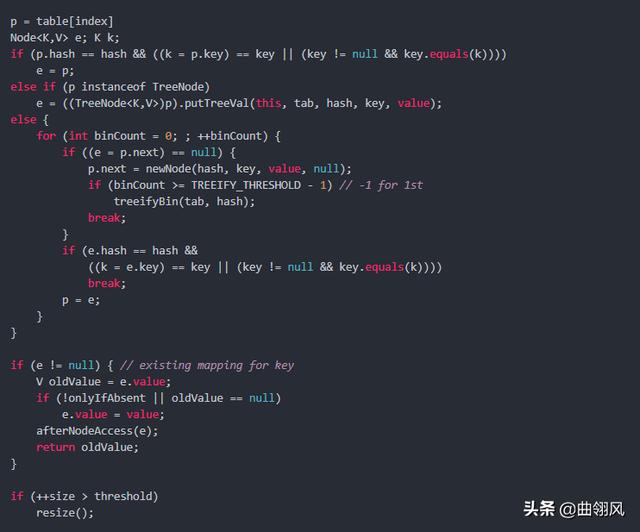
节点 Node 现在附加到哈希表上了。
在 put 方法的末尾,HashMap 将检查是否需要 resize()。
必要时调整大小
当put时,如果发现目前的 bucket 占用程度已经超过了 Load Factor 所希望的比例,那么就会发生 resize。在 resize 的过程,简单的说就是把 bucket 扩充为 2 倍,之后重新计算 index,把节点再放到新的 bucket 中。resize 的注释是这样描述的:
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
大致意思就是说,当超过限制的时候会 resize,然而又因为我们使用的是 2 次幂的扩展(指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。
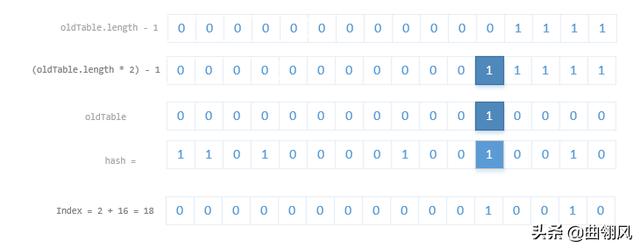
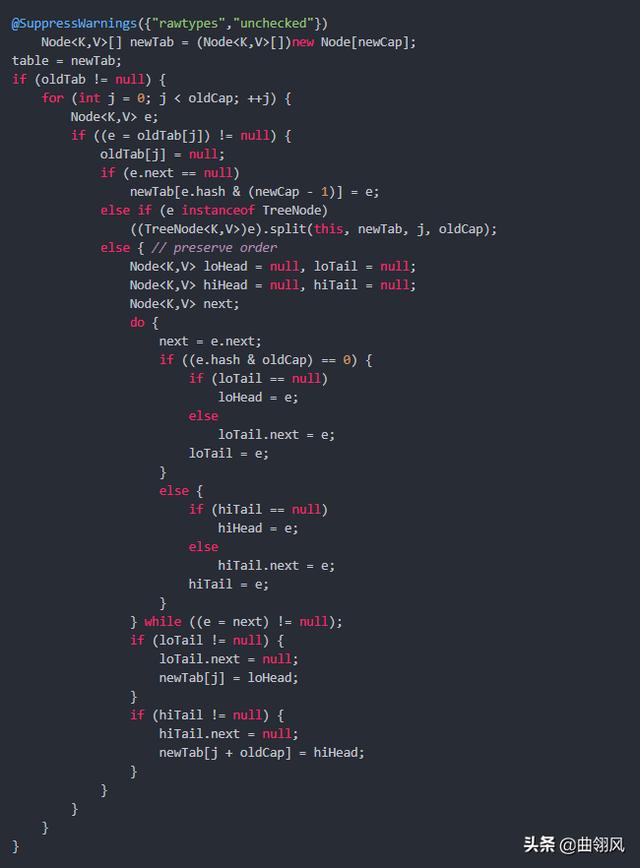
如果超过了负载因子(默认0.75),则会重新 resize 一个原来长度两倍的 HashMap,并且重新调用 hash 方法。
感谢大家的观看,欢迎关注我的头条号。















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









