






文章目录
1.什么是正则表达式?
正则表达式就是用某种模式去匹配字符串的一个公式,通过他的语法可以快速的定位、提取、处理一些文本内容
一个小例子
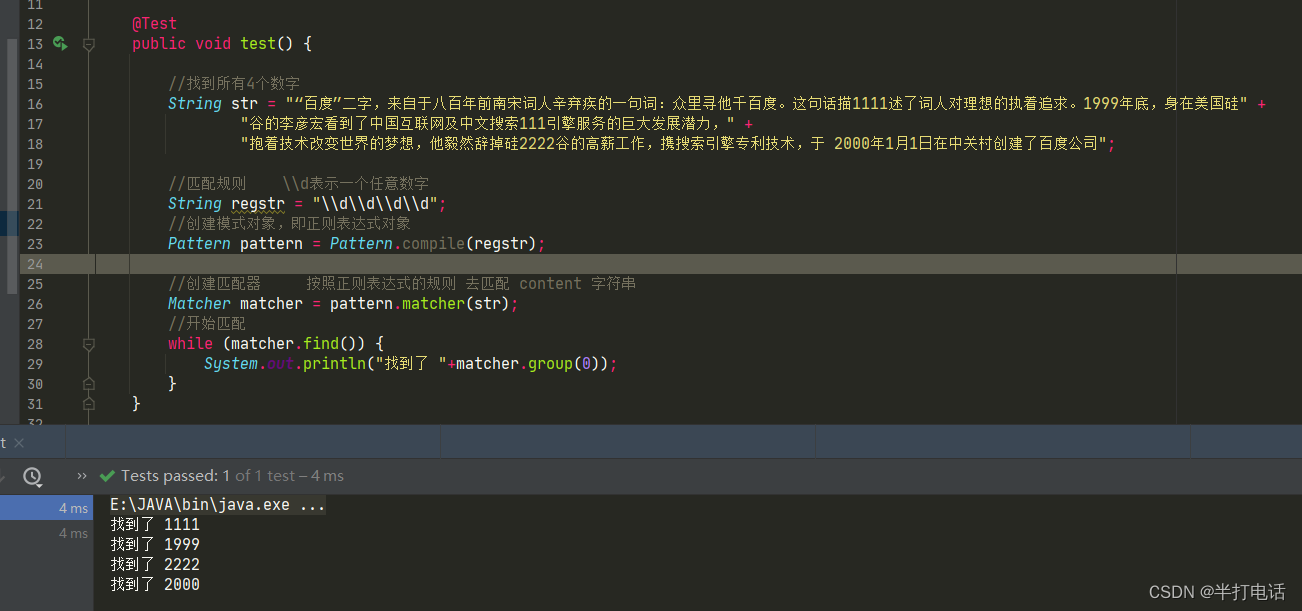
- 找到文本中连续4个数字的部分
2.正则表达式语法
分类

