





引言
随着时代的发展,我国在各行各业都需要大量的人才引进,处于近几年最热门的行业也称“最火行业”:大数据、数据分析、数据挖掘、机器学习、人工智能,这五门行业各有不同又互有穿插。近几年在实现信息科技化的推动,大数据等行业迅速发展,本文探索大数据、数据分析、数据挖掘等与数据有关行业的招聘信息,分析其岗位、薪资、学历、技能等要求,研究其招聘特点,本文主要针对的用户为本科、研究生、博士生学历的在读生或毕业生以及在职人员提供求职信息,为用户提供选择,尽早的了解目标行业新动态、新要求,尽早做好职业规划。
由于各行各业需要大量引进大数据相关人才,在线上、线下都在火热招聘,用户每天面对如此大量繁琐的招聘信息,一时间无法提取出自己所需信息,为方便用户获取自身所需职业岗位的信息,本文利用Python网络爬虫,爬取前程无忧网站全国范围内与数据相关岗位的招聘信息,其中爬取的信息包含有:职位名、公司名、工作地点、薪资、发布时间、职位职责或任职要求以及学历等职位信息。通过Pandas、re库的正则表达式处理爬取数据,包括数据清洗(缺失值处理、异常值处理),数据变换(规范化、一致化),再导入Excel文件中存储信息,在利用Excel数据分析能力对数据进行了初步数据分析和处理,再将其导入DataFrame进行画图进行数据可视化,得出了数据类岗位的相关信息供用户所需。
挖掘目标:
挖掘前程无忧网的招聘信息,对职位名、公司名、工作地点、薪资、发布时间、职位职责或任职要求等职位信息进行挖掘,把分析的数据提供给求职人员或准备求职人员做参考,本文围绕以下三个目标进行挖掘和分析:
