







写在前面:关于权重和偏置更新

- 可以很明显看到,关于权重更新存在2种情况,本质没什么区别,只不过在自己写代码手动更新权重和偏置时,这点就很容易混淆出错。本帖第一个单层感知机示例,采用第一种方式;第二个BPN示例,采用第二种方式;
- 通常情况下,推荐采用第二种。因为一般数学推导中都是写成W=W-dW,这样就和以前的帖子一致<线性回归、逻辑回归与正则化>,避免以后自我矛盾
- 关于偏置b更新,一般没有数学公式。可以简单看做b=w0,因而不予额外讲述。在本帖第二个代码示例中,b的更新就是采用b=b-db形式。第一个示例中没有b,仅设置了W
- 我仔细翻看了以往的代码示例,以前的代码都是采用了TF自带的优化器,我们只需设置W和b占位符、赋予Y和Yhat相应值即可,其他的由优化器自我完成。至于设置loss时,对于函数逼近问题,到现在一直只用了平方差(Y-Yhat还是Yhat-Y不重要);对于分类问题,交叉熵求解的内部细节我们不参与,因此以前这个问题不突出。而此帖,error和权重、偏置更新都由自己手动撸码而成,因此顺序、加减问题就很明显
- 养成良好习惯,一律采用图示第二种方式
TensorFlow实现单层感知机详解
简单感知机是一个单层神经网络。它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题(线性可分的定义参见我的别的帖子)。虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了。当感知机使用阈值激活函数时,不能使用TensorFlow优化器来更新权重(根据上一帖可知,阈值激活函数并不可微,自然不能使用TF中定义的优化器,需要自己编写规则更新权重)。我们将不得不使用权重更新规则:
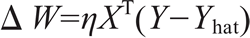
- 仔细研究下面程序,搞清楚为什么这个式子可以用来更新权重。(核心原因就是,Y-Yhat<0,即Yhat过大,则dW为负,W=W+dW变小,促使Yhat缩小;反之亦反)
- 研读这个程序和MNIST计算过程(mnist.data每一行是一个图片样本,shape(W)=(m,n)=(784,10), shape(B)=(n,1)=(10,1)),再结合神经元图,就可以很明晰一个结论:输入X中,每一行就是一个样本,X的行数M就是第零层输入层(虚拟节点)和第一层神经元的个数M,第一层中一个神经元用来承接一个样本。每个样本有m个输入的元素即[x1,x2...xm],相应和m个权重数wi相乘,故W有m行。若有n个输出,接着再和n个偏置数bi相加,故B有n行。
- 对于回归问题,只有一个输出n=1,故B常为一个数;对于分类问题,会有多个输出结果,如MNIST10个分类n=10,故B为n行1列。(注意为n行1列,而非1行n列,是因为加减法法则缘故,X*W所得大小(55000,10)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