转义号

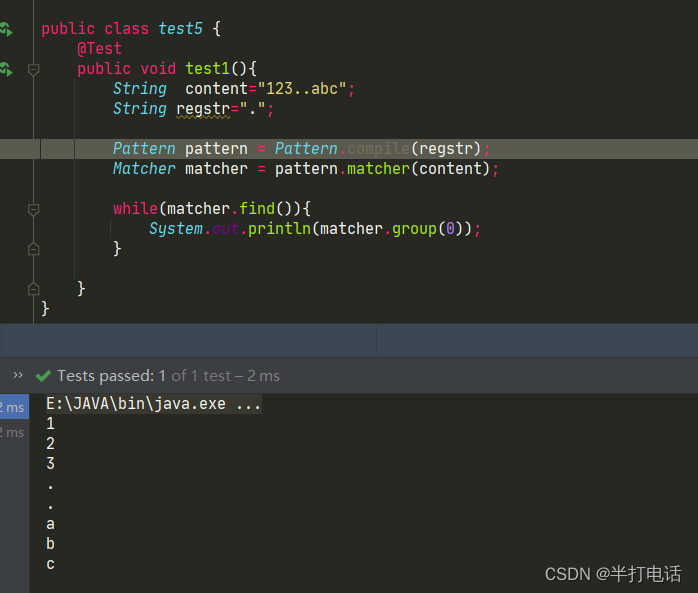
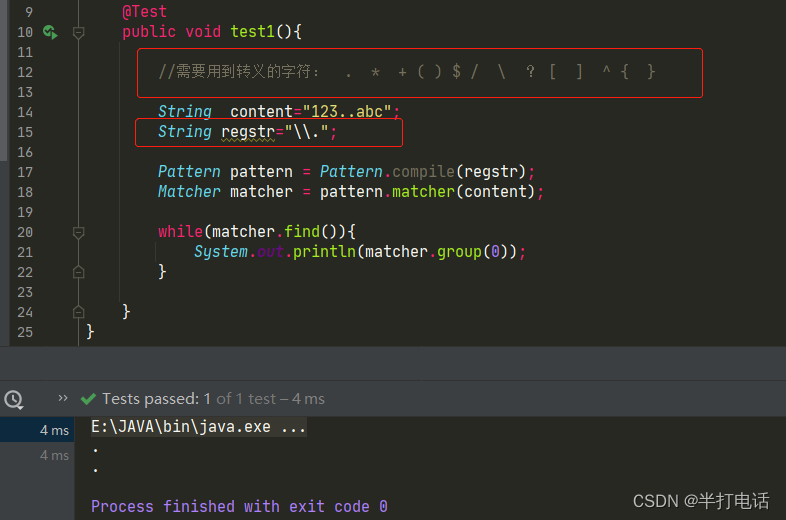
- 就比如说 “ . ”在正则表达式中的语法表示 除了 \n 以为的任意字符,但如果说你就像匹配 “ . ” 那么就需要用转义符
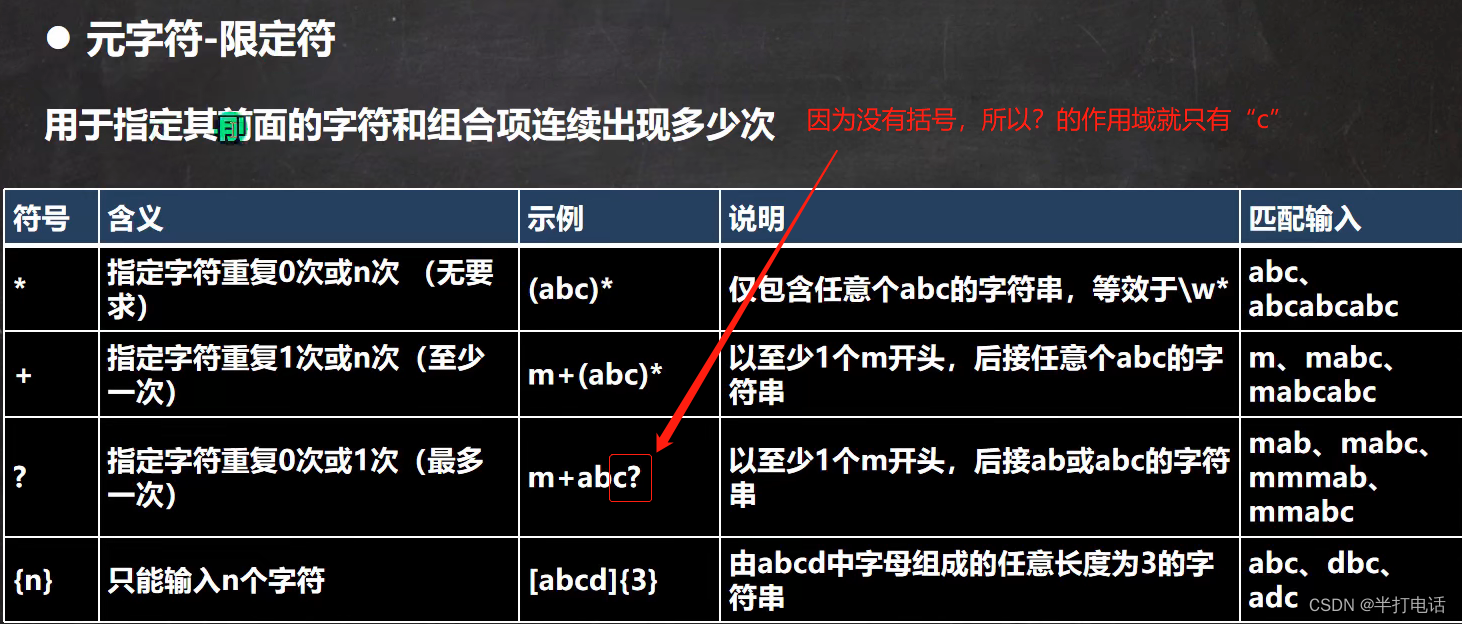
限定符