- 目标1:提取各个岗位的薪资和学历信息,分析其不同岗位的薪资、学历等信息研究其薪资和学历是否有潜在或显在关系:。
- 目标2:提取不同区域、行业的招聘信息,分析比较不同区域、行业对相关人才的需求情况。
- 目标3:提取不同岗位的职业技能的数据,分析比较不同岗位的技能要求,找出当前最热门的技能Top10。
分析方法与过程
首先,我们爬取前程无忧网站(https://www.51job.com/)全国范围内有关大数据、数据分析、数据挖掘,等相关岗位的招聘信息,搜索关键字为“数据”,要求信息包含有:职位名、公司名、工作地点、薪资、发布时间、职位职责或任职要求等职位信息。我们对爬取信息进行预处理包括数据清洗,数据集成和数据变换,用pycharm对原始数据进行抽取,抽取出各个岗位的信息到Excel表,再用Excel初步分析和筛选其数据特征,利用pandas库和matplotlib库画图,将数据可视化。主要步骤如下:
- 从前程无忧网站中获取有关“数据”类的岗位数据包括:岗位名称、公司名称、工作地点、薪资、发布时间、职位职责、学历要求。
- 对数据进行预处理,包含数据去重,数据删选,数据规范化,数据分类等处理过程。
- 对不同的目标所需数据进行提取,再次进行数据处理过程,将数据进行可视化。
- 对可视化后的数据进行分析和得出结论
本文的研究框架如下:
数据获取----数据预处理----数据特征提取----数据处理----数据可视化----分析数据——得出结果
数据处理过程
- 数据获取

由于所需数据量较大,本组利用python的网络爬虫访问前程无忧网,爬取页面信息,爬取数据放入pandas的数据框存储。
在爬取网页数据的时候,我们一开始会遇到一些问题:
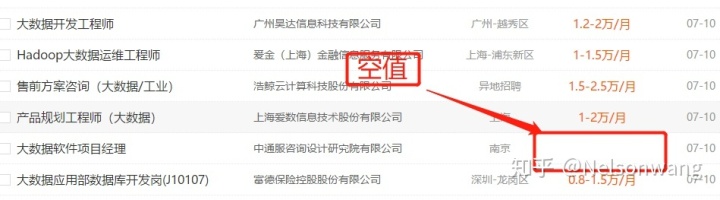
这样的空值如果直接访问网站标签属性值的text部分,默认把空的跳过,把下一个数据插入列表中,也就是上图中原本大数据软件项目经理的薪资是空,变成了0.8-1.5万/月,因此我们爬完信息后带入数据框就会显示出错,原因就是长度不一,解决方法:先获取属性值,在用for循环把属性值的text文本一次添加到列表,这个时候原本text为空的属性值就会把None添加进新的列表中,此时的列表长度就一致了。
代码如下

这样就可以人薪资的长度和工作地点的长度一致,就可以导入数据框中了。再利用数据框的索引操作把空值的一行索引出来并且删除就完成了去除空值的过程。
- 数据预处理
在数据挖掘中,海量的原始数据存在着大量不完整、不一致、有异常的数据,严重影响到数据进一步提取信息,因此要对所获取的数据进行预处理操作,数据预处理包括:数据清洗、数据集成、数据变换、数据规约。
2.1数据清洗
数据清洗主要是删除原始数据集中的无关数据、重复数据、平滑噪声数据,筛选掉与数据挖掘主题无关的数据,处理缺失值、异常值等。
2.1.1缺失值、异常值处理
处理缺失值、异常值通常的方法有3种:删除记录、数据插补、不处理
本文数据挖掘的数据有缺失值,主要呈现在薪资上和工作描述上,部分岗位有出现未显示薪资或者是非常大,不符合逻辑的数据,工作描述上的主要呈现是没有描述既描述为空,针对这类的问题,由于前程无忧数据庞大,我们获取了5.5万条数据,只需要5万条,因此本组直接把这类缺失、异常的数据删除,首先在爬虫爬取HTML网页数据,利用xpath方法找出需要的数据,再存入列表,索引出空值并且补上为None,最后将多个列表如岗位名称、工作地点、薪资待遇等合成数据框,再通过DataFrame索引出None的这一列并且删除,删除后的数据为5.1万左右。.
