






作者:Zarten 知乎专栏:python数据分析与挖掘深入详解 知乎ID: Zarten 简介: 互联网一线工作者,尊重原创并欢迎评论留言指出不足之处,也希望多些关注和点赞是给作者最好的鼓励 !
概述
这篇将介绍Series和DataFrame公有的一些重要的基础功能知识点。
重新索引排列
重新索引排列是指:可以将索引重新排列,若给出的新索引在旧索引中不存在时,会引入缺失值NaN。
重新索引排列不会改变原来的对象,而是会生成一个重新排列索引的对象。
使用Series和DataFrame的reindex()方法即可。
Series
import 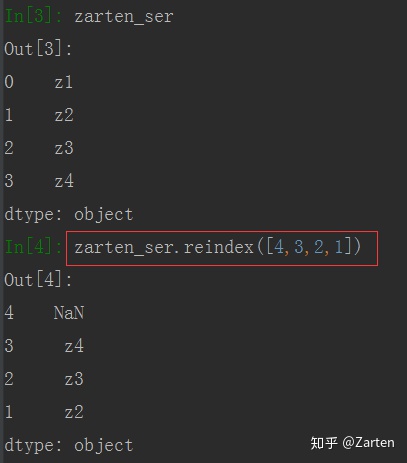
有时重新排列时,若新增一个之前没有的索引时值会自动填充NaN,若不想填充NaN,可以使用参数method= ‘ffill’,这时填充值会跟前面的值一样
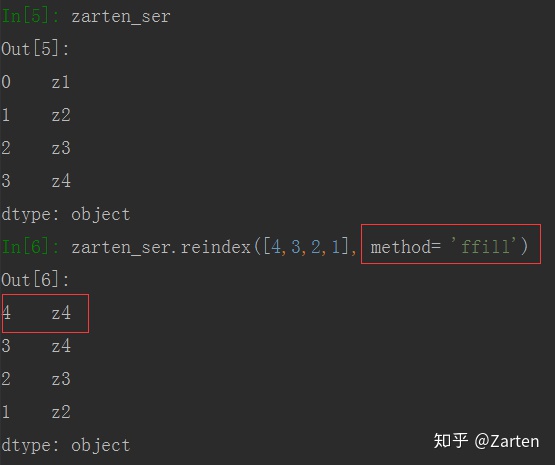
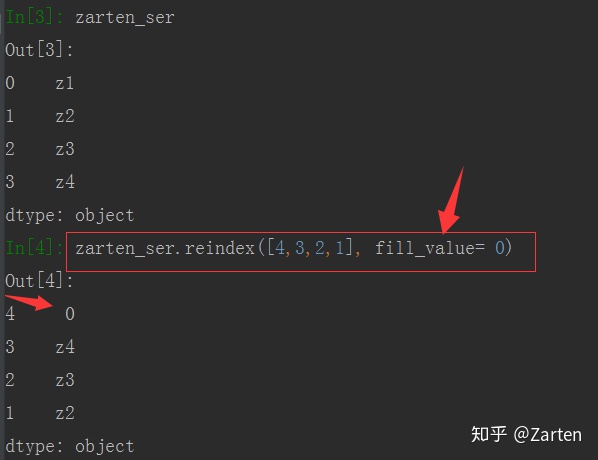
同时也可以使用参数 fill_value 来自己指定值,如下
DataFrame
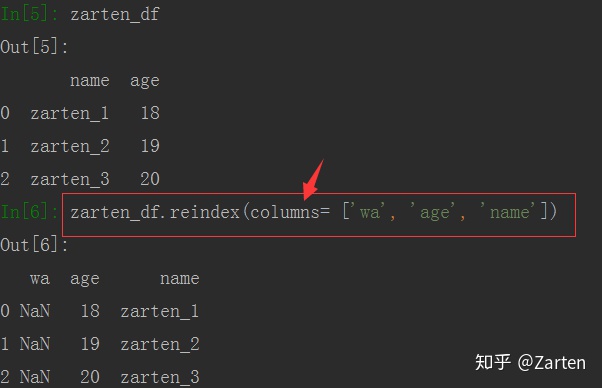
DataFrame也是一样的,若不指定,默认是重新排列行,若指定列,也可重新排序列。
import 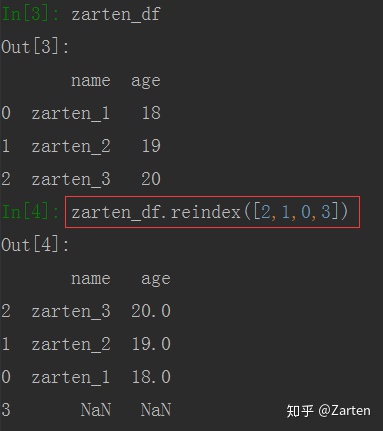
若需要重新排序列,只需指定参数columns即可
删除指定索引
