





Lasso

《线性回归》中的一般线性回归模型
Y=*X
使用最小二乘估计(OLS)可以得到,模型的参数为:
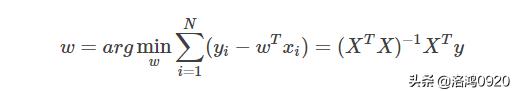
最小二乘估计虽然有不错的解析性,但是其在大多数情况下的数据分析能力是不够的,主要有两个原因:
预测精度问题:最小二乘法虽然是无偏估计,但是他的方差在自变量存在多重共线性(变量间线性相关)时会非常大,这个可以通过将某些系数压缩到0来改进预测精度,但这个是以一定的有偏为代价来降低预测值的方差。
模型的可解释性:自变量个数很多的时候,我们总是希望能够确定一个较小的变量模型来表现较好的结果
对于以上的问题,就有两种方法可以对最小二乘估计进行改进:子集选择lasso和脊回归。子集选择过程中,对变量要么保留,要么剔除,这很可能使得观测数据的一个微小变动就导致要选择一个新的模型,使得模型变得不稳定,但由于模型的变量少了,使得模型的解释性得到了提高;脊回归是一个连续的方法,它在不抛弃任何一个变量的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但这会使得模型的变量特别多,模型解释性差。
基于以上的问题,才有了现在要说的一种新的变量选择技术:Lasso(Least Absolute Shrinkage and Selection Operator)。这种方法使用模型系数的l1l1范数来压缩模型的系数,使得一些系数变小,甚至还是一些绝对值较小的系数直接变为0,这就使得这种方法同时具有了自己选择和脊回归的优点。
Lasso回归模型,是一个用于估计稀疏参数的线性模型,特别适用于参数数目缩减。基于这个原因,Lasso回归模型在压缩感知(compressed sensing)中应用的十分广泛。从数学上来说,Lasso是在线性模型上加上了一个l1l1正则项,其目标函数为:
















 6335
6335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