2.2数据集成
数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存在一个一致的数据存储中的过程。
事实上,数据集成就是将不同数据格式变成相同格式的数据、将单位不一致的数据变成单位一致、同名异义或者异名同异的数据源检测出来归类的过程。
2.3数据变换
数据变换主要是对数据进行规范化出来,将数据转化成“适当的”形式,以适用于数据挖掘任务和算法要求。
本组获取的数据中的薪资出现了单位不一致,有些数据是千/月,有些是万/月,因此要将其变成统一单位,本组选取千/月做为标准单位,在Excel表格中将薪资数据全部统一单位为千/月。
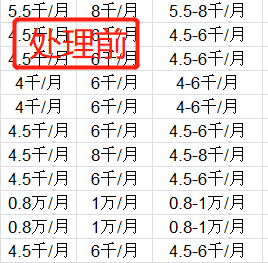
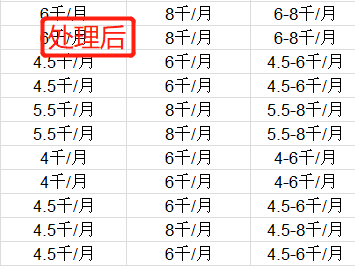
上图可见,未处理的数据中有万/月和千/月两种单位,但是我们需要同一变量,因此下面要进行单位统一化Excel处理:
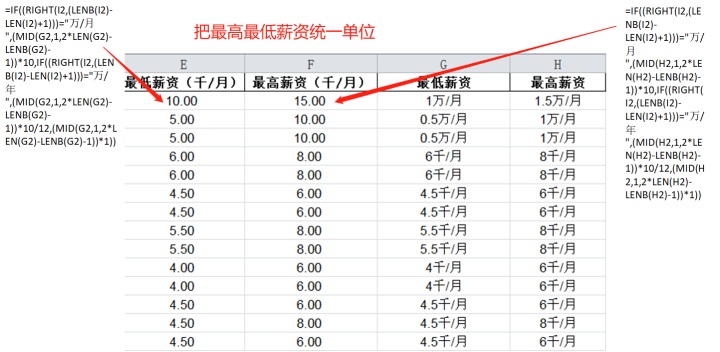
其思想是找表格的内容,如果存在“万/月的”就提起其数字乘以10就变成了千/月的单位,如果存在“万/年”的就提起数字乘以10除以12,就变成了千/月的单位。
数据可视化与分析
由于数据量总计有5万多条,不能一一展示,本文只选取岗位数量排名前10的岗位数据展示。
3.1 对目标1的数据可视化:
- 目标1:提取各个岗位的薪资和学历信息,分析其不同岗位的薪资、学历等信息研究其薪资和学历是否有潜在或显在关系:。
首先展示的是前10个需求最大的岗位的薪资情情况

从岗位数量需求来看,Java开发工程师、新媒体运营专员、产品经理等这10个岗位是在数据类岗位占数量最多的,说明这几个岗位在数据类行业中比较热门。
用wordcloud展示热门岗位信息:

从整体平均工资的最高与最低观测一下数据:
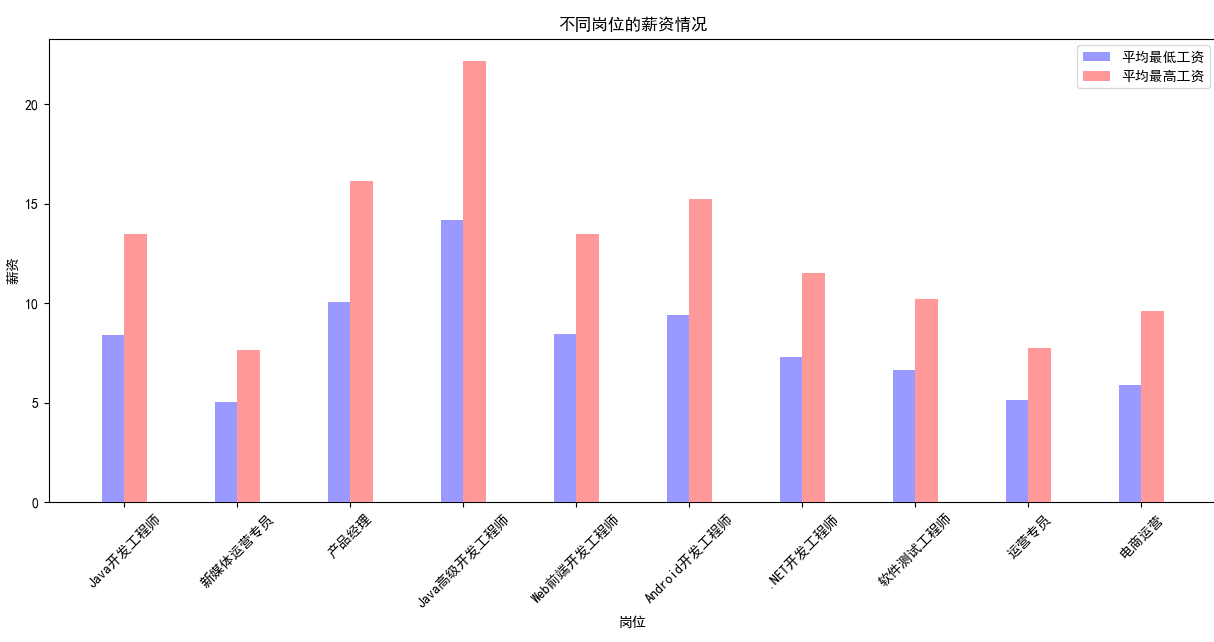
上图可以看出java高级开发工程师的平均最高工资和最低工资都比其他岗位要高。
从最高薪资来看:
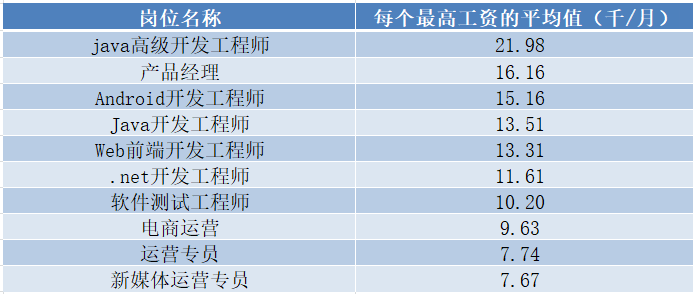
Java高级开发工程师平均每个月最高可以拿到接近22k/月的薪水,而新媒体运营专业平均最高只能拿到7.67k/月,排名前五的薪水比较高,其技术能力也要求较高,因此你的技术能力也是决定了你的薪资高低。
从薪资区间来看:
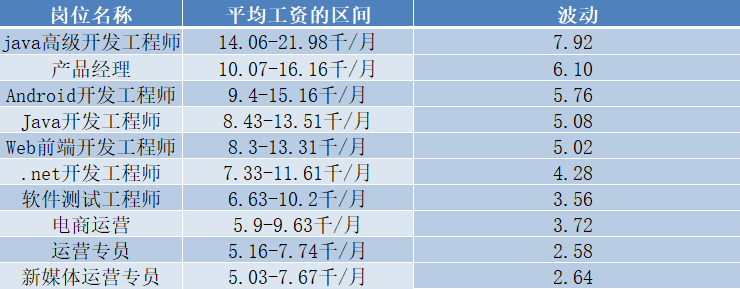
其薪资波动最大的是java高级工程师,波动较小的是新媒体运营专员,我们有理由大胆猜测,技术含量大的薪资都较高,需求也大,但同时由于竞争的关系,其薪资波动也相对较大。
从学历在“数据类”岗位中的比重来看:
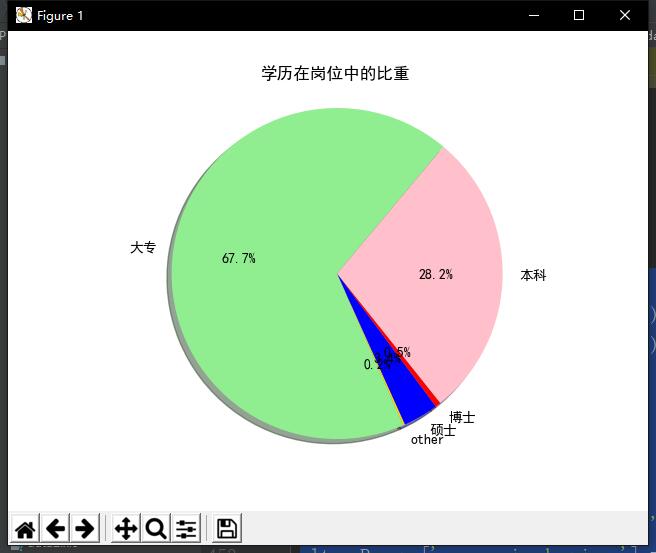
其中大专占67.7%,本科占28.2%,而硕士、博士和其他一共占4.1%,说明大专和本科是数据岗位的主力军,企业在招聘这类岗位的时候更注重的是员工的技术能力,对学历要求不是很大。
3.2对目标2的数据可视化:
- 目标2:提取不同区域、行业的招聘信息,分析比较不同区域、行业对相关人才的需求情况。
首先现看一组数据:
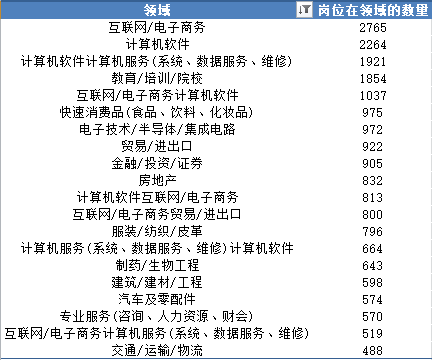
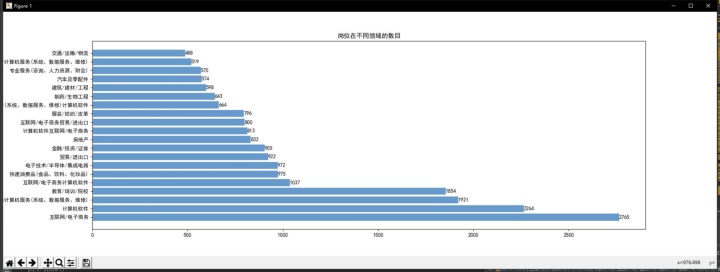
从上图“数据类”岗位在不同行业领域的分布情况来看,数据类的岗位在互联网/电子商务、计算机软件、计算机服务这几个行业领域中需求最多,其中互联网/电子商务行业领域遥遥领先,说明该领域对数据的人才需求量大。因此如果想要从事数据类工作的求职者可以根据自己喜好在这几个领域深耕。
得知各行业领域对人才的需求之后,我们还想得前10个岗位对各城市的需求:
下面是对其前10个岗位在各城市的需求排名分布:
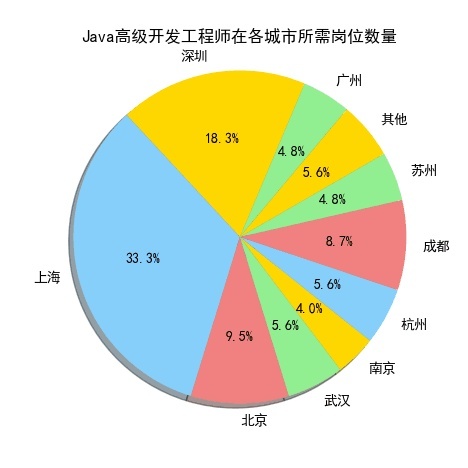
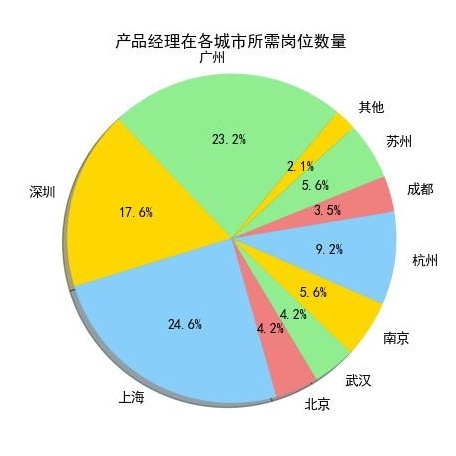
先看图:Java高级工程师和图:产品经理是薪水排名前10中最前的两个,占比重较大的是上海、广州、和深圳这三个城市,我们再看一下其他的岗位:
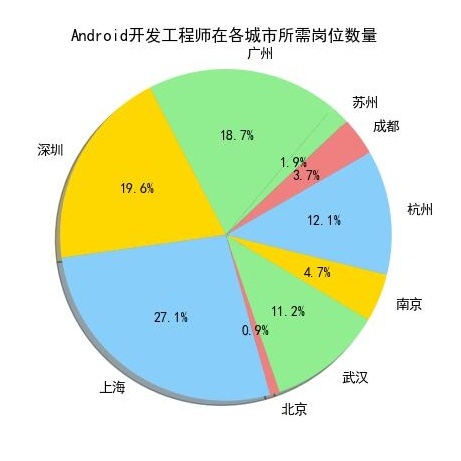
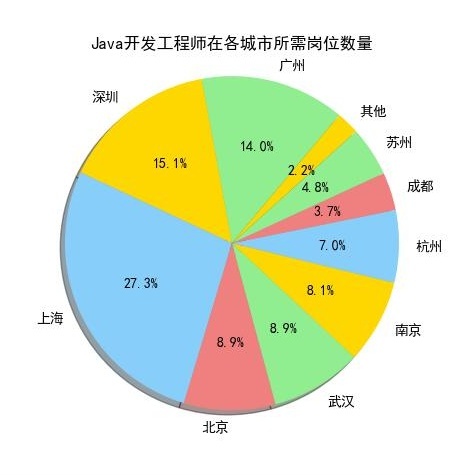
Android开发工程师和Java开发工程师也是分布在上海、深圳、广州这三个城市中较多。
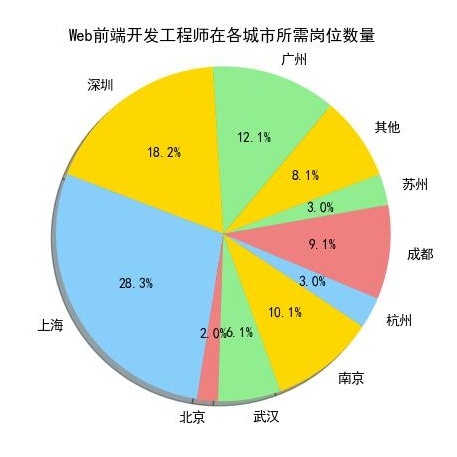
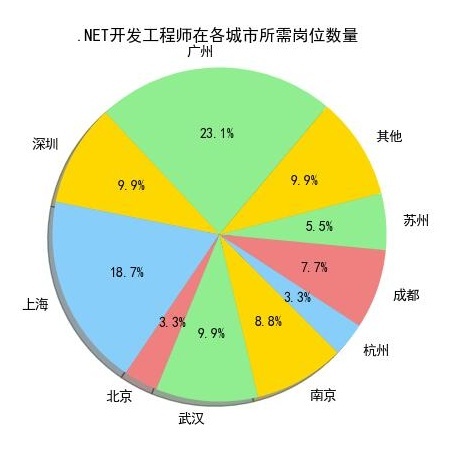
