






作者:高鹏
文章末尾有他著作的《深入理解 MySQL 主从原理 32 讲》,深入透彻理解 MySQL 主从,GTID 相关技术知识。
继上一篇文章:
MySQL:查询字段数量多少对查询效率的影响
我们继续来讨论一下 count(*)、count(字段)实现上的区别。注意我们这里都使用 Innodb 做为存储引擎,不讨论其他引擎。因为了有了前面的讨论,更容易看出它们的区别,这里我们有如下注意点:
- 我们需要做到执行计划一样,这里以全表扫描为例。实际上 count 很可能使用到覆盖索引(Using index),本文主要讨论它们实现的异同。
- count(*) 和 count(字段) 在结果上可能并不一致。比如 count(字段),但是某些行本字段为 NULL 的话那么将不会统计行数,下面将会说明这种 NULL 判断的位置。本文还是使用简单的全表扫描来进行对比实现上的区别。首先我们要明确的是 count 使用的是一个 COUNT 计数器。
一、使用示例
在示例中我们也可以看到两个语句的结果实际上并不一致。
mysql> show create table baguai_f G
*************************** 1. row ***************************
Table: baguai_f
Create Table: CREATE TABLE `baguai_f` (
`id` int(11) DEFAULT NULL,
`a` varchar(20) DEFAULT NULL,
`b` varchar(20) DEFAULT NULL,
`c` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> select * from baguai_f ;
+------+------+------+------+
| id | a | b | c |
+------+------+------+------+
| 1 | g | g | NULL |
| 1 | g1 | g1 | g1 |
| 3 | g2 | g2 | g2 |
| 4 | g | g | NULL |
| 5 | g | g | NULL |
| 6 | g3 | g3 | g3 |
+------+------+------+------+
6 rows in set (0.00 sec)
mysql> desc select count(*) from baguai_f where b='g';
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | baguai_f | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 16.67 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> desc select count(c) from baguai_f where b='g';
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | baguai_f | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 16.67 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> select count(*) from baguai_f where b='g';
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> select count(c) from baguai_f where b='g';
+----------+
| count(c) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)这种不一致来自于 b='g' 的 c 列中都是 NULL 值,因此 count(c) 返回为 0。
二、示例中 count(*) 获取数据流程简析
注意在《MySQL:查询字段数量多少对查询效率的影响》一文中我们已经详细的描述了部分流程,这里不再赘述,如果需要更加详细的了解,自行参考。
1. MySQL 层 构建 read_set
这里构建的 read_set 实际上只会包含列b,即一个字段。
2. Innodb 层 构建模板
同理根据 read_set 构建的字段模板中只会包含列b。LOOP:这里开始循环返回每一条数据
3. Innodb 层 根据模板返回数据
这里我们可以看看模板的数量和模板对应的具体列名
- 模板的数量
断点:row_sel_store_mysql_rec
查看模板数量:
(gdb) p prebuilt->n_template
$1 = 1- 查看模板对应的字段
断点:row_sel_field_store_in_mysql_format_func
查看模板对应的字段:
(gdb) p field->name
$3 = {m_name = 0x7ffe7c99cf85 "b"}显然这里只是将 b 列的值返回给了 MySQL层,这里也很好理解,因为 b 列在 MySQL 层需要继续做过滤操作。
4. MySQL 层 过滤条件 b='g'
好了,当前返回给 MySQL 层的数据中只有 b 列的数据,然后施加 b='g' 这个条件进行过滤。
5. MySQL 层 过滤后做一个 COUNT 计数操作
对于普通的 select 语句过滤后的数据就可以返回了,但是对于 count 这种操作,这里做的是一个计数操作,其中行会对 count 字段的 NULL 值进行判断,当然这里是 count(*) 也就不存在 NULL 值判断了,下面是这段代码:
bool Item_sum_count::add()
{
if (aggr->arg_is_null(false))
return 0;
count++;
return 0;
}END LOOP
最终我们只需要返回这个计数就可以了。下面是发送的数据,断点可以设置在 Query_result_send::send_data 中。
$22 = Item::SUM_FUNC_ITEM
(gdb) p ((Item*)(items)->first->info)->field_type()
$23 = MYSQL_TYPE_LONGLONG
(gdb) p ((Item*)(items)->first->info)->val_int()
$24 = 3
(gdb) p (items)->first->info
$26 = (void *) 0x7ffe7c006580
(gdb) p ((Item_sum_count*)$26)->count
$28 = 3我们可以发送的数据实际就是这个计数器,最终值为 3。
三、示例中 count(c) 获取数据流程的不同
实际上整个流程基本一致,但是区别在于:
- 构建的 read_set 不同,模板个数自然不同,因为需要 2 个字段,即 b、c 两个字段,其中 b 列用于 where 条件过滤,而 b 列用于统计是否有 NULL 值,因此模板数量为 2,如下:
(gdb) p prebuilt->n_template
$29 = 2- 做 COUNT 计数器的时候会根据 c 列的 NULL 值做实际的过滤,操作只要是 NULL 则 count 计数不会增加 1,这个还是参考这段代码:
bool Item_sum_count::add()
{
if (aggr->arg_is_null(false)) //过滤NULL值
return 0;
count++;
return 0;
}最终会调入函数 Field::is_null 进行 NULL 值判断,断点可以设置在这里。
四、不同点总结
示例中的语句 count(c) 返回为 0。现在我们很清楚了,这些数据什么时候过滤掉的,总结如下:
- Innodb 层返回了全部的行数据。
- MySQL 层通过 where 条件过滤,剩下了 b='g' 的行。
- MySQL 层通过 NULL 判断,将剩下的 count(c) 中为 NULL 的行也排除在计数之外。
而 count(*) 则没有第 3 步,这是一个不同。
然后的不同点就是在返回的字段上:
- count(c) 很明显除了 where 条件以外,还需要返回 c 列给 MySQL 层
- count(*) 则不需要返回额外的字段给 MySQL 层,只需要 MySQL 层过滤需要的b列即可。
通过上面的分析,实际上效率没有太大的差别,我觉得同样执行计划,同样返回数据结果的前提下,可能 count(*) 的效率要略微高一点。
五、备用栈帧(下图需点击放大查看)
NULL 值计数过滤栈帧
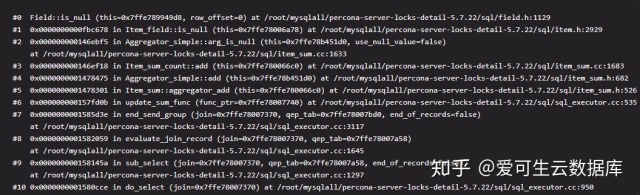
最后推荐高鹏的专栏《深入理解 MySQL 主从原理 32 讲》,想要透彻了解学习 MySQL 主从原理的朋友不容错过。















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