删除指定的一个或多个索引及其对应的值,使用drop()方法,默认是产生一个新的对象,不会改变原有对象。
删除多个索引时传入一个列表
注意:若指定的索引不存在时,会报错
Series
import 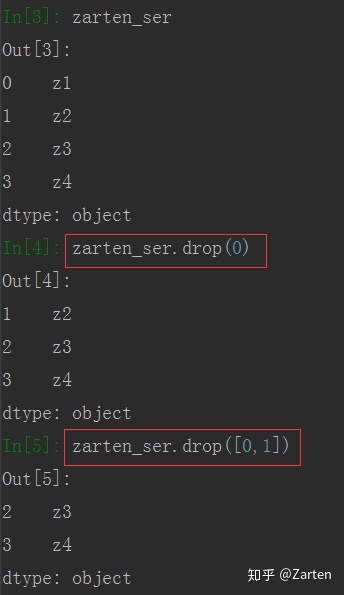
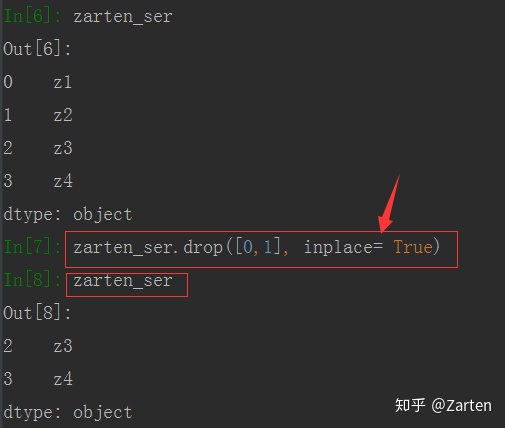
上面使用drop后都会产生一个新的对象,不会改变原对象。若想直接在原对象上进行删除,可以使用参数 inplace= True (慎用!!!)
DadaFrame
同样,默认是删除行,若要删除列索引及值,使用axis参数,axis默认为0代表行,1代表列
import 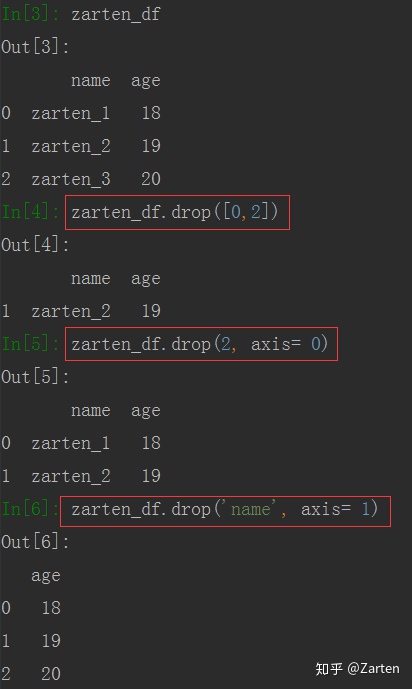
相同数据结构间的算术运算
相同的数据结构(Series和DataFrame)间的算术运算,跟并集的思想类似,也就是没有对应的索引时,会自动填充NaN
Series
import 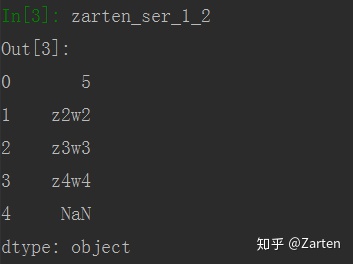
若想填充自己指定的值时,可以使用add方法,参数fill_value
import 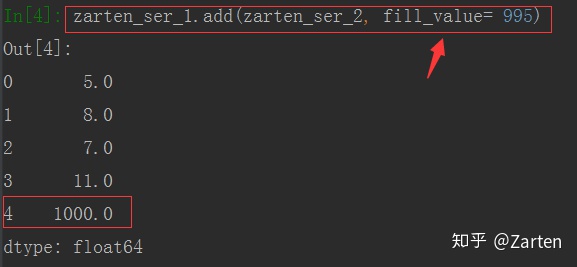
DataFrame
DataFrame数据结构算术运算时就比较刁钻了,必须是行和列索引都相同时才能相加,若有一个不同就是NaN
import 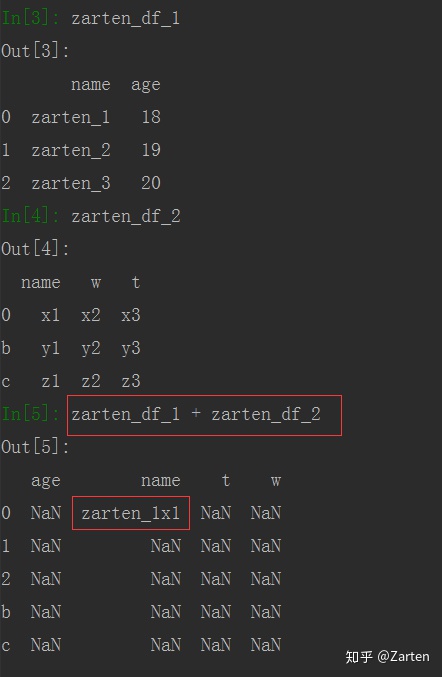