字符匹配符




选择匹配符

定位符

分组、捕获、反向引用



例题:结巴程序
public void test(){
//将这段结巴话语用正则表达式修改成不结巴的
String content="我...要开....开飞飞飞飞机";
//1.去掉。。。
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
String str = matcher.replaceAll("");
System.out.println(str);//我要开开飞飞飞飞机
//去掉重复字符
Pattern pattern1=Pattern.compile("(.)\\1+");//找到所有具有重复字符的字符串
Matcher matcher1 = pattern1.matcher(str);
while(matcher1.find()){
System.out.println(matcher1.group(0));//开开 飞飞飞飞
}
String str2 = matcher1.replaceAll("$1");//用分组的字符替换掉
System.out.println(str2);//我要开飞机
}
例题

@Test
public void test1(){
//汉字
// String content="abc章鱼哥123";
// String regstr="[\\u0391-\\uffe5]+";
//1-9开头的6位数
// String content="123456";
// String regstr="^[1-9]\\d{5}$";
// 必须以13,14,15,18开头的11位数
// String content="15111111111";
// String regstr="^1[3|4|5|8]\\d{9}$";
//判断url
String content="http://edu.3dsmax.tech/yg/bilibili/my6652/pc/qg/05-51/index.html"+
"#201211-1?track_id=jMc0jn-hm-yHr"+
"NfVad37YdhOUh41XYmjlss9zocM26gspY5ArwWuxb4wYWpmh2Q7GzR7doU0wLkViEhUlO1qNtukyAgake2jG1bTd23lR57XzV83E9bAXWkStcAh";
String regstr="^(http|https)://([\\w-]+\\.)+[\\w]+[\\/[\\w-?=&/%.#]*]+$";
Pattern pattern = Pattern.compile(regstr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println(matcher.group(0));
}
}
3.源码解析
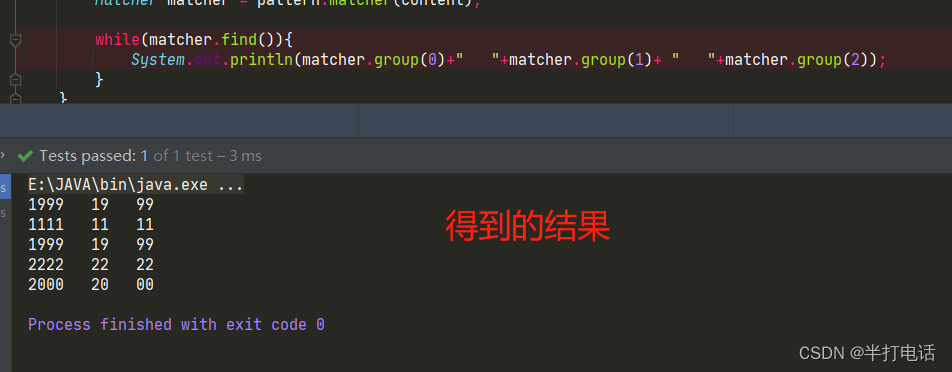
String content="1999百度”二字,来自于八百年前南宋词人辛弃疾的一句词:众里寻他千百度。这句话描1111述了词人对理想的执着追求。1999年底,身在美国硅" +
"谷的李彦宏看到了中国互联网及中文搜索111引擎服务的巨大发展潜力," +
"抱着技术改变世界的梦想,他毅然辞掉硅2222谷的高薪工作,携搜索引擎专利技术,于 2000年 1月1日在中关村创建了百度公司";
//匹配连续4个数字的字符串
String regstr="\\d{4}";
Pattern pattern = Pattern.compile(regstr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println(matcher.group(0));
}
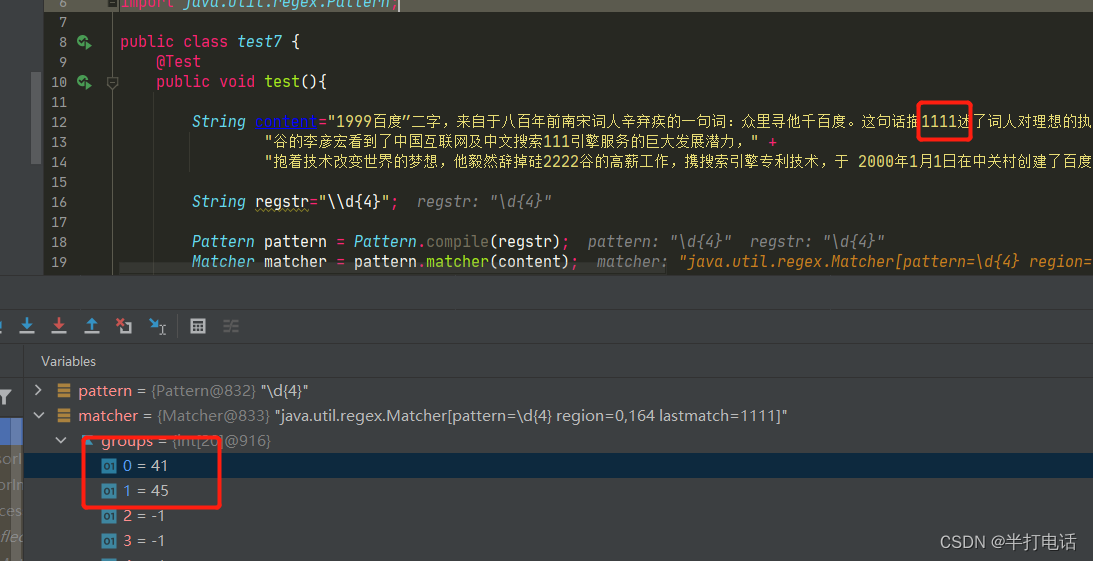
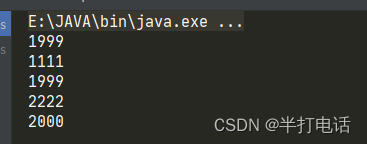
- matcher.find( )的作用:根据regstr指定的规则,去匹配字符串(例如:1999)
- 调用该方法时,会在底层创建一个int【20】的数组,用于存放匹配到的字符串索引,默认初始值为-1