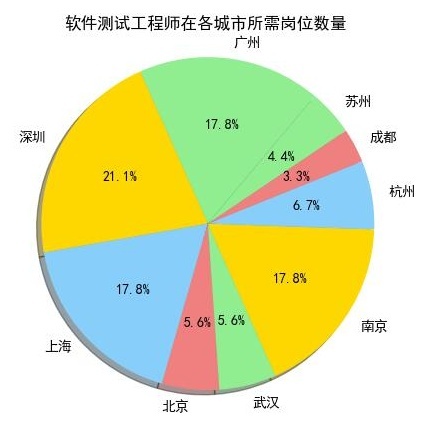
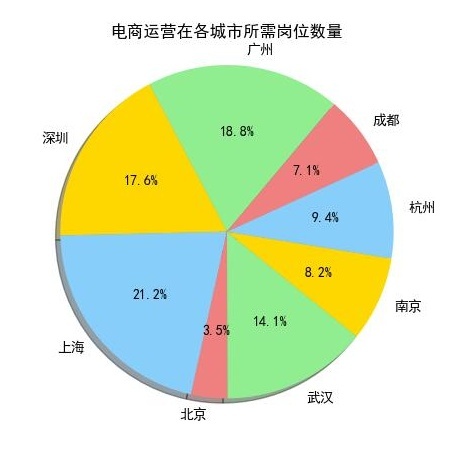
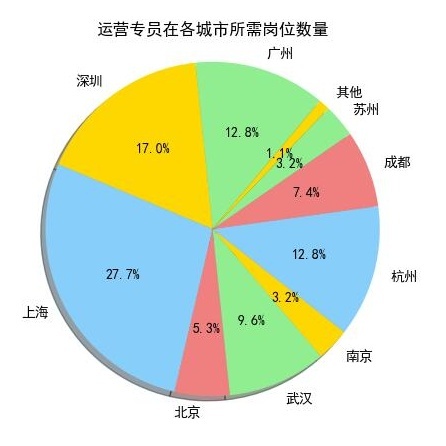
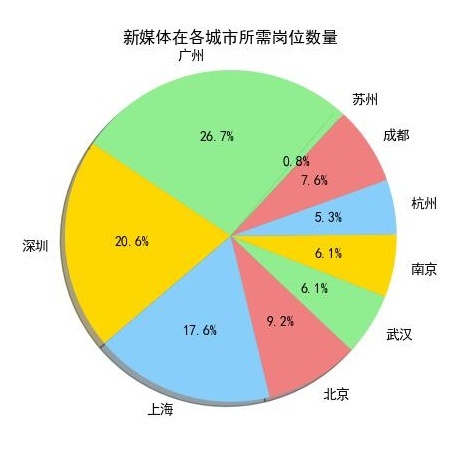
从上10个图中我们可以看出,薪资排名前10个岗位在上海、广州、深圳这三个城市所需求人才的人数,相对其他城市而言是占一个比较大的比重。
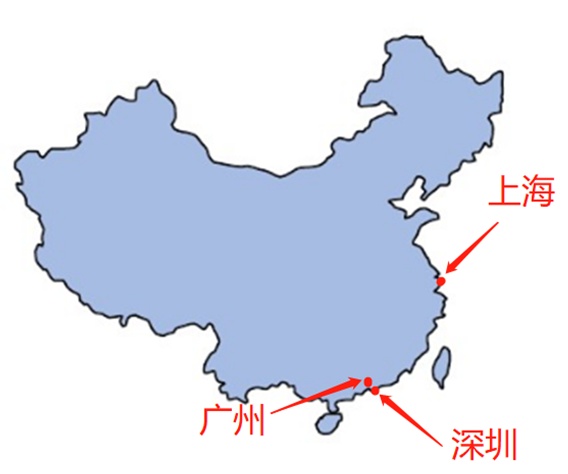
我们来看一下上海、广州、深圳的地理位置(上图),看到的是上海、广州、深圳都是沿海地区,并且在国内属于一线城市中经济高度发达地区,这与广州、深圳、上海的互联网高度发展有关,这也是这几个城市互联网行业等领域的人才需求占比较高的原因。
3.3对目标3的数据可视化:
- 目标3:提取不同岗位的职业技能的数据,分析比较不同岗位的技能要求,找出当前最热门的技能Top10。
首先提取前10热门岗位的职业技能数据:
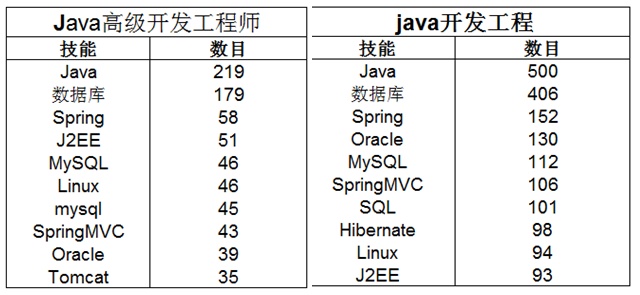
上图可知,要从事java开发工程师的职位需要技能都差不多有Java、数据库、Spring、J2EE、Linux等开发语言和数据库。
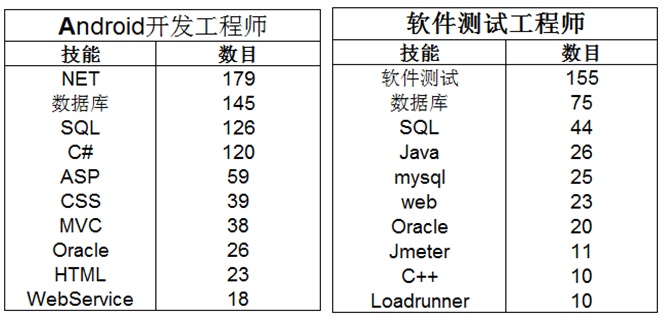
上图可知,从事Android开发工程师就最火技能就是NET和数据库和C#,而软件测试工程师最火的是软件测试,并且高度突出,因此软件测试工程师必须要学会软件测试这个技能还有一些数据库技能,否则很难再这个职业立足!
