






~学习内容都是基于python3环境的,自己python编程基础不怎么样,所以也同步在补基础,不断添加解释,然后希望最后能够做得python小白也能看懂。
(资源主要来自阿里天池龙珠计划,公众号:AI蜗牛车)
基于鸢尾花(iris)数据集的逻辑回归分类实践
首先第一步,导入一些基础的函数库包括:numpy (Python中用于数值计算方面的软件包,不导入也可以,只是为了简便,比如可以少用很多for循环之类的),pandas(主要是表格方面数据分析和处理的软件包),matplotlib和seaborn(绘图的软件包)。
Step1:库函数导入
import numpy as np
import pandas as pd【注】np就是numpy库的缩写,pd同理。这两句就是通用写法,基本都是这样套路开头。
import matplotlib.pyplot as plt
import seaborn as sns【注】这里也是同样做法,导入绘图的库。
Step2:数据读取/载入
本次我们选择鸢尾花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
鸢尾花有四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。
| 变量 | 描述 |
|---|---|
| sepal length | 花萼长度(cm) |
| sepal width | 花萼宽度(cm) |
| petal length | 花瓣长度(cm) |
| petal width | 花瓣宽度(cm) |
| target | 鸢尾的三个亚属类别,山鸢尾'setosa'(0), 变色鸢尾'versicolor'(1), 维吉尼亚鸢尾'virginica'(2) |
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式【注】from sklearn.datasets import load_iris就是导入机器学习(sklearn)自带的鸢尾花(iris)数据。其他步骤就是## 的代码注释对应的意思。columns是列名称。
Step3:数据信息简单查看
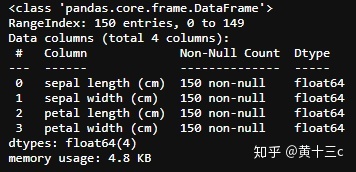
①利用.info()查看数据的整体信息
iris_features.info()【注】info()就是获取header的基本信息(维度、列名称、数据格式、所占空间等):,括号里可以填具体的数字。
输出结果:
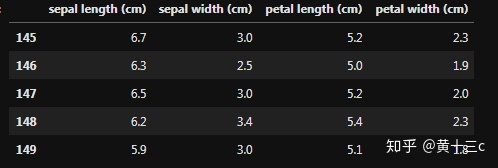
②进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部
iris_features.head()【注】head()就是会将excel数据表格中的第一行看作列名,并默认输出之后的五行,在head后面的括号填数字的话,就是输出对应的行数,比如2,12,80之类的。
输出结果:
iris_features.tail()【注】.head() 头部.tail()则代表尾部,倒着查看5个。
输出结果:
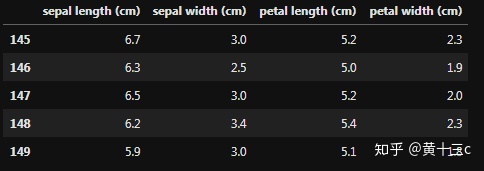
③查看目标值
iris_target输出结果:
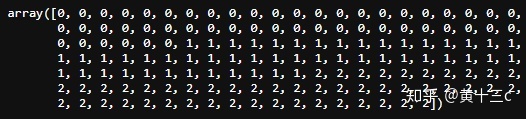
【注】其对应的类别标签为,其中0,1,2分别代表'setosa', 'versicolor', 'virginica'三种不同花的类别。即山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
④利用value_counts函数查看每个类别数量
pd.Series(iris_target).value_counts()【注】Pandas模块的数据结构主要有两种:1.Series 2.DataFrame。Series 是一维数组,基于Numpy的结构。value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
输出结果:
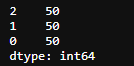
【注】结果就是即山鸢尾 (Iris-setosa)有50个,变色鸢尾(Iris-versicolor)有50个、维吉尼亚鸢尾(Iris-virginica)有50个。占内存64。
⑤对于特征进行一些统计描述。从统计描述中我们可以看到不同数值特征的变化范围。
iris_features.describe()输出结果:
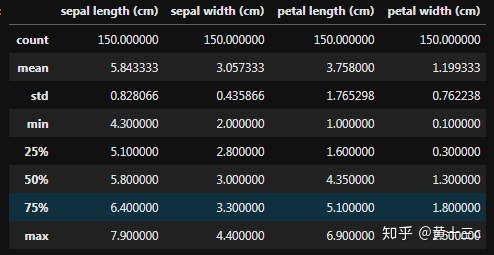
【注】从上到下依次表示:count总数,mean均值,std标准差,min最小值,25%, 50%和75%是对应的四分位,max最大值。
四分位数(Quartile)是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range,IQR)。
Step4:可视化描述
Step5:利用 逻辑回归模型 在二分类上 进行训练和预测
Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测
明天继续~














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