- 当匹配到符合的字符串时,会存放该字符串的索引下标记录到数组中,groups[0]=0,groups[1]=3+1

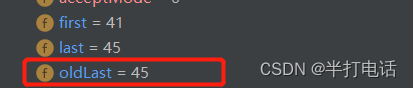
- 同时,会记录下字符串结束位(4)到oldLast中,那么下次匹配字符串时就是从索引为4的位置开始

- 截取完这个字符串,那么就会继续寻找下一个符合条件的字符串
- 当找到下一个符合要求的字符串时,就会覆盖groups[0]和group[1]的值,同时更新oldLast
- find()获取指定字符串的索引就是为了配合matcher.group(0)该方法的使用
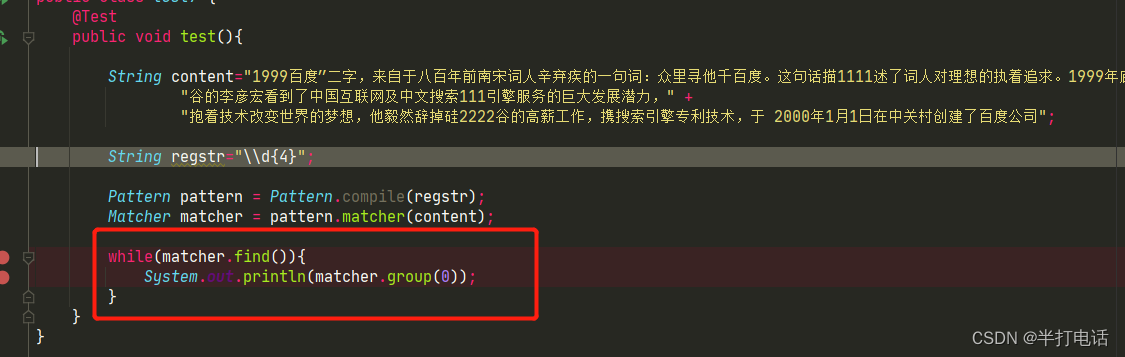
- 因为传入的值为0,那么就是说每一次截取的下标都是0,1,而group[0]、group[1]前面也说到了,就是存放符合字符串的索引,就是验证了该方法的输出
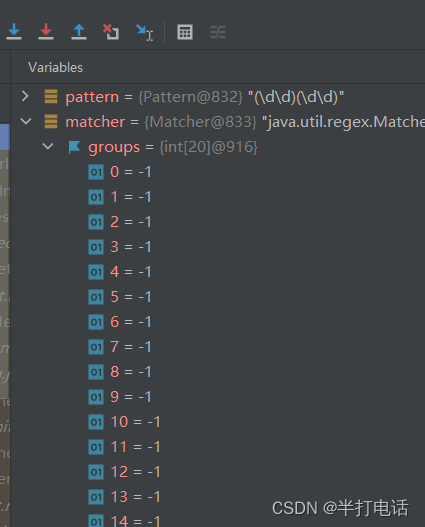
- 底层创建的20个位置的groups也不是没有用到的时候,他弄这么大的原因就是为了解决分组的问题
- 接下来修改一下题目