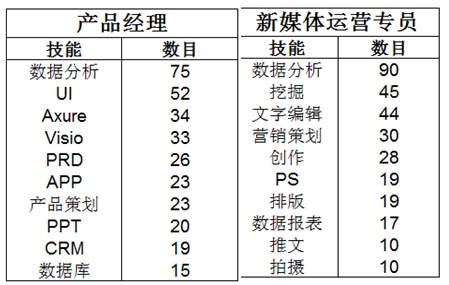
上图可知,现在来看产品经理的所需技能,第一个是数据分析能力,说明随着数据信息化的发展,产品经理需要对数据有强烈的敏感性,有一点的数据分析能力才是产品经理应用有的技能。而新媒体运营专员也需要数据分析和挖掘的能力,说明现在数据分析和数据挖掘在越来越多的行业里蔓延,因此数据分析和数据挖掘能力是现在从事数据类职业的基石。
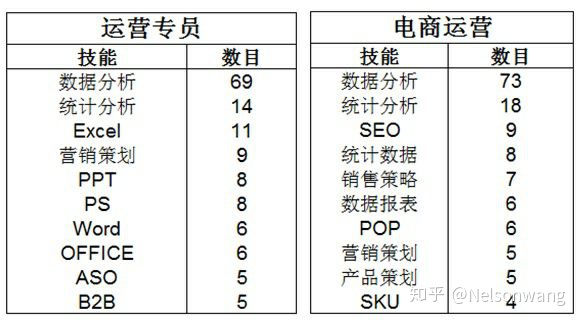
上图可知,运营类的运营专员和电商运营所需技能居榜首的依然是数据分析,并且遥遥领先,当然还需要其他的技能,但是都离不开分析能力,可见对数据的分析能力必不可少!
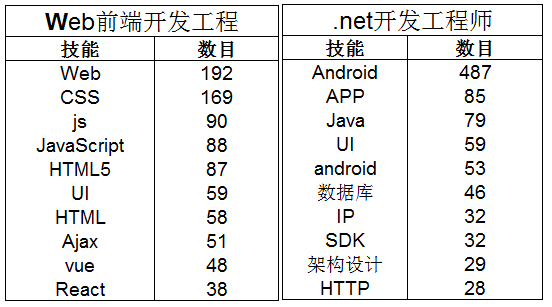
上表可知,网站开发的工程师就是Web前端和.net开发工程师二者缺一不可,这两个工程师所需的技能有所不同又互有关联,web前端开发顾名思义需要web和CSS这些知识,还有网页的结构与设计,net开发工程师则首先需要Android知识与技能,并且由表中看出这个技能在net开发工程师中是占着举足轻重的作用!很重要!
看完了10大热门数据类职位的技能,我们来分析一下数据类所有职位所需的最火技能TOP10,本组通过对字符串提取筛选统计,统计出如下表格:
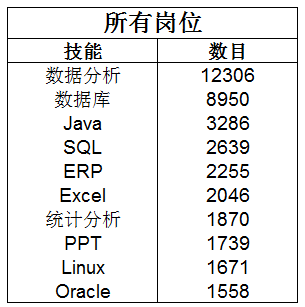

纵观所有岗位的最火技能TOP10,一目了然,稳居榜首的是数据分析,其次是数据库,接着是Java等编程语言、数据库和分析能力。不可否认,数据分析能力对于从事数据类职位至关重要!也就是从事数据类的职位就要学会如何分析数据和如何存储数据。
因此,有理由相信数据分析是当今时代必不可少的一项技能。
SUMMARY
经过这几天都学习,对Python的基础知识和多个数据分析库有了新的认识和应用,对这学期所学的知识也赋予了意义,利用Python做数据分析的确是一门不错的课程。在这次获取数据中常常出现的就是获取数据长度不一、单位不一、存在异常值、中文乱码、画图不标准等错误,但本组都已经处理完毕啦,处理数据的过程就是数据预处理,但是在后面的数据分析时还需要对数据进行筛选,也就是二次处理数据,一般来说第一次预处理数据会占比较多的时间,二次处理时就方便很多只需要把要分析的数据提出来再检查一遍数据是否合格即可,数据分析后就是数据可视化操作,数据可视化的目的是为了让数据以直观的形式展示。
经过这3天的挖掘前程无忧网站关于数据类的岗位相关信息,得出结论:
- 岗位的所需的技术高低决定了该岗位的薪资高低
- 个人的学历是基础,能力才是在岗位立足的根本
- 一线城市像上海、广州、深圳这些科技发达地区所需数据类人才较大,想要从事相关岗位可以考虑这些地区。
- 联网/电子商务、计算机软件、计算机服务这几个行业领域对数据类的人才需求最多。
- 数据分析和数据库在所有岗位技能中表现最突出,为必备技能。














 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









