







这一节我们介绍一下分组匹配。
import re
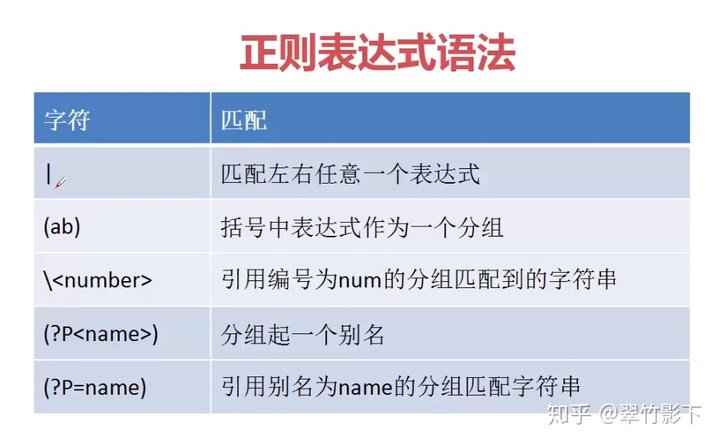
# | 匹配左右任意一个表达式
ma = re.match(r'abc|d', 'abc')
print(ma.group()) # 输出:abc
ma = re.match(r'abc|d', 'd')
print(ma.group()) # 输出:d
# () 括号中的表达式作为一个分组
# 例:匹配163邮箱或126邮箱
ma = re.match(r'[w]{4,10}@(163|126).com', 'lianflower@163.com')
print(ma.group()) # 输出:lianflower@163.com
ma = re.match(r'[w]{4,10}@(163|126).com', 'lianflower@126.com')
print(ma.group()) # 输出:lianflower@126.com
# <number> 引用编号为number(数字)的分组所匹配到的字符串
# 例:匹配html标签的有效性
ma = re.match(r'<[w]+>', '<book>')
print(ma.group()) # 输出:<book>
ma = re.match(r'<([w]+>)', '<book>') # 注意这里分组匹配的范围为([w]+>) 没有左边的<
print(ma.groups()) # 输出:('book>',) # 当我们在正则表达式中使用()进行分组匹配时。
# 那么我们可以使用groups以元组的形式输出匹配结果
ma = re.match(r'<([w]+>)1', '<book>book>') # 1用来引用分组([w]+>)所匹配到的字符串book>
print(ma.group()) # 输出:<book>book>
ma = re.match(r'<([w]+>)</1', '<book></book>')# 在1前加上字符</就可以匹配出</book>
print(ma.group()) # 输出:<book></book>
ma = re.match(r'<([w]+>)[w]+</1', '<book>python</book>')# 再加上[w]+后,可以匹配一个完整的html标签
print(ma.group()) # 输出:<book>python</book>
# (?P<name>) 为分组起一个别名(因为一个正则表达式中可能有多个分组,
# 所以起个别名在引用的时候会比较方便)
# (?P=name) 引用名为name的分组所匹配到的字符串
ma = re.match(r'<(?P<song>[w]+>)[w]+</(?P=song)', '<book>python</book>')
print(ma.group()) # 输出:<book>python</book>
# (?P<song>[w]+>)意思为:为分组([w]+>)起一个别名为song
# (?P=song)意思为:引用名为song的分组所匹配到的字符串














 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