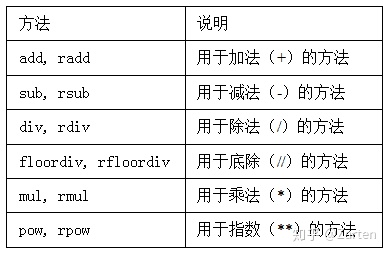
还有其他的一些算术运算如下图,这里将不再阐述,大同小异
Series与DataFrame之间的运算
这两者间的运算会广播到所有元素。
若互相都没有相同的索引时,同样会产生NaN
import 
从上图可以看到,DataFrame每一行都减去了Series。
更多的操作可以详细阅读官方文档。
排序
索引排序:
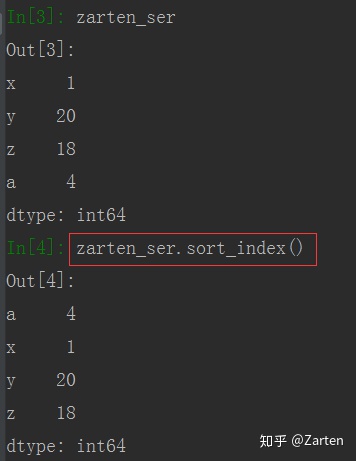
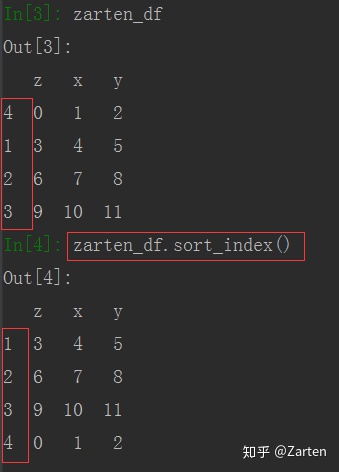
行或列索引排序,使用sort_index()函数,默认是行索引排序,且默认是升序
值排序:
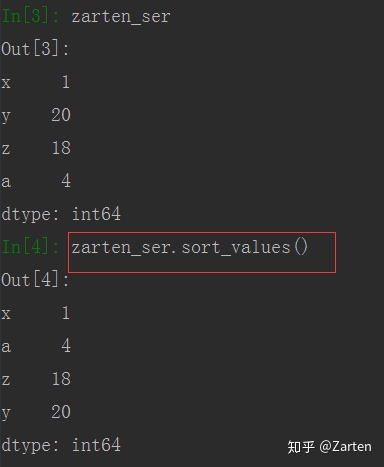
也可对值排序,使用函数sort_values()函数
Series
import 索引排序:
值排序:
DataFrame
import 索引排序:
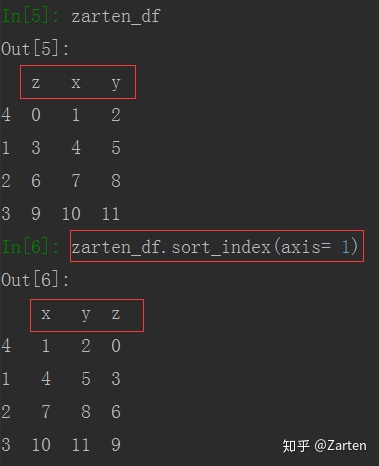
由上图可看到,默认为行索引排序,若需要列索引排序,只需指定axis=1 即可
值排序:
由于DataFrame是行和列组成,值排序是列的由上到下的排序,可指定一列或多列,通过by参数
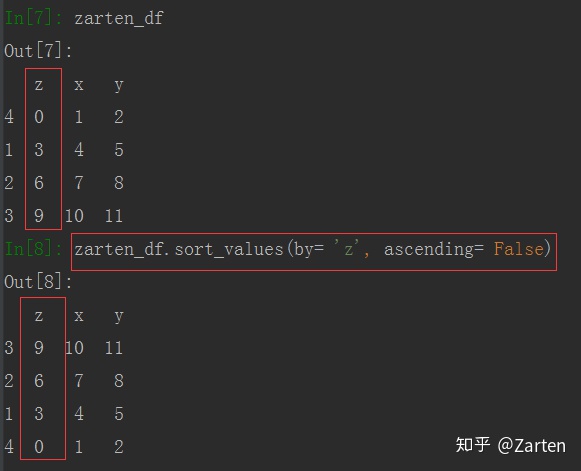
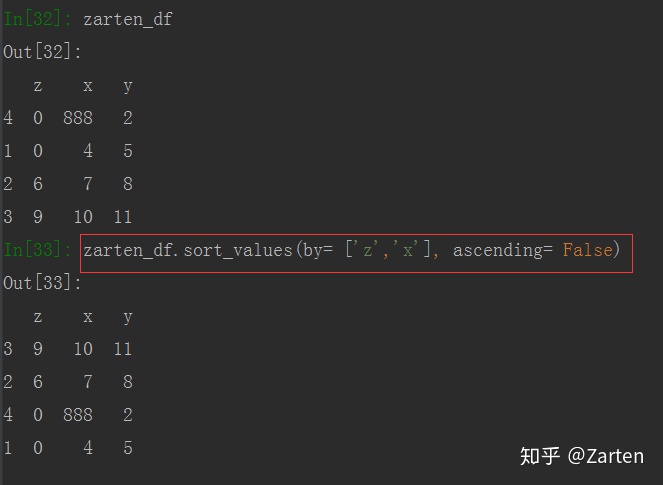
也可以进行多列排序,只需传入参数by一个列表即可。根据by指定的顺序优先排列
统计
下面将介绍一些常用的统计方法