- 刚开始还是创建一个int【20】的数组,初始值还是-1
- 但是当匹配到对应字符串的时候,数组后面的位置就开始起作用了,因为我加了2个() ,就代表着分了2组,groups[2]、groups[3]就正好代表着第一个分组的开始、结束下标,groups[4]、groups[5]就正好代表着第二个分组的开始、结束下标。
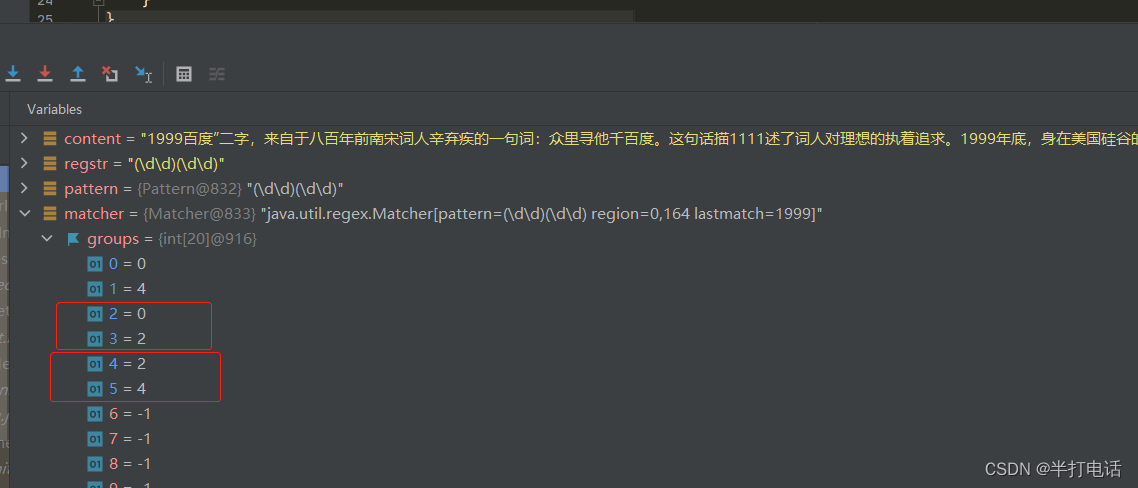
- 第二个匹配字符串

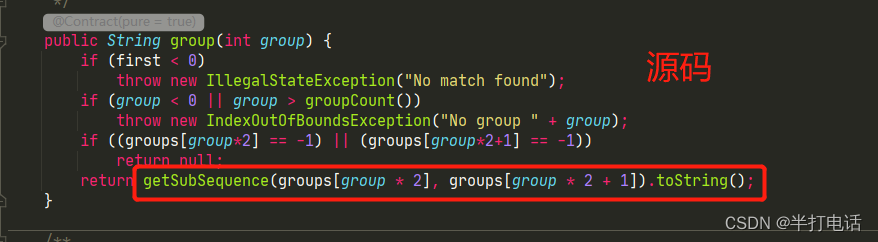
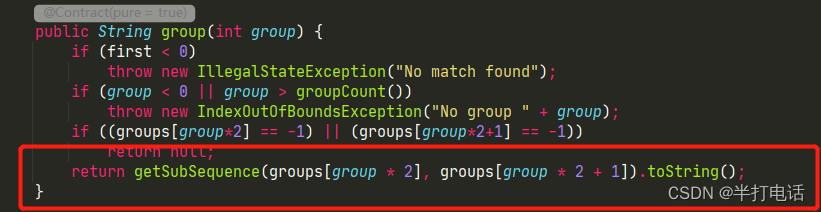
- 还记得matcher.group()的源码吗?
- 此时当填入的grous值不是0,而是1时,换算过来对应的就是groups[2]、groups[3],这个就正好是第一个分组对应的开始、结束下标
- 当值为2时,对应groups[4]、groups[5],就是第二个分组的下标,以此类推。。。。

4.Matcher、Pattern、PatternSyntaxException介绍

Marcher的常用方法

5.String中也提供了一些可以调用正则表达式的构造器
| 名称 | 作用 |
|---|---|
| public String replaceAll(String regex,String replacement) | 替换指定字符串 |
| public boolean matches(String regex) | 判断是否符合 |
| public String[] split(String regex) | 以指定字符为分界线 |















 3662
3662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