求和
使用函数sum(),默认是每一列求和,可以通过参数axis来设置行或列,DataFrame的结果是一个Series对象
Series
import 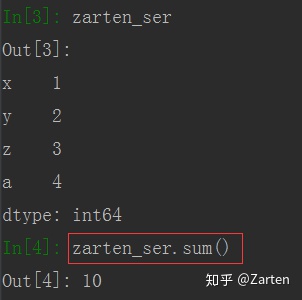
DataFrame
import 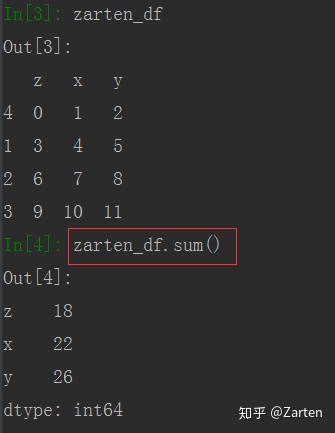
由上图可看到,求和默认是每列求和,若需要每行求和,可使用参数axis= 0
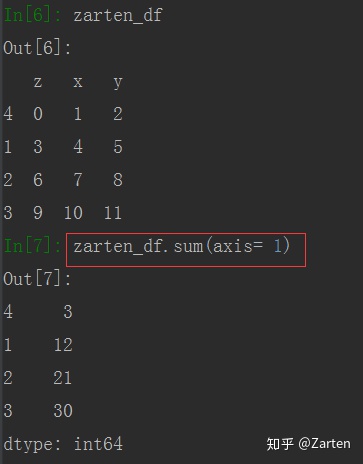
还有其他参数,如:若存在NaN时,默认结果会剔除NaN,可通过参数skipna设置。
其他参数如下图所示:

其他统计方法
比如比较常用的describe()函数,一次可以统计出多方面的信息
import 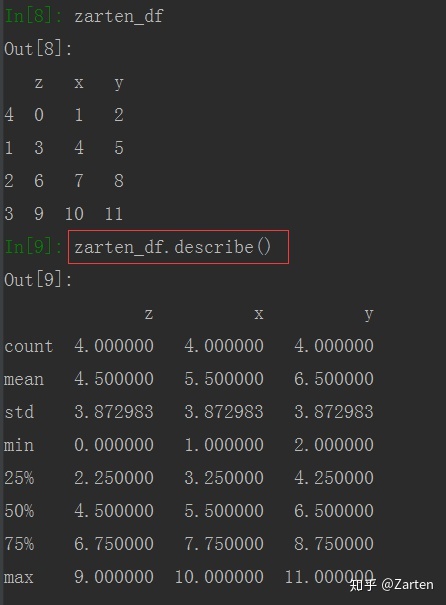
由上图看到,结果有多项,都是针对列而言,具体含义如下:
count : 计数(此列的总个数)
mean :平均值
std :标准差
min :最小值
25% :下四分位
50% :中位数
75% :上四分位
max :最大值
其他统计函数如下所示:

第三方库统计工具
第三方库:pandas-profiling
官方地址:pandas-profiling/pandas-profiling
自动生成全方位的统计信息















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









